
1.Teaching BERT to Wait:「え~」や「あ~」を識別して言語モデルのパフォーマンスを向上(2/2)
・スマホの音声の自動書き起こしアプリなどでも非流暢性の除去は読みやすさ向上に貢献
・リアルタイムに発生するストリーミングデータは時間依存性があるため処理が難しかった
・次のトークンを待つべきか否かを判断する処理を入れる事で性能向上と待ち時間短縮を達成
2.即時性が求められる際の待ち判断の重要性
以下、ai.googleblog.comより「Identifying Disfluencies in Natural Speech」の意訳です。元記事は2022年6月30日、Dan WalkerさんとDan Lieblingさんによる投稿です。
アイキャッチ画像のクレジットはPhoto by Dorrell Tibbs on Unsplash
ストリーミング
自動音声転記の最新の使用例には、Androidの「Live Captions」機能による音声の自動書き起こしがあります。このような環境において、キャプションの読みやすさを向上させるために、非流暢性の除去が迅速に、かつ安定的に行われる必要があります。つまり、転記された文中に新しい単語があっても、モデルは過去の予測を頻繁に変更して画面をチラつかせないようにしなければなりません。
私たちはこれをトークンバイトークンのライブ処理ストリーミングと呼んでいます。正確なストリーミングは時間依存性があるため難しく、ほとんどの曖昧さは後からしか認識できません。たとえば、繰り返しは、その単語やフレーズが2回目に言われるまで、実際に繰り返しになることはありません。
ストリーミングアプリケーションで私達の非流暢性検出モデルが有効かどうかを調べるために、私達は訓練セットの発話をプレフィックスセグメントに分割し、訓練時に発話の最初のNトークンだけを提供し、発話の全長までのすべての値のNを提供しました。
また、ストリーミング F1、検出時間(TTD)、編集オーバヘッド(EO)、平均待ち時間(AWT)など、モデルの精度、安定性、待ち時間を表すいくつかの指標で性能を評価しました。私たちは、1つまたは2つのトークンの先読みウィンドウを実験し、モデルが予測を行う必要のない追加のトークンを「覗き見」できるようにしました。要するに、意思決定をする前に、あと1~2トークン分の証拠を「待つ」ようにモデルに要求しているのです。
この固定的な先読みを追加することで、多くの文脈で安定性とストリーミングF1スコアが向上しましたが、場合によっては、次のトークンを先読みしなくてもラベルがすでに明確で、モデルが待つことで必ずしも利益を得るわけではないことが判明しました。また、1トークンだけ余分に待つことで十分な場合もありました。そこで、我々は、モデル自身が、より多くの文脈を待つべきタイミングを学習することができると仮定しました。私たちのソリューションは、「待ち」分類ヘッドを含む修正されたモデルアーキテクチャで、この分類ヘッドは、モデルの非流暢性分類ヘッドが信頼するに足る証拠を既に得たか、待つべきかを決定します。
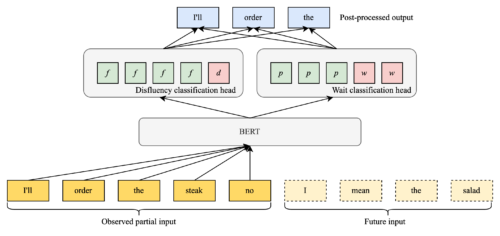
モデルが入力トークンを到着時にラベル付けする方法を示す図
BERTembeddingレイヤーは、2つの別々の分類ヘッドに供給され、それらが組み合わされて出力されます。
私達は3つの要素の加重和である学習損失関数を構築しました。
・非流暢性分類のための伝統的なクロスエントロピー損失
・最初のトークンが「待ち」か否かの分類しか考慮しないクロスエントロピー項
・予測に要する時間が長すぎないようにするための遅延ペナルティ
このストリーミングモデルを、先読みなしの標準ベースラインと、1トークンと2トークンの先読みモデルの両方で評価しました。
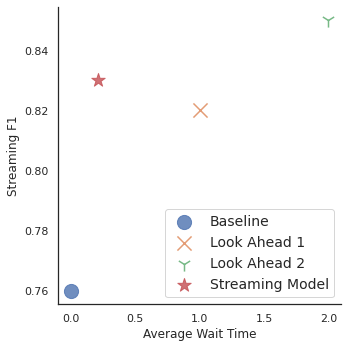
ストリーミングF1スコアと平均待ち時間のグラフ(トークン単位)
3つのデータポイントは、複数の待ち時間でF1スコアが0.82を超えていることを示しています。提案するストリーミングモデルは、固定先読みモデルよりもはるかに短い待ち時間で、トップに近い性能を達成することができます。
ストリーミングモデルは、先読みなしの標準ベースラインと先読み 1 のモデルの両方よりも優れたストリーミング F1 スコアを達成し、先読み 2 の固定モデルとほぼ同等の性能を示しましたが、待ち時間は大幅に減少しました、このモデルは平均して0.21トークンしか文脈を待ちませんでした。
国際化
これまでのところ、私たちは英語の会話を転記した筆記録で最高の結果を得ています。英語には非流暢な文を含む比較的大きなラベル付き会話データセットが多数ありますが、他の言語にはそのようなデータセットがほとんどないのです。そのため、英語以外の言語でも非流暢性検出モデルを利用できるようにするためには、各ターゲット言語において何十万もの発話を検索しラベル付けする必要がない方法でモデルを構築する方法が必要です。
BERTの多言語版を利用して、英語の非流暢性に関して学習したモデルを他の言語に転送し、より少ないデータで同様の性能を達成することが、有望な解決策となります。これは活発な研究分野ですが、ここでいくつかの有望な結果を概説します。
このアプローチを検証するための最初の取り組みとして、ドイツ語のCALLHOMEデータセットから約10,000行の対話にラベルを追加しました。
次に、Geotrendの英語とドイツ語のバイリンガルBERTモデル(Multilingual BERTから抽出)から始め、Fisherコーパスから約77,000例の流暢性欠如ラベル付き英語のSwitchboard とFisherコーパスから130万サンプルの自己ラベル付き筆記録を使って微調整を行いました。
さらに、ドイツ語のCALLHOMEデータセットから自社内でラベル付けした約7,500サンプルを用いて、さらなる微調整を行いました。
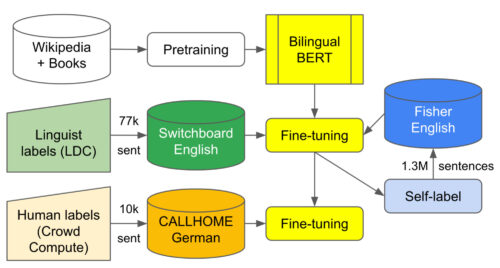
最適な多言語学習環境におけるラベル付きデータと自己学習出力のフローを示す図。英語とドイツ語のデータで学習することで、転移学習による性能向上が期待できます。
その結果、大規模な英語コーパスを用いて微調整を行えば、ドイツ語のような類似言語へのゼロショット転移により許容できる精度が得られますが、リコールを60%未満から80%以上に改善するには、少なくとも適度な量のドイツ語ラベルが必要であることが示されました。英語とドイツ語の2言語モデルで2段階の微調整を行ったところ、最高の精度と総合F1スコアが得られた。
| Approach | Precision | Recall | F1 |
| German BERTBASE model fine-tuned on 7,300 human-labeled German CALLHOME examples | 89.10% | 81.30% | 85 |
| Same as above but with additional 7,500 self-labeled German CALLHOME examples | 91.50% | 83.30% | 87.2 |
| English/German Bilingual BERTbase model fine-tuned on English Switchboard+Fisher, evaluated on German CALLHOME (zero-shot language transfer) | 87.20% | 59.10% | 70.4 |
| Same as above but subsequently fine-tuned with 14,800 German CALLHOME (human- and self-labeled) examples | 95.50% | 82.60% | 88.6 |
結論
筆記録から流暢でない部分を削除することは、人々にとって読みやすいだけでなく、筆記録を学習用データとして消費する他のモデルのパフォーマンスも向上させることができます。本稿では、非流暢性解消の効果的な方法を示し、リソースに制約のある環境、新しい言語、よりインタラクティブなユースケースに非流暢性解消モデルを拡張します。
謝辞
コードを書き、実験を行い、ここで取り上げた論文をまとめてくれたVicky Zayats, Johann Rocholl, Angelica Chen, Noah Murad, Dirk Padfield そして Preeti Mohanに感謝します。
また、追加のデータラベルの取得をサポートしてくれたテクニカルプロダクトマネージャーのAaron Schneider、Cerebra Data OpsチームのBobby Tran、Speech Data OpsのChetan Guptaに感謝します。
3.Teaching BERT to Wait:「え~」や「あ~」を識別して言語モデルのパフォーマンスを向上(2/2)関連リンク
1)ai.googleblog.com
Identifying Disfluencies in Natural Speech
2)arxiv.org
Teaching BERT to Wait: Balancing Accuracy and Latency for Streaming Disfluency Detection

