
1.Alpa:わずか1行でJAXニューラルネットワークを並列化(1/2)まとめ
・データ並列を行うと複数アクセラレータで並列処理できるのでモデルの規模拡大が可能
・しかし、最近の大規模モデルはデータ並列では間に合わずモデル並列処理が必要になる
・モデル並列化は複雑なプロセスだがAlpaは自動でモデル並列化を行う事ができる
2.Alpaとは?
以下、ai.googleblog.comより「Alpa: Automated Model-Parallel Deep Learning」の意訳です。元記事は2022年5月3日、Zhuohan LiさんとYu Emma Wangさんによる投稿です。
Alpaは何の略かわからなかったのですが、arpaがスペイン語でハープの意味で並列っぽいイメージも感じたので、そこから取ったアイキャッチ画像のクレジットはPhoto by Sergio Capuzzimati on Unsplash
ここ数年、ディープラーニングモデルの規模が急速に拡大し、単一アクセラレータのメモリ容量をあっという間に超えてしまいました。BERT(パラメータサイズ1GB未満)のような初期のモデルは、学習データを分割して分散させるだけで、モデルの重みをアクセラレータ間で重複させるデータ並列(data parallelism)を活用することで、アクセラレータ間で効率的に規模拡大させることができます。
しかし、GPT-3(パラメータサイズ175GB)のような最近の大規模モデルは、1つのモデルを異なるデバイスに分割するモデル並列(model parallelism)トレーニングによってのみ規模拡大することができます。
モデル並列化戦略は大規模なモデルの学習を可能にする一方で、対象となるニューラルネットワークや計算機クラスタに合わせて特別に設計する必要があり、より複雑なものとなっています。例えば、Megatron-LMでは、モデル並列化戦略を用いて重み行列を行または列で分割し、デバイス間で結果を同期させています。
デバイス配置最適化(Device Placement Optimization)やパイプライン並列(pipeline parallelism)では、ニューラルネットワークの異なる演算を複数のグループに分割し、入力データをマイクロバッチに分割し、パイプラインで実行しています。
モデル並列処理では、特定のモデルに対して最適な並列化プランを特定するために、システムの専門家が多大な労力を必要とすることがよくあります。しかし、機械学習(ML:Machine Learning)の研究者の多くは、モデルの実行を第一に考え、モデルの性能は二の次にしているため、このような作業は負担が大きすぎます。そのため、大規模なモデルにも容易に適用できるように、モデルの並列化を自動化する良い機会が残っています。
OSDI 2022で発表された論文「Alpa: Automating Inter- and Intra-Operator Parallelism for Distributed Deep Learning」Amazon Web Services、カリフォルニア大学バークレー校、上海交通大学、デューク大学、カーネギーメロン大学の研究者と緊密に協力して開発した、モデルの並列化という複雑なプロセスを自動化する方法について述べています。
私たちは、Alpaがたった1行のコードで、あらゆるJAXニューラルネットワークを、ユーザーが提供するデバイスクラスタ上で実行可能な最適な並列化戦略を持つ分散バージョンに変換できることを実証しています。また、Alpaのコードをオープンソースとして公開し、より広範な研究者に提供することを発表できることを嬉しく思います。
Alpaの設計
まず、既存のML並列化手法を演算間並列(inter-operator)と演算内並列(intra-operator)の2つに分類することから始めます。
演算間並列では、異なるデバイスに異なる演算子を割り当て(デバイス配置最適化など)、パイプラインの実行スケジュール(パイプライン並列など)を更に工夫して加速することが多いです。
演算内並列には、データ並列(Deepspeed-Zeroなど)、演算並列(Megatron-LMなど)、エキスパート並列(GShard-MoEなど)があり、個々の演算を複数の装置に分割して実行し、装置間で結果を同期させるために集合通信が使われることが多いです。
この2つの手法の違いは、典型的な計算機クラスタの構成が異なっている事に対応します。
演算間並列処理では、異なるアクセラレータの演算間で演算を伝達するだけなので、必要な通信帯域幅は小さくなります。しかし、パイプラインのデータ依存性、つまり、ある演算は他の演算からの出力を待っている間、非アクティブになるため、デバイスの利用率が低下します。
一方、演算内並列処理では、データ依存性の問題はありませんが、デバイス間の通信をより多く行う必要があります。GPUクラスタは、ノード内のGPUは広い通信帯域を持つため、演算内並列で処理する事ができます。しかし、異なるノードに装着されているGPUは、イーサネットなどの低帯域幅で接続されていることが多いため、演算間並列が好まれます。
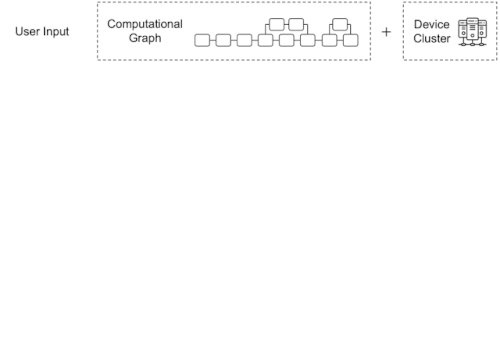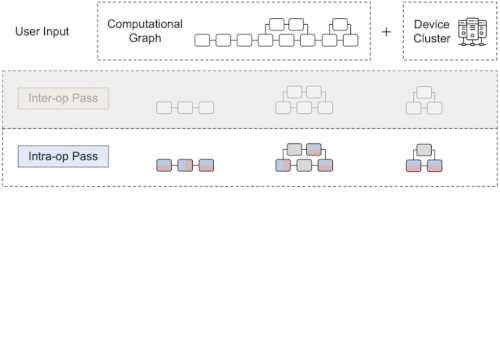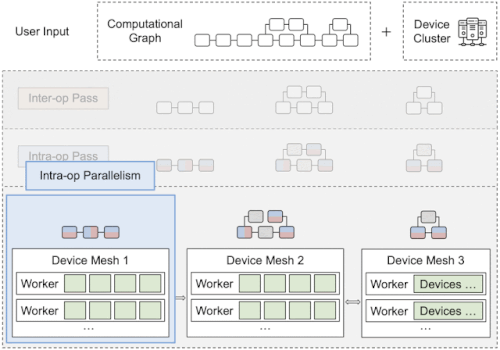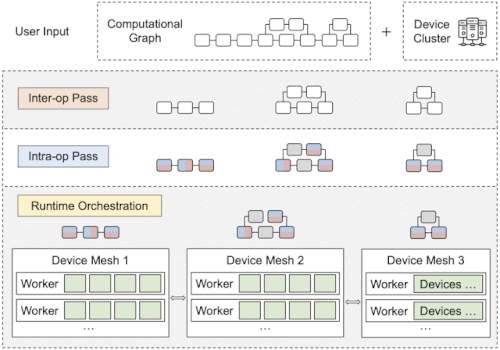
Alpaの概要
1つのグラフを3つに分割したサブグラフで、赤と青は分割された演算、グレーは複製された演算を表します。緑は実際のデバイス(GPUなど)を表しています。
3.Alpa:わずか1行でJAXニューラルネットワークを並列化(1/2)関連リンク
1)ai.googleblog.com
Alpa: Automated Model-Parallel Deep Learning
2)arxiv.org
Alpa: Automating Inter- and Intra-Operator Parallelism for Distributed Deep Learning
3)github.com
alpa-projects / alpa

