
1.4D-Net:センサーの奥行情報とカメラのRGB画像を同時に扱う(2/2)まとめ
・軽量なNASを用いて2タイプのセンサー入力と特徴表現間の接続を学習させた
・4D-Netは従来手法より多いセンサー入力を使用しているが半分の応答速度で精度も向上
・4D-Netでは従来手法では見逃していた遠くの物体を検出することもできる
2.4D-Netの性能
以下、ai.googleblog.comより「4D-Net: Learning Multi-Modal Alignment for 3D and Image Inputs in Time」の意訳です。元記事は2022年2月23日、AJ PiergiovanniさんとAnelia Angelovaさんによる投稿です。
アイキャッチ画像のクレジットはPhoto by Daniele Levis Pelusi on Unsplash
複数のセンサー情報を取り扱い可能な動的な接続学習
私達は、最も正確な3D境界ボックス検出を得るために、軽量なニューラル・アーキテクチャ探索を用いて、2つのタイプのセンサー入力とその特徴表現間の接続を学習します。
自律走行車の研究では、特に距離の変化する物体を確実に検出することが重要です。最近のLiDARセンサーは数百メートル先の範囲も測定可能です。
このことは、遠くの物体は画像上で小さく表示され、それらを検出するための最も価値のある特徴は、より前の方のレイヤーにあることを意味します。これは、後の方のレイヤーで表される近くの物体とは対照的です。
この観察に基づき、私達は接続を動的に変更し、self-attentionメカニズムを用いて、特徴を全てのレイヤーの中から選択するようにしました。私達は学習可能な線形レイヤーを適用し、他の全ての層の重みにattentionの重み付けを適用し、目下のタスクに最適な組み合わせを学習することができるようにしました。
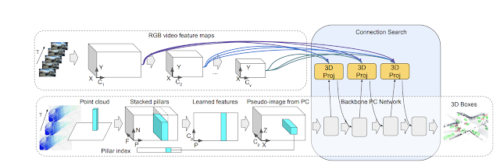
3次元点群の入力とRGBカメラ映像の入力の特徴間の接続を組み合わせる接続学習アプローチの概略図。各接続は、対応する入力に対する重み付けを学習します。
結果
先行モデルは3次元点群のみ、または単一点群とカメラ画像データの組み合わせしか活用していませんが、Waymo Open Datasetベンチマークを使って、私達の結果を最先端のアプローチと比較評価しました。
4D-Netは、両方のセンサー入力を効率的に利用し、32点の点群と16点のRGBフレームを時間に沿って164ミリ秒以内に処理し、他の手法と比較して良好な結果を得ています。それに比べ、次に良いスコアを出した手法は、ニューラルネットの計算に300ミリ秒かかり、4D-Netより少ないセンサー入力を使用しているため、効率と精度に劣ります。
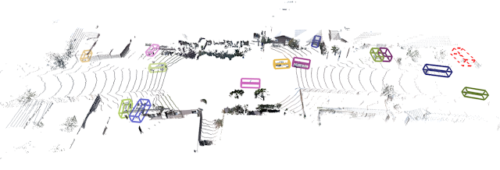

3D風景内の結果
上:検出された車両に対応する3D境界ボックスは異なる色で表示され、点線のボックスは見落とされた物体を示しています。
下:可視化用に、境界ボックスは対応するカメラ画像内に表示されています。
遠くの物体を検出する
4D-Netのもう一つのメリットは、画像平面上の物体を正確に検出できるRGBの高解像度と、点群データがもたらす正確な深度の両方を利用できることです。その結果、これまで点群のみのアプローチでは見逃していた遠くの物体を4D-Netで検出することができるようになります。これは、カメラデータを融合して遠くの物体を検出し、その情報を効率よく3D部分に伝達することで、正確な検出を実現しているためです。
時間に沿ったデータを扱う事に価値はあるのでしょうか?
4D-Netの価値を理解するために、私たちは一連のアブレーションスタディを行います。その結果、少なくとも片方のセンサー入力を時間軸でストリーミングした場合、検出精度が大幅に向上することがわかりました。両方のセンサー入力を時間的に考慮することで、最も大きな性能向上が得られます。
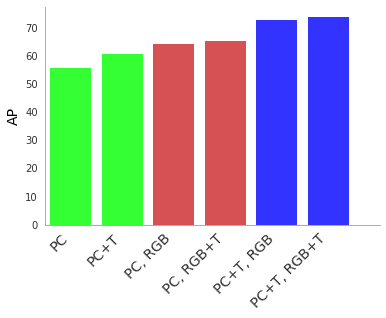
点群(PC: point clouds)、時間軸点群(PC+T)、RGB画像入力(RGB)、時間軸RGB画像(RGB+T)を使用した場合の3D物体検出の4D-Netの性能を平均精度(AP)で測定。
両方のセンサー入力を時間的に組み合わせることが、RGB入力なしでPCを使用する一番左の列(緑)と比較して、最適(一番右の青)です。全て、4D-Netマルチモーダル学習を使用して接続方法を学習しています。
マルチストリーム4D-Net
4D-Netの動的接続学習機構は汎用的であるため、点群ストリームとRGBビデオストリームの組み合わせだけに限定されることはありません。実際、3次元点群ストリームと組み合わせて、解像度の高い単一画像ストリームや低解像度のビデオストリームを提供することは、非常に費用対効果が高いことが分かっています。以下、4つのストリームを入力とする設計を示します。このアーキテクチャは、点群と画像の2つのストリームを入力とする設計よりも優れた性能を発揮します。
動的な接続学習は、特定の特徴入力を選択して接続します。複数の入力ストリームがある場合、4D-Netは複数の入力の中から特徴表現間の接続を学習する必要がありますが、アルゴリズム自体は変化せず、単に入力の組合わせから特定の特徴を選択する事なので、シンプルです。
微分可能なアーキテクチャ検索を使用しているため、モデルアーキテクチャ自体の中に新しい配線を発見することができます。新しい4D-Netモデルを効率的に驚くほど軽量な処理で発見することができます。
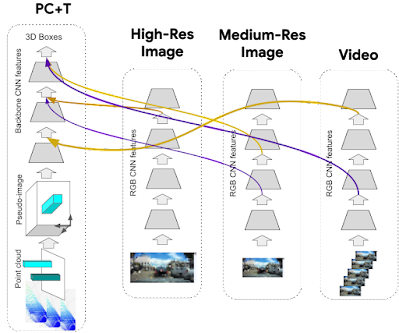
マルチストリーム4D-Netの例
3次元点群の時間的ストリーム(PC+T)と複数の画像ストリームから構成されています。
画像ストリームは、高解像度単一画像のストリーム、中解像度の単一画像ストリーム、更に低解像度のビデオストリームから構成されています。
まとめ
深層学習は実世界のアプリケーションで大きな進歩を遂げていますが、研究コミュニティは複数のセンセー入力を使って学習する手法を模索し始めたところです。
私達は、自律走行における3D物体検出という一般的なアプリケーションのために、3D点群とRGBカメラ画像を時間的に結合する方法を学習する4D-Netを発表しました。
私達は、4D-Netが、特に遠距離にある物体を検出するための効果的なアプローチであることを実証しました。この研究が、将来の4Dデータ研究のための貴重なリソースとなることを期待しています。
謝辞
この研究は、AJ Piergiovanni, Vincent Casser, Michael Ryoo and Anelia Angelovaによって行われました。共同研究者のVincent Vanhoucke, Dragomir Anguelov、そしてWaymoとGoogleのRoboticsの同僚のサポートと議論に感謝します。また、グラフィック・アニメーションについては、Tom Smallに感謝します。
3.4D-Net:センサーの奥行情報とカメラのRGB画像を同時に扱う(2/2)関連リンク
1)ai.googleblog.com
4D-Net: Learning Multi-Modal Alignment for 3D and Image Inputs in Time
2)openaccess.thecvf.com
4D-Net for Learned Multi-Modal Alignment(PDF)

