
1.Director:マネージャーの上に社長を配置して疎らな報酬に挑む(1/2)まとめ
・強化学習はタスクがゴールに近づいている事を知るせるために報酬の設定が必要
・ゴールに近づいている事がはっきりしない迷路探索タスクなどでは報酬設定が困難
・タスクを管理しやすいサブタスクに自動で分解するDirectorの概念を導入した
2.階層型強化学習の問題点
以下、ai.googleblog.comより「Deep Hierarchical Planning from Pixels」の意訳です。元記事は2022年7月8日、Danijar Hafnerさんによる投稿です。
アイキャッチ画像のクレジットはPhoto by Keenan Barber on Unsplash
人工エージェントがどのように意思決定を行うかについての研究は、深層強化学習の進歩により急速に発展しています。GPT-3やImagenのような生成型MLモデルと比較して、人工エージェントは、カメラ入力に基づいてロボットアームを動かしたり、Webブラウザのボタンをクリックするなど、行動を通じて環境に直接影響を与えることができます。
人工エージェントは、ますます人々の役に立つ可能性を秘めていますが、現在の方法は、成功する戦略を学ぶために、報酬が頻繁に提供されるという形で詳細なフィードバックを受ける必要があるため、足かせになっています。例えば、AlphaGoのような強力なプログラムでも、多額の計算予算があるにもかかわらず、次の報酬を受け取るまでの数百手の先読みが限界となります。
一方、食事を作るような複雑なタスクでは、あらゆるレベルでの意思決定が必要となります。メニューの計画から、食材を取りに店まで移動、キッチンでのレシピに従った作業、高次元の感覚入力に基づく各ステップで必要な細かい運動技能の適切な実行などです。
階層型強化学習(HRL:Hierarchical reinforcement learning)は、このような複雑なタスクを管理可能なサブゴールに自動的に分解し、人工エージェントがより少ない報酬(疎らな報酬(sparse reward)とも呼ばれます)からより自律的にタスクを解決することを可能にすることが期待されています。しかし、HRLの研究は困難であることが分かっています。現在の方法は、目標空間やサブタスクを手動で指定することに依存しており、汎用的な解決策は存在しません。
この研究課題の進展に拍車をかけるため、私達はカリフォルニア大学バークレー校と共同で、生の画素から実用的、汎用的、かつ解釈可能な階層的動作を学習するDirectorエージェントを発表します。
Directorは、学習した世界モデルの潜在空間内でサブゴールを提案するmanagerポリシーを学習し、これらのゴールを達成するためにworkerポリシーを学習します。
潜在的な特徴表現で動作するにもかかわらず、私達はDirectorの内部ゴールを画像にデコードし、その決定を検査・解釈することができます。私達はDirectorを複数のベンチマークで評価し、Directorが多様な階層的戦略を学習し、一人称視点の画素入力から直接4脚ロボットの3D迷路を探索するなど、従来のアプローチでは失敗する非常に疎な報酬のタスクを解決できることを示します。

Director は、複雑な長期的課題を自動的にサブゴールに分解して解決することを学習します。各パネルは、左側が環境との相互作用、右側がデコードされた内部目標を示しています。
Directorの仕組み
Directorは画素から世界モデルを学習し、潜在的な空間における効率的なプランニングを可能にします。
世界モデルは、画像とモデル状態を対応付け、潜在的な行動から将来のモデル状態を予測します。予測されたモデル状態の軌跡から、Directorは2つの方針を最適化します。managerは一定のステップ数ごとに新しい目標を選択し、workerは低レベルの行動を通じて目標を達成することを学習します。しかし、世界モデルの高次元連続特徴表現空間で直接ゴールを選択することは、マネージャにとって困難な制御問題です。その代わりに、私達はゴールオートエンコーダを学習し、モデル状態をより小さな離散コードに圧縮します。そしてマネージャは離散コードを選択し、ゴールオートエンコーダはそれをモデル状態に変換した後、ゴールとしてworkerに渡します。
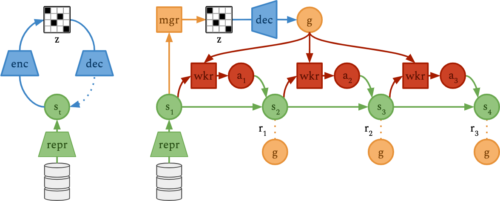
左:ゴールオートエンコーダ(青)は、世界モデル(緑)の状態(st)を離散的なコード(z)に圧縮します。
右:マネージャポリシー(橙)は、ゴールデコーダ(青)が特徴表現空間ゴール(g)に変換するコードを選択します。ワーカーポリシー(赤)は、世界モデルによって予測された将来の軌道(s1, …, s4)から、ゴールを達成するための学習を行います。
Director の全コンポーネントは同時に最適化されるので、managerはworkerが達成可能なゴールを選択するよう学習します。マネージャはタスク報酬と探索ボーナスの両方を最大化する目標を選択するよう学習し、エージェントが環境の遠隔地に向かって探索と操縦を行うように導きます。
私達は、ゴールオートエンコーダが高い予測誤差を生じるモデル状態を好むことが、シンプルで効果的な探索ボーナスであることを見出しました。Feudal Networksなどの先行手法とは異なり、私達のworkerはタスク報酬を受け取らず、現在のモデル状態とゴールとの間の特徴空間の類似性を最大化することから純粋に学習します。つまり、workerはタスクに関する知識を持たず、その代わりに目標達成に全能力を集中させます。
ベンチマーク結果
HRLの先行研究では、しばしばカスタム評価プロトコルに頼っていました
例えば、多様な練習用目標、2D地図上のエージェントのグローバルな位置へのアクセス、または、真実の距離報酬などを想定しています。
しかし、DirectorはエンドツーエンドのRL設定で動作します。
長期目線のタスクを探索し解決する能力をテストするために、私達は挑戦的なEgocentric Ant Mazeベンチマークを提案します。このベンチマークは、四足歩行ロボットの関節を制御し、自己認識と一人称カメラの入力のみで、3次元迷路のゴールを発見し到達することを要求します。報酬はロボットがゴールに到達したときに与えられるので、エージェントは学習のほとんどをタスク報酬がない状態で自律的に探索しなければなりません。

Egocentric Ant Mazeベンチマークは、迷路の終点にある疎な報酬を見つけるために、時間的に抽象的な方法で探索するエージェントの能力を測定するものです。
3.Director:マネージャーの上に社長を配置して疎らな酬に挑む(1/2)関連リンク
1)ai.googleblog.com
Deep Hierarchical Planning from Pixels
2)arxiv.org
Deep Hierarchical Planning from Pixels

