
1.LabelDP:秘匿対象をラベルに限定する事で差分プライバシーの精度を向上(2/2)まとめ
・RR-with-priorは事前確率を使う事で予測の精度を大幅に増加させる
・経験的実験でもLabelDPがモデルの実用性を大幅に向上させる事が確かめられた
・数学的にもラベルのみをプライベート化するアルゴリズムはサンプル複雑度が低い
2.LabelDPの性能
以下、ai.googleblog.comより「Deep Learning with Label Differential Privacy」の意訳です。元記事は2022年5月25日、Pasin ManurangsiさんとChiyuan Zhangさんによる投稿です。
アイキャッチ画像のクレジットはDALL·E Mini(Mega)
下図は、RR-with-prior の動作を説明するものです。
入力画像を10のカテゴリに分類するモデルを構築するとしましょう。ラベル「airplane 」を持つ学習サンプルを考えます。
LabelDPを保証するために、古典的なRandomized Response(RR)は与えられた分布に従ってサンプリングされたランダムなラベルを返します(下図の右上のパネルを参照してください)。
目標とするプライバシー予算εが小さいほど、誤ったラベルをサンプリングする確率は大きくならざるを得ません。
ここで、与えられた入力が「空を飛ぶ物体である可能性が高い」ことを示す事前確率があるとします。(左下図)事前確率があれば、RR-with-priorは事前確率の小さいラベルをすべて捨て、残りのラベルからだけサンプリングします。これらの可能性の低いラベルを捨てることで、同じプライバシー予算εを維持したまま、正しいラベルを返す確率が大幅に増加します。(右下図)
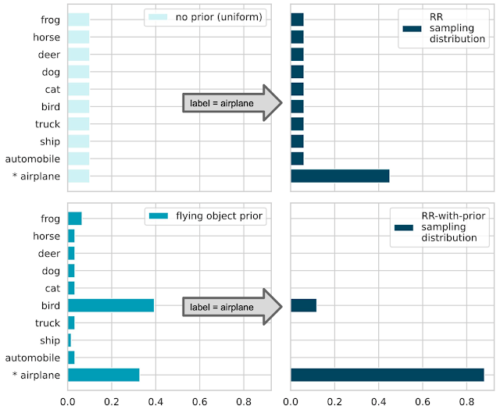
ランダム回答法(RR:Randomized Response):事前情報がない場合(左上)、すべてのクラスが等確率でサンプリングされます。プライバシー予算が高いほど、真のクラスをサンプリングする確率(P[airplane] ≈ 0.5)が高くなります。(右上)
RR-with-prior:事前分布を仮定し(左下)、ありえないクラスはサンプリング分布から「抑制」されます。(右下)そのため、同じプライバシー予算であれば、真のクラスをサンプリングする確率(P[airplane] ≒ 0.9)が高くなります。
多段階学習アルゴリズム
RR-with-priorの観測に基づき、LabelDPを用いたディープニューラルネットワークの多段階学習アルゴリズムを導入します。
まず、学習セットはランダムに複数のサブセットに分割されます。そして、古典的なRRを用いて、最初のサブセットに対して初期モデルが学習されます。最後に、このアルゴリズムはデータを複数のパートに分割し、各段階で単一のパートを使用してモデルを学習します。ラベルはRR-with-priorを用いて生成され、priorはこれまでに学習されたモデルの予測に基づくものです。
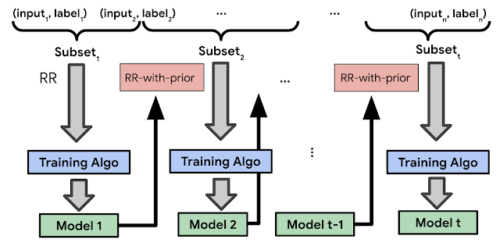
多段階学習アルゴリズムの説明図
学習セットはt個の不連続な部分集合に分割されます。最初のサブセットに対して、古典的なRR法を用いて、初期モデルが学習されます。そして、学習済モデルは、RR-with-prior ステップおよび後の段階の学習において、事前予測を提供するために使用されます。
結果
複数のデータセット、領域、モデル設計において、多段階学習アルゴリズムの経験的性能を評価しました。
CIFAR-10を使ったマルチクラス分類タスクにおいて、プライバシー予算εが同じ場合、LabelDPを保証する多段学習アルゴリズム(下図青色)はDP-SGDよりも20%高い精度を達成しました。
ただし、LabelDPはラベルのみを保護し、DP-SGDは入力とラベルの両方を保護するため、厳密には公平な比較とは言えません。しかし、この結果は、ラベルのみを保護する必要がある特定のアプリケーションシナリオにおいて、LabelDPがモデルの実用性を大幅に向上させ、プライベートモデルと公開モデルとの性能差を縮める可能性があることを実証しています。
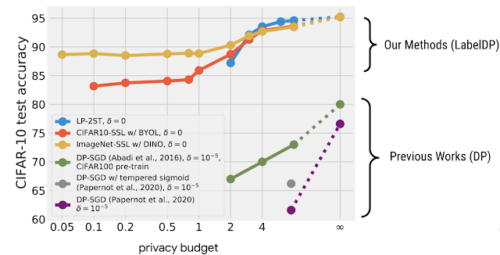
異なるプライバシー予算の下での、異なるアルゴリズムのモデルユーティリティ(テスト精度)の比較。
領域によっては、事前知識が自然に利用可能であったり、公開されているデータのみを用いて構築可能であったりすることがあります。
例えば、多くの機械学習システムは過去のモデルを持ち、それを新しいデータで評価することでラベルの事前分布を提供することができます。
教師なし学習や自己教師あり学習が有効な領域では、ラベルのない(したがってLabelDPの観点から考えると公開されている)データで事前に学習したモデルから事前知識を構築することも可能です。
具体的には、CIFAR-10の評価において、2つの自己教師付き学習アルゴリズムを実証しています。(上図のオレンジと緑の軌跡)自己教師付き学習モデルを用いて学習サンプルに対する特徴表現を計算し、その特徴表現に対してk-meansクラスタリングを実行します。そして、わずかなプライバシー予算(ε≤0.05)を使って、各クラスタのラベル分布のヒストグラムを照会し、それを各クラスタの点のラベル事前分布として使用します。この事前設定は、低プライバシーバジェット領域(ε < 1)において、モデルの実用性を著しく向上させます。
同様の結果は、MNIST、Fashion-MNIST、MovieLens-1M映画評価タスクのような非視覚領域など、複数のデータセットで得られています。実証結果の完全な報告については、私達の論文をご覧ください。
実証結果は、ラベルのプライバシーを保護することは、入力とラベルの両方のプライバシーを保護することよりも著しく容易であることを示唆しています。また、このことは特定の設定の下で数学的に証明することができます。特に、凸型確率最適化において、ラベルをプライベート化するアルゴリズムのサンプル複雑度は、ラベルと入力の両方をプライベート化するアルゴリズムのサンプル複雑度よりはるかに小さいことを示すことができます。つまり、同じプライバシー予算で同じレベルのモデル効用を得るためには、LabelDPの方がより少ない学習サンプルで済むのです。
まとめ
LabelDPが完全DP保証の有望な緩和策であることを、経験的・理論的な結果の両方から実証することができました。入力情報のプライバシーを保護する必要がないアプリケーションでは、LabelDPは「プライベートを考慮するモデル」と「プライベートを考慮しないモデル」の間の性能差を縮めることができます。
今後の課題として、多クラス分類以外のタスクに対しても、より優れたLabelDPアルゴリズムを設計する予定です。今回の多段階学習アルゴリズムコードの公開が、差分プライバシー(DP:Differential Privacy)研究のための有用なリソースを研究者に提供することを期待しています。
謝辞
この研究は、Badih Ghazi、Noah Golowich、Ravi Kumarとの共同作業により行われました。また、私達の研究に対して貴重なフィードバックをくれたSami Torbeyに感謝します。
3.LabelDP:秘匿対象をラベルに限定する事で差分プライバシーの精度を向上(2/2)関連リンク
1)ai.googleblog.com
Deep Learning with Label Differential Privacy
2)arxiv.org
Deep Learning with Label Differential Privacy
3)github.com
google-research / label-dp

