
1.VFS:強化学習で長期目線が必要な行動を実現(2/2)まとめ
・各遷移に影響を与えその結果を予測するために必要な機能情報はVFS特徴表現内にある
・原理的には高レベルのエージェントがすべてのスキルを連鎖させる事が可能になる
・VFSは風景内のスキル中心の特徴表現を学習するため、タスクと無関係な変動に堅牢性
2.VFSの性能
以下、ai.googleblog.comより「Extracting Skill-Centric State Abstractions from Value Functions」の意訳です。元記事は2022年4月29日、Dhruv ShahさんとBrian Ichterさんによる投稿です。
アイキャッチ画像のクレジットはPhoto by 張 峻嘉 on Unsplash
先に述べたテーブル配置換えタスクの簡単の例で、青い物体を引き出しに入れるというタスクを考えてみましょう。この環境では、8つの基本動作があります。
右の棒グラフは任意の時間における各スキルの値を示し、下のグラフはタスクの進行に伴うこれらの値の変化を示しています。

各スキルに対応する価値関数(右上、下は集約)は、風景(左上)内の機能情報を取得し、意思決定を支援します。
最初は、すでにカウンターの上に物があるため、「カウンターに置く」スキルに対応する値が高く、同様に「引き出しを閉める」スキルに対応する値も高くなります。
軌跡の中で、ロボットが青い立方体を手にしたとき、対応するスキルの値がピークに達します。同様に、「引き出しに入れる」は、引き出しが開いているときに値が大きくなり、青い立方体を入れたときに値が大きくなります。
このように、各遷移に影響を与え、その結果(成否)を予測するために必要な機能情報はすべてVFS特徴表現に取り込まれており、原理的には高レベルのエージェントがすべてのスキルを推論し、それらを連鎖させて、観測結果を効果的に表現することができます。
また、VFSは風景内のスキル中心の特徴表現を学習するため、背景の紛らわしい物体やタスクと無関係な風景の出現などの外生的な変動要因に対して堅牢性があります。
以下に示すすべての構成は、青い立方体が入った開いた引き出し、カウンター上の赤い立方体、空のグリッパーと機能的に同等であり、見かけ上の違いはあっても、同じように操作することができます。

学習されたVFS特徴表現は、腕の姿勢、散乱物(緑の立方体)、背景の様子(茶色の机)などのタスクと無関係な要因を無視することができます。
VFSによるロボット操作
このアプローチにより、VFSは複雑なロボット操作のタスクを計画することができます。
例えば、単純なモデルベース強化学習(MBRL:Model-Based Reinforcement Learning)アルゴリズムでは、価値関数空間における遷移を単純な1ステップ予測モデルで行います。そして、モデルの予測制御と同様に、スキル適用順の候補をランダムにサンプリングし、最適なものを選択・実行します。
「物体Aを物体Bの近くに移動させる」を形作る基本的な押すスキルの集合と、高レベルの再配置タスクが与えられたとき、VFSはMBRLを用いて高レベルのタスクを解決するスキル適用順を確実に見つけることができました。
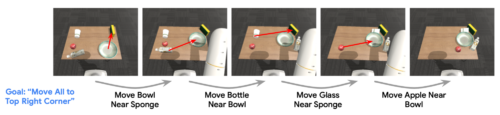
ロボットアームを用いてテーブル上の配置を変更するタスクを実行するVFSの運用
VFSは、低レベルの基本要素を推論することで、目的とする構成を実現できます。
VFSによって捉えられた環境の属性をより理解するために、ロボット操作タスクにおける多数の独立した軌道からVFSに符号化された観測値をサンプリングし、高次元データにおけるクラスタの可視化に有効なt-SNE法を用いて2次元軸上に射影しました。
このt-SNEのembeddings により、VFSが識別しモデル化した興味深いパターンが明らかになりました。これらのクラスタのいくつかを詳細に見ると、VFSは、テーブル上の物体の相対的な位置やロボットアームの姿勢などの雑念を無視して、風景内のコンテンツ(物体)やアフォーダンス(例えば、ロボットのグリッパーで握るとスポンジが操作できる)の情報をうまく捉えていることが分かります。これらの要素はタスクの解決に重要であることは間違いありませんが、ロボットが利用できる低レベルの基本要素がそれらを抽象化するため、高レベルのコントローラとは機能的に無関係になるのです。
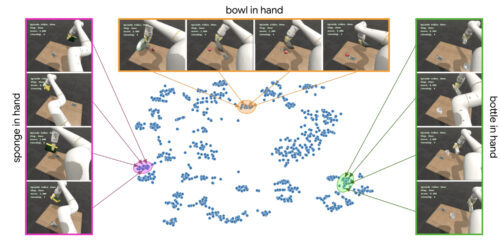
VFS embeddingsの2次元t-SNE投影を可視化すると、同等な環境構成がクラスタリングされます。腕の姿勢などのタスクに無関係な要素は無視されます。
結論と今後の課題への接続
価値関数空間は、スキルの価値関数に基づいて構築された特徴表現であり、スキルに対する長期目線の推論と計画を可能にします。VFSは、風景内のアフォーダンスとタスク関連情報を捉え、かつ紛らわしさに耐性を持つコンパクトな特徴表現です。
このような特徴表現は、モデルベースおよびモデルフリー手法のプランニングを向上させ、ゼロショット汎化を可能にすることが実証実験により明らかにされました。
今後、この特徴表現は、マルチタスク強化学習の分野とともに、さらに改良されていくことが期待されます。また、VFSの解釈可能性により、安全な計画や言語モデルの接地などの分野への応用も期待できます。
謝辞
論文への貢献とこのブログ記事にフィードバックをいただいた共著者のSergey Levine、Ted Xiao、Alex Toshev、Peng Xu、Yao Luに感謝します。また、このブログ記事で使用した有益なビジュアライゼーションを作成したTom Smallに感謝します。
3.VFS:強化学習で長期目線が必要な行動を実現(2/2)関連リンク
1)ai.googleblog.com
Extracting Skill-Centric State Abstractions from Value Functions
2)arxiv.org
Value Function Spaces: Skill-Centric State Abstractions for Long-Horizon Reasoning

