
1.機械学習を使ったWebアプリを5分で公開する方法まとめ
・多くのデータサイエンティストは、Jupyter Notebook以外の環境で仕事をすることができない
・モデルをWebアプリなどに展開/監視するために必要なスキルセットが軽視されているため
・本チュートリアルはJupyter Notebookからモデルを保存してWebで公開する方法を学習
2.Jupyter Notebookで作ったモデルをWebに公開する
以下、www.kdnuggets.comより「Build a Machine Learning Web App in 5 Minutes」の意訳です。元記事は2022年3月7日、Natassha Selvarajさんによる投稿です。
アイキャッチ画像のクレジットはPhoto by Christina on Unsplash
はじめに
この1年で、データ関連の職務は大幅に増加しました。データサイエンティストを目指す人の多くは、モデル構築に重点を置きがちで、データサイエンスのライフサイクルの他の要素にはあまり重点を置きません。
そのため、多くのデータサイエンティストは、Jupyter Notebook以外の環境で仕事をすることができないでいます。
そのため、モデルをエンドユーザーの手に届けることができず、外部のチームに頼っているのが現状です。データパイプラインが整備されていない中小企業では、これらのモデルが日の目を見ることはありません。なぜなら、モデルを展開・監視するために必要なスキルセットを持つ人材の雇用がおろそかになっているため、ビジネス価値を生み出すことができないからです。
この記事では、モデルをエクスポートして、Jupyter Notebook環境の外で使用する方法を学びます。ユーザーの入力を機械学習モデルに送り込み、出力予測をユーザーに表示することができる、簡単な Web アプリケーションを構築します。
このチュートリアルが終了するまでに、以下のことを学習します。
・分類問題を扱う機械学習モデルを構築し、調整する
・機械学習モデルをシリアライズしてファイルに保存する
・Jupyter Notebookの枠を越えて作業できるように、これらのモデルを異なる環境で読みこむ
・機械学習モデルからStreamlitを使用してWebアプリケーションを構築する
このWebアプリケーションは、ユーザーの人口統計学的指標と健康指標を入力として受け取り、今後10年間に心臓病を発症するかどうかの予測を生成します。
ステップ1:背景
Framingham Heart Studyは、マサチューセッツ州Framinghamの住民を対象とした長期にわたる心血管研究です。一連の臨床試験が患者集団に対して行われ、BMI、彼らの血圧、コレステロール値などの危険因子が記録されました。
これらの患者は、数年ごとに検査センターに報告し、最新の健康情報を提供しました。
このチュートリアルでは、Framingham Heart Studyのデータセットを用いて、この研究の患者が10年後に心臓病を発症するかどうかを予測します。これは、BioLinccのWebサイトからリクエストに応じて入手でき、約3600人の患者のリスクファクターから構成されています。
ステップ2: 前提条件
Pythonの統合開発環境がデバイスにインストールされている必要があります。Jupyter Notebookで作業することが多い場合は、他のIDEやテキストエディタをインストールしておいてください。今回はStreamlitを使ってWebアプリケーションを作成しますが、これはNotebookを使って実行することはできません。
Jupyterでモデルをビルドして保存するコードを書き出すことをお勧めします(Step 3とStep 4)。その後、別のIDEに切り替えてモデルをロードし、アプリケーションを実行します(Step 5)。
もしIDEをまだインストールしていないなら、以下の中から選ぶことができます:Visual Studio Code, Pycharm, Atom, Eclipse.
ステップ3:モデルの構築
データセットを必ずダウンロードしてください。そして、Pandasライブラリをインポートし、データフレームをロードします。
import pandas as pd
framingham = pd.read_csv('framingham.csv')# Dropping null values
framingham = framingham.dropna()
framingham.head()

データフレームの先頭を見てみると、15個のリスクファクターがあることに気づきます。これらは独立変数で、10年後の心臓病の発症(TenYearCHD)を予測するために使用します。
さて、私達のターゲット変数を見てみましょう。
framingham['TenYearCHD'].value_counts()
この列には0と1の2つの値しかないことに注意してください。0の値は、患者が10年間にCHDを発症しなかったことを示し、1の値は、発症したことを示します。
このデータセットもかなりアンバランスです。0の結果を持つ患者が3101人で、1の結果を持つ患者は557人だけです。
私達のモデルが不均衡なデータセットで訓練されので、常に1を予測しないことを保証するために、私達は訓練データに対してランダムオーバーサンプリングを実行します。そして、ランダム・フォレスト分類器をデータフレーム内のすべての変数に適合させます。
from sklearn.model_selection import train_test_split
from imblearn.over_sampling import RandomOverSampler
from sklearn.ensemble import RandomForestClassifier
from sklearn.pipeline import Pipeline
from sklearn.metrics import accuracy_scoreX = framingham.drop('TenYearCHD',axis=1)
y = framingham['TenYearCHD']
X_train, X_test, y_train, y_test = train_test_split(X,y,test_size=0.20)oversample = RandomOverSampler(sampling_strategy='minority')
X_over, y_over = oversample.fit_resample(X_train,y_train)rf = RandomForestClassifier()
rf.fit(X_over,y_over)
では、テストセットでモデルの性能を評価してみましょう。
preds = rf.predict(X_test) print(accuracy_score(y_test,preds))
このモデルの最終的な精度は約0.85です。
ステップ4:モデルの保存
先ほど構築したランダムフォレスト分類器を保存しましょう。この作業には Joblib ライブラリを使用しますので、インストールされていることを確認してください。
import joblib joblib.dump(rf, 'fhs_rf_model.pkl')
このモデルは、異なる環境でも容易にアクセスでき、外部データに対する予測に利用することができます。
ステップ5:Webアプリの構築
a) ユーザーインターフェースの作成
最後に、上記で作成したモデルを使ってWebアプリケーションの構築を開始します。始める前に、Streamlitライブラリがインストールされていることを確認してください。
Jupyter Notebookを使用して分類器を構築していた場合は、別のPython IDEに移行する必要があります。streamlit_fhs.pyという名前のファイルを作成します。
ディレクトリには、以下のファイルが含まれているはずです。
次に、.py ファイルで以下のライブラリをインポートします。
import streamlit as st import joblib import pandas as pd
Webアプリケーションのヘッダーを作成し、実行してみて、すべてがうまくいっているかどうかを確認してみましょう。
st.write("# 10 Year Heart Disease Prediction")
Streamlitアプリを実行するには、ターミナルに次のコマンドを入力します。
streamlit run streamlit_fhs.py
さて、あなたのアプリが存在する http://localhost:8501 に移動してください。このようなページが表示されるはずです。

素晴らしい!これで、すべてがうまくいったことになります。
では、ユーザーが自分のデータ(年齢、性別、BPなど)を入力するための入力ボックスを作りましょう。
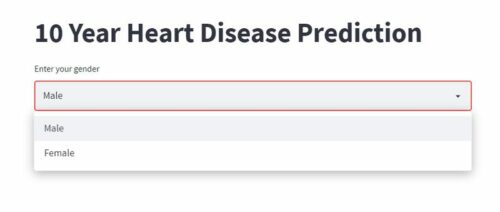
ここでは、ユーザーが自分の性別を選択するための複数選択肢のドロップダウンを Streamlit で作成する方法を説明します(これはサンプルコードです。実行したらこの行を削除してください。完全な例は下部にあります)。
gender = st.selectbox("Enter your gender",["Male", "Female"])
Streamlitアプリに再度アクセスし、ページを更新してください。このドロップダウン・ボックスが画面に表示されることを確認します。
ユーザから収集する必要のある独立変数が15個あることを思い出してください。
次のコード行を実行して、ユーザーがデータを入力するための入力ボックスを作成します。アプリをより見やすくするために、ページを 3 列に分割します。
col1, col2, col3 = st.columns(3)
# getting user input
gender = col1.selectbox("Enter your gender",["Male", "Female"])
age = col2.number_input("Enter your age")
education = col3.selectbox("Highest academic qualification",["High school diploma", "Undergraduate degree", "Postgraduate degree", "PhD"])
isSmoker = col1.selectbox("Are you currently a smoker?",["Yes","No"])
yearsSmoking = col2.number_input("Number of daily cigarettes")
BPMeds = col3.selectbox("Are you currently on BP medication?",["Yes","No"])
stroke = col1.selectbox("Have you ever experienced a stroke?",["Yes","No"])
hyp = col2.selectbox("Do you have hypertension?",["Yes","No"])
diabetes = col3.selectbox("Do you have diabetes?",["Yes","No"])
chol = col1.number_input("Enter your cholesterol level")
sys_bp = col2.number_input("Enter your systolic blood pressure")
dia_bp = col3.number_input("Enter your diastolic blood pressure")
bmi = col1.number_input("Enter your BMI")
heart_rate = col2.number_input("Enter your resting heart rate")
glucose = col3.number_input("Enter your glucose level")
変更を反映するには、アプリを再度更新してください。

最後に、ページの一番下に「Predict」ボタンを追加する必要があります。ユーザーがこのボタンをクリックすると、出力が表示されます。
st.button('Predict')
素晴らしい!
ページを再度更新すると、このボタンが表示されます。
b) 予測を行う
アプリのインターフェイスは完成しました。あとは、システムに入力された際にユーザーの入力を収集するだけです。このデータを分類器に渡して、出力を予測する必要があります。
ユーザーの入力は、上で作成した変数(年齢、性別、教育など)に格納されています。
しかし、この入力は分類器に簡単に取り込まれるような形式ではありません。我々はYes/Noの質問形式で文字列を収集しているので、学習データと同じ方法でエンコードする必要があります。
以下のコードを実行して、ユーザ入力データを変換してください。
df_pred = pd.DataFrame([[gender,age,education,isSmoker,yearsSmoking,BPMeds,stroke,hyp,diabetes,chol,sys_bp,dia_bp,bmi,heart_rate,glucose]], columns= ['gender','age','education','currentSmoker','cigsPerDay','BPMeds','prevalentStroke','prevalentHyp','diabetes','totChol','sysBP','diaBP','BMI','heartRate','glucose']) df_pred['gender'] = df_pred['gender'].apply(lambda x: 1 if x == 'Male' else 0) df_pred['prevalentHyp'] = df_pred['prevalentHyp'].apply(lambda x: 1 if x == 'Yes' else 0) df_pred['prevalentStroke'] = df_pred['prevalentStroke'].apply(lambda x: 1 if x == 'Yes' else 0) df_pred['diabetes'] = df_pred['diabetes'].apply(lambda x: 1 if x == 'Yes' else 0) df_pred['BPMeds'] = df_pred['BPMeds'].apply(lambda x: 1 if x == 'Yes' else 0) df_pred['currentSmoker'] = df_pred['currentSmoker'].apply(lambda x: 1 if x == 'Yes' else 0)def transform(data): result = 3 if(data=='High school diploma'): result = 0 elif(data=='Undergraduate degree'): result = 1 elif(data=='Postgraduate degree'): result = 2 return(result)df_pred['education'] = df_pred['education'].apply(transform)
先ほど保存したモデルを読み込んで、ユーザーが入力した値に対して予測を行うために使用すればよいのです。
model = joblib.load('fhs_rf_model.pkl')
prediction = model.predict(df_pred)
最後に、これらの予測を画面上に表示する必要があります。
先ほど予測ボタンを作成したコードの行に移動し、以下のように修正します。
if st.button('Predict'):
if(prediction[0]==0):
st.write('<p class="big-font">You likely will not develop heart disease in 10 years.</p>',unsafe_allow_html=True)
else:
st.write('<p class="big-font">You are likely to develop heart disease in 10 years.</p>',unsafe_allow_html=True)
これらの変更は、ユーザーが Predict ボタンをクリックしたときにのみ、出力が表示されるように追加されました。また、ユーザーに予測値 (0 と 1) を表示するだけでなく、テキストを表示するようにします。
すべてのコードを保存して、ページを更新すると、画面に完成したアプリケーションが表示されます。ランダムな入力数字を追加し、Predictボタンをクリックして、すべてがうまくいくことを確認してください。
チュートリアルを最後まで読んでくださった方、おめでとうございます。あなたは Streamlit を使って、エンドユーザと対話できる ML ウェブアプリケーションを作ることに成功しました。
次のステップとして、アプリケーションをデプロイして、インターネット上の誰もがアクセスできるようにすることを検討してみてください。これは、Heroku、GCP、AWSのようなツールを使って行うことができます。
著者のNatassha Selvarajは、独学で学んだデータサイエンティストで、書くことに情熱を注いでいます。LinkedInで彼女とつながることができます。
3.機械学習を使ったWebアプリを5分で公開する方法関連リンク
1)www.kdnuggets.com
Build a Machine Learning Web App in 5 Minutes
2)github.com
Natassha / fhs_model

