
1.SmeLU:ディープラーニングの再現性を悪化させている犯人はReLU関数(2/3)まとめ
・ReLU関数は勾配が0になった時に学習結果を反映できないのでランダムな挙動に繋がる
・活性化が滑らかなネットワーク(GELU、Swishなど)は、再現性が高いことがわかった
・SmeLU活性化関数は、他の滑らかな活性化関数の懸念に対処するシンプルな関数
2.SmeLUとReLU
以下、ai.googleblog.comより「Reproducibility in Deep Learning and Smooth Activations」の意訳です。元記事は2022年4月5日、Gil ShamirさんとDong Linさんによる投稿です。
アイキャッチ画像のクレジットはPhoto by photo_ reflect on Unsplash
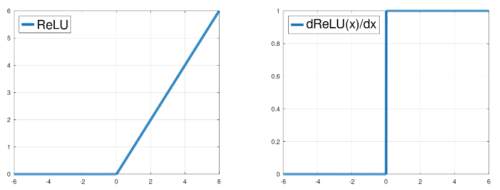
モデルのパラメータ更新時に、あるユニットの活性化を正の値から負に押し下げようとしたとしましょう。ReLU関数の勾配は正のユニット値に対して1なので、更新のたびにユニットをどんどん小さくしていきます。(上図の左側)。
このユニットの活性化が正の値から負の値への閾値を超えた時点で、勾配は突然大きさ1から大きさ0に変化します。モデルは学習結果を反映するためにユニットを左方向に移動させ続けようとしますが、勾配が0であるため、それ以上負の方向に移動することができません。そのため、モデルは動かせる他のユニットを更新することに頼るしかありません。
私達は、活性化が滑らかなネットワーク(GELU、Swish、Softplusなど)は、再現性が高いことを発見しました。このようなネットワークは、最適化対象となる地形は似ていますが、領域が少ないため、モデルが発散する機会が少ないのです。
ReLUのような急変とは異なり、活性度が減少していくユニットでは、勾配が徐々に0になり、他のユニットが変化に適応する機会が与えられます。初期化を均等にし、学習サンプルを適度にシャッフルし、隠れ層の出力を正規化することで、活性化を滑らかにし、同じ最小値に収束する可能性を高めることができます。しかし、非常に積極的なデータシャッフリングを行うと、この利点は失われます。
滑らかな活性化関数は、出力レベル間の遷移速度、すなわち「滑らかさ」を調整することができます。十分な滑らかさを確保することで、精度や再現性が向上します。しかし、滑らかさが高すぎると、線形モデルに近づき、モデルの精度が低下するため、ディープネットワークを用いる利点が失われます。
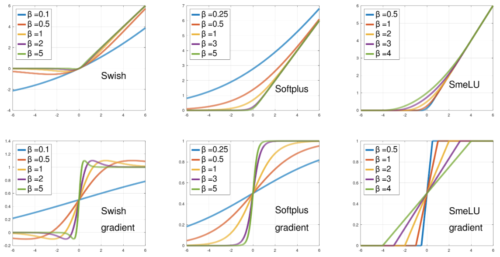
入力値の関数として、異なる滑らかさパラメータ値βに対する滑らかさ活性度(上)とその勾配(下)。βは勾配が0と1の間の遷移領域の幅を決めます。SwishとSoftplusではβが大きいほど領域が狭くなり、SmeLUではβが大きいほど領域が広くなります。
Smooth reLU(SmeLU)
GELUやSwishなどの活性化関数は、指数関数や対数関数をサポートするために複雑なハードウェアの実装が必要です。また、GELUは数値計算または近似計算が必要です。これらの特性により、展開にエラーが発生しやすく、高価で、時間がかかる可能性があります。
また、GELUとSwishは単調(monotonic)でなく、少し減少してから増加に転じます。完全に止まる事や1がきれいな勾配を持たないという特性は、解釈可能性(または識別可能性)を妨げる可能性があります。
実装を単純化すれば、再現性を支援する可能性があります。Smooth reLU(SmeLU) 活性化関数は、他の滑らかな活性化関数の懸念に対処するシンプルな関数として設計されています。これは、左側の勾配0と右側の勾配1の直線を2次関数的な中間領域で接続し、接続点での連続勾配を拘束する(Huber損失関数の非対称版として)ものです。
SmeLUは、箱型フィルターを持つReLUの畳み込みと見なすことができます。これは、より計算量が多く複雑な滑らかな活性化関数に匹敵する、再現性と精度のトレードオフを持つ、安価でシンプルな滑らかな解決策を提供します。
下図は、滑らかでないReLUからより滑らかなSmeLUに徐々に移行する際の損失(目的)面の変遷を示したものです。幅0の遷移は、損失の目的が多くの局所的最小値を持つ基本的なReLU関数です。遷移領域が広くなると(SmeLU)、損失表面はより滑らかになります。
遷移の幅が広すぎる、つまり滑らかすぎると、ディープネットワークを使うメリットが薄れ、線形モデルに近づいてしまいます。目表面が平坦になり、ネットワークが多くの情報を表現する能力を失ってしまう可能性があります。

2つの損失関数の損失曲面(中央と右)
ReLUから次第に滑らかになるSmeLUへの移行(左)
SmeLU関数の滑らかさが増すにつれて、損失表面はより滑らかになります
3.SmeLU:ディープラーニングの再現性を悪化させている犯人はReLU関数(2/3)関連リンク
1)ai.googleblog.com
Reproducibility in Deep Learning and Smooth Activations
2)arxiv.org
Real World Large Scale Recommendation Systems Reproducibility and Smooth Activations
