
1.PaLM:5400億パラメータを持つ革新的なパスウェイ言語モデル(2/3)まとめ
・PaLMの性能はモデル規模の関数として表現でき、性能が更に向上可能である事が示唆される
・PaLMは適切な文脈で概念の組み合わせを理解するので絵文字から映画を推測する事が可能
・算数の文章問題では9~12歳の子供たちの平均得点に迫り、ジョークを解説する事も可能
2.PaLMの性能
以下、ai.googleblog.comより「Pathways Language Model (PaLM): Scaling to 540 Billion Parameters for Breakthrough Performance」の意訳です。元記事は2022年4月4日、Sharan NarangさんとAakanksha Chowdheryさんによる投稿です。
アイキャッチ画像のクレジットはPhoto by Stephen Leonardi on Unsplash
また、最近リリースされた150以上の新しい言語モデリングタスクからなるBIG-bench(Beyond the Imitation Game Benchmark)でPaLMの新機能と将来機能を調査し、PaLMが飛躍的な性能向上を達成することを明らかにしました。
また、58のタスクの共通サブセットで平均化した性能をGopherやChinchillaと比較しました。興味深い事ですが、PaLMの性能はモデル規模の関数として表現でき、従来のモデルと同様に対数線形グラフを示すことに着目しています。これはPaLMの規模を更に拡大する事で性能が更に向上できる事を示唆しています。また、PaLM 540B 5-shotは、同じタスクを解くよう求められた人間の平均的なパフォーマンスよりも良い結果を出しています。
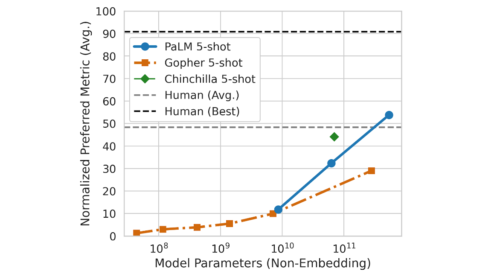
PaLMの規模を拡大した際の性能向上の図。BIG-bench内の58タスクで測定
PaLMは、いくつかのBIGベンチタスクにおいて、素晴らしい自然言語理解・生成能力を実証しています。例えば、このモデルは原因と結果を区別し、適切な文脈で概念の組み合わせを理解し、さらには絵文字から映画を推測することができます。

BIGベンチの課題である「原因と結果のラベル付け」「概念の理解」「絵文字から映画を推測」「同義語や対義語の発見」において、PaLM 540Bの1ショットパフォーマンスを示す例です。
推論
PaLMは、モデルの規模と「思考の連鎖プロンプト(chain-of-thought prompting)」を組み合わせることで、多段階の演算や常識的な推論を必要とする推論タスクで画期的な能力を発揮します。Gopherのような先行LLMでは、モデル規模を拡大しても性能向上の恩恵はあまり見られませんでした。

小学校の算数の問題を例に、標準的なプロンプトと思考の連鎖プロンプトを比較したもの
思考の連鎖プロンプトは、複数ステップの推論問題に対するプロンプトを、人がアプローチするのと同じように、中間ステップ(黄色でハイライト)に分解するものです。
PaLM 540Bと思考の連鎖プロンプトを組み合わせることで、3つの算数データセットと2つの推論データセットで高い性能が確認できました。
例えば、GSM8Kは小学校の算数問題を集めたベンチマークで、PaLM 540Bは8ショットプロンプトで58%の問題を解くことができました。
これは、7500問のトレーニングセットを用いてGPT-3 175Bモデルを微調整し、外部の計算機や検証機と組み合わせることで達成された、従来のトップスコア55%を上回るものです。
この新しいスコアは、この問題集のターゲットである9~12歳の子供たちが解く問題の平均値60%に迫るもので、特に興味深いものです。私達は、PaLMの語彙の中で数字を別々にエンコードすることで、このような性能向上が可能になったのではないかと考えています。
また、PaLMは、多段階の論理的推論、世界に関する知識、深い言語理解の複雑な組み合わせを必要とするシナリオに対しても、明示的な説明を生成することができるのが大きな特徴です。例えば、ウェブ上では見つけられないような新しいジョークに対して、質の高い説明を提供することができます。

PaLMは、2ショットプロンプトでオリジナルジョークを解説していますプロンプト
以下のジョークを説明しなさいジョーク:GoogleがTPUチームに雄弁な鯨を採用したのをご覧になりましたか?クジラは、2つの異なるPodsの間でコミュニケーションする方法を教えてくれました。
モデルの応答
TPSは、Googleがディープラーニングに使用しているコンピュータチップの一種です。Podsとは、TPUのグループのことです。Podsはクジラの群れでもあります。クジラは2つのクジラのグループの間で通信できますが、話し手はクジラが2つのTPUのグループの間で通信できるフリをしているというジョークです。
コード生成
LLMは、自然言語で記述されたコードを書く(text-to-code)、ある言語から別の言語へコードを翻訳する、コンパイルエラーを修正する(code-to-code)といったコーディングタスクにもうまく汎化することが示されています。
PaLM 540Bは、事前学習データセットに含まれるコードがわずか5%であるにもかかわらず、1つのモデルでコーディングタスクと自然言語タスクにまたがる強い性能を示しています。
その小数回学習性能は、学習に使うPythonのコードが50倍少ないにもかかわらず、微調整を行ったCodex 12Bと同等であることから、特に注目されます。この結果は、他のプログラミング言語や自然言語データからの学習をより効果的に転移できるため、より大きなモデルはより小さなモデルよりもサンプル効率が高いという、以前の発見を補強するものです。
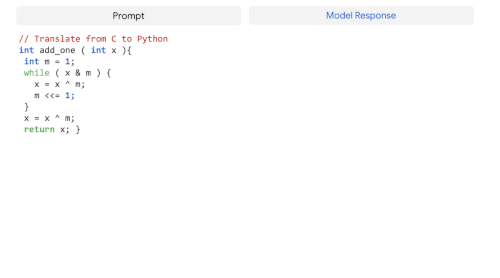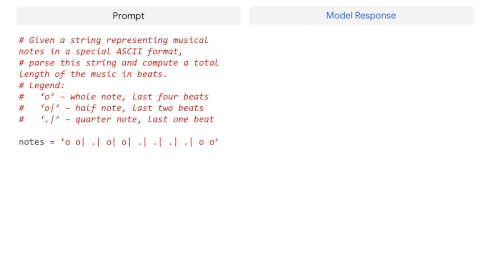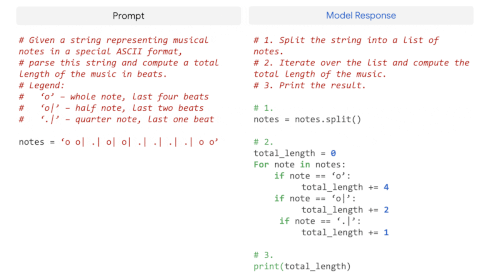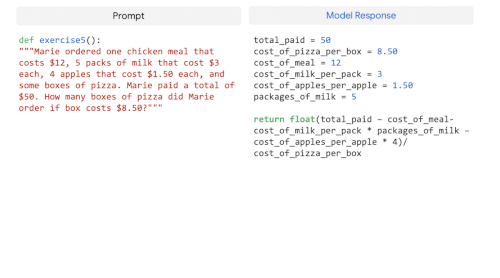
GSM8K-PythonやHumanEvalなどのtext-to-codeタスクとTranscoderなどのcode-to-codeタスクで微調整したPaLM 540Bモデルの例
3.PaLM:5400億パラメータを持つ革新的なパスウェイ言語モデル(2/3)関連リンク
1)ai.googleblog.com
Pathways Language Model (PaLM): Scaling to 540 Billion Parameters for Breakthrough Performance
2)arxiv.org
PaLM: Scaling Language Modeling with Pathways
