
1.DeepFusion:センサー情報とカメラ情報を効果的に融合して3次元物体検出(2/2)まとめ
・InverseAugとLearnableAlignという2つの新手法で位置合わせを改善しDeepFusionを実現
・DeepFusionはシングルでもアンサンブルでもWaymoのベンチマークで最先端の性能を達成
・InverseAugとLearnableAlignはそれぞれ単独でもモデルの性能向上に寄与していた
2.InverseAugとLearnableAlign
以下、ai.googleblog.comより「Lidar-Camera Deep Fusion for Multi-Modal 3D Detection」の意訳です。元記事は2022年4月12日、Yingwei LiさんとAdams Wei Yuさんによる投稿です。
アイキャッチ画像のクレジットはPhoto by Alexandre Debiève on Unsplash
LearnableAlign:位置合わせを学習するAttention
また、位置合わせを学習するLearnableAlignを導入しています。
LearnableAlignは、位置合わせ品質を向上させるために、クロスモダリティ-アテンション(cross-modality-attention–based feature-level alignment technique)に基づく特徴レベルの位置合わせ手法です。
PointPaintingやPointAugmentingのような入力レベルの融合手法では、三次元LiDARの点が与えられた時、1対1にマッピングする事が可能なため、対応するカメラの画素のみを正確に位置付けることができます。
一方、DeepFusionパイプラインで特徴を融合する場合、各LiDAR特徴は点のサブセットを含む三次元画素を表すため、対応するカメラ画素はポリゴン内に存在します。そのため、位置合わせ問題は三次元画素と二次元画素集合の間のマッピングを学習する問題になります。
素朴なアプローチとしては、与えられた三次元画素に対応するすべての二次元画素を平均化することです。しかし、直感的に、及び可視化された結果からも裏付けられるように、全ての画素が同じ重要度を持つわけではありません。LiDARの特徴表現情報はすべてのカメラの画素と均等に位置合わせされるわけではありません。
例えば、ある画素は物体検出のための重要な情報(例えば、目標となる物体)を含み、他の画素は情報が少ない(例えば、道路、植物、視界を妨げる障害物などの背景で構成されている)かもしれません。
LearnableAlignは、クロスモダリティ-アテンション機構を活用し、2つのモダリティ間の相関を動的に捉えます。ここで、入力には三次元画素内のLiDARの特徴と、それに対応する全てのカメラの特徴が含まれます。
attentionの出力は、基本的にカメラ特徴の合計の重みであり、ここで重みはLiDARとカメラ特徴の関数によって一括して決定されます。より具体的には、LearnableAlignは3つの完全連結レイヤーを使用して、LiDAR特徴をベクトル(ql)に、カメラ特徴をベクトル(kc)および(vc)にそれぞれ変換します。
各ベクトル(ql)に対して、(ql)と(kc)の間の内積を計算し、LiDAR特徴と対応するカメラ特徴間の相関を含むattention affinity行列を求めます。ソフトマックス演算子で正規化されたattention affinity行列を用いて重みを計算し、カメラ情報を含むベクトル(vc)を集約します。
集約されたカメラ情報は、次に完全連結レイヤーで処理され、元のLiDAR特徴と連結(Concat)されます。この出力は、モデル学習のために、PointPillarsやCenterPointなどの標準的な3D検出フレームワークに渡されます。
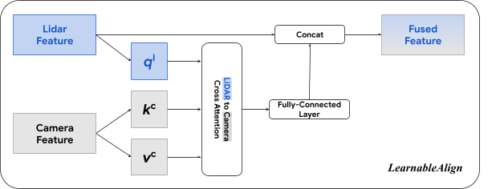
LearnableAlignは、LiDARとカメラの特徴を位置合わせするために、クロスアテンション機構を利用します。
DeepFusion:異なるモダリティの情報を融合するためのより良い方法
私たちは、2つの新規特徴位置合わせ技術によって、完全にエンドツーエンドのマルチモーダル3D検出フレームワークであるDeepFusionを開発しました。
DeepFusionのパイプラインでは、まずLiDARポイントを既存の特徴抽出器(例:PointPillarsの柱状特徴ネット)に送り込み、LiDAR特徴(例:疑似画像)を得ます。一方、カメラ画像は2次元画像特徴抽出器(例えば、ResNet)に与えて、カメラ特徴を得ます。
次に、カメラとLiDARの特徴を融合させるために、InverseAugとLearnableAlignを適用します。最後に、融合された特徴は、選択された3D検出モデルの残りの部品(例えば、PointPillarsからのバックボーンと検出ヘッド)によって処理され、検出結果が得られます。
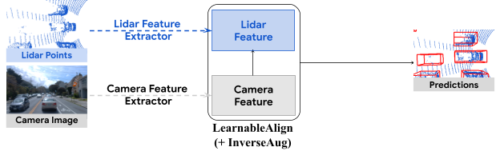
DeepFusionの処理の流れ
ベンチマーク結果
自律走行車のための最大級の3D検出チャレンジであるWaymo Open Datasetで、リーダーボードにモデルのパフォーマンスをランク付けする際のデフォルトの指標である難易度2のAPH(Average Precision with Heading)を用いて、DeepFusionを評価しました。
世界中の70の参加チームの中で、DeepFusionのシングルモデルとアンサンブルモデルは、対応するカテゴリーで最先端の性能を達成しました。
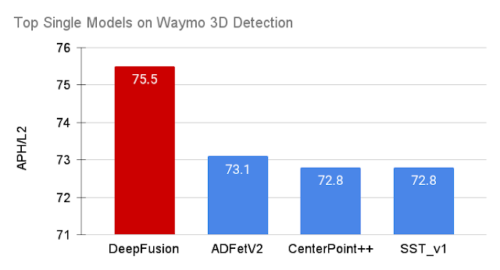
DeepFusionのシングルモデルは、Waymo Open Datasetで新たな最先端性能を達成しました。
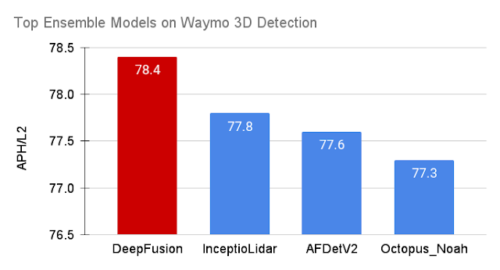
DeepFusionのアンサンブルモデルは、Waymo Open Datasetにおいて他のすべての手法を上回り、リーダーボードで1位を獲得しました。
InverseAugとLearnableAlignの寄与度
提案するInverseAugとLearnableAlignの効果を検証するために、アブレーション研究も行っています。InverseAugとLearnableAlignは、それぞれ単独でLiDARのみのモデルに比べて性能向上に寄与し、さらに両者を組み合わせることでより大きな性能向上が得られることを実証しています。
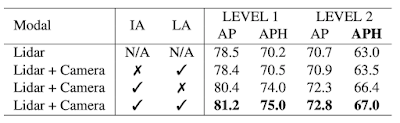
InverseAug(IA)と LearnableAlign(LA)のアブレーションスタディを平均精度(AP)とAPHで測定。両技術を組み合わせることで、最高の性能向上に寄与しています。
まとめ
私達は、後期深層特徴量融合は、特徴がうまく位置合わせできていればより効果的であることを実証しましたが、2つの異なるモダリティからの特徴を位置合わせすることは困難でした。この課題に対処するため、私達はマルチモーダル特徴間の位置合わせの品質を向上させるための2つの技術、InverseAugとLearnableAlignを提案します。これらの技術を私達の提案するDeepFusion手法の融合ステージに組み込むことで、Waymo Open Datasetにおいて最先端の性能を達成することができました
謝辞
共著者のTianjian Meng, Ben Caine, Jiquan Ngiam, Daiyi Peng, Junyang Shen, Bo Wu, Yifeng Lu, Denny Zhou, Quoc Le, Alan Yuille, Mingxing Tanに感謝します。
3.DeepFusion:センサー情報とカメラ情報を効果的に融合して3次元物体検出(2/2)関連リンク
1)ai.googleblog.com
Lidar-Camera Deep Fusion for Multi-Modal 3D Detection
2)arxiv.org
DeepFusion: Lidar-Camera Deep Fusion for Multi-Modal 3D Object Detection

