
1.TaskMoE:効率的に推論を行うためにタスク別のルーティングを学習(2/2)まとめ
・蒸留でサイズを削減する際は教師モデルから生徒モデルを訓練する追加計算が必要
・更にTokenMoEを蒸留しても向上したパフォーマンスを全て維持する事はできない
・TaskMoEは規模拡大による品質向上を維持したまま推論に適したアルゴリズムを実現
2.TaskMoEとTokenMoE
以下、ai.googleblog.comより「Learning to Route by Task for Efficient Inference」の意訳です。元記事は2022年1月14日、Sneha KuduguntaさんとOrhan Firatさんによる投稿です。
アイキャッチ画像のクレジットはPhoto by Nick Seagrave on Unsplash
このアプローチを実証するために、Transformerアーキテクチャに基づくモデルを学習させます。
GShard-M4やGLaMと同様に、Transformer層内のフィードフォワードネットワークを、複数の同じフィードフォワードネットワーク(expertsと呼びます)からなるMixture-of-Experts(MoE)層と置き換えます。
各タスクで、モデルの他の部分と一緒に学習されたルーティングネットワークは、すべての入力トークンにおいてタスクを識別して追跡しています。そして、タスクに特化したサブネットワークを形成するために、層ごとに定まった数のエキスパート(上図の場合は2)を選択します。
比較対象とした密なTransformerモデルは143Mのパラメータを持ち、エンコーダとデコーダの両方が6層です。私たちが学習させたTaskMoEとTokenMoEも共に6層ですが、MoE層毎に32のexpertsが存在し、合計533Mのパラメータを持ちます。
一般に公開されているWMTデータセットを用いてモデルを学習させています。このデータセットは、異なる言語族と台本からなる30言語ペアの431M以上の文から構成されています。詳細は論文をご覧ください。
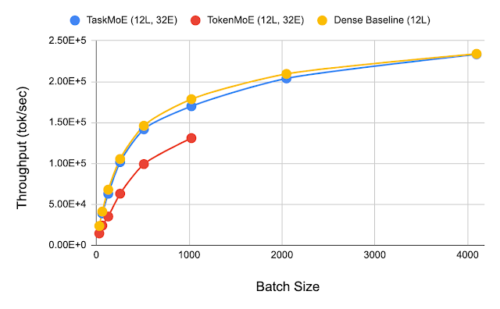
バッチサイズを変えてTaskMoEとTokenMoEの応答速度を比較しています。TokenMoEの最大バッチサイズは1024であるのに対し、TaskMoEとベースラインの密モデルは4096です。ここで、TokenMoEは64個のTPUv3コアに分散した1つのインスタンスを持ち、TaskMoEとベースラインモデルは64個のコアのそれぞれに1つのインスタンスを持っています。
人気の高い手法では、大きな教師モデルが、教師の性能に見合うような小さな生徒モデルを訓練します。しかし、この方法は、教師モデルから生徒モデルを訓練するために追加の計算が必要になるという代償を伴います。そこで、TaskMoEと、知識蒸留法を用いてサイズを圧縮したTokenMoEモデルを比較します。圧縮したTokenMoEモデルは、TaskMoEから抽出したタスク単位のサブネットワークと同程度のサイズです。
また、TaskMoEは追加の学習を必要としないシンプルな手法であることに加え、私たちの多言語翻訳モデルにおいて、蒸留されたTokenMoEモデルより全言語で平均2.1BLEU向上していることがわかりました。
私たちは、蒸留手法(distillation)が「多言語対応密モデルをTokenMoEに規模拡大することで達成された性能向上」の43%を保持できている一方、TaskMoEモデルから必要な小さなサブネットワークを抽出すれば品質の損失がないことに注目しました。
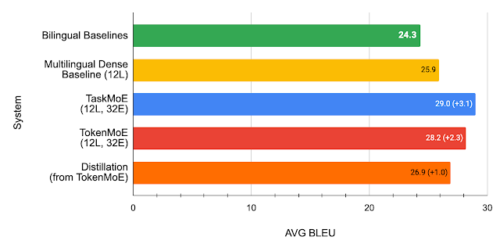
12層(エンコーダ6層、デコーダ6層)、experts数32のTaskMoE、TokenMoEモデルとTokenMoEモデルを比較したBLEUスコア(高いほど良い)。どちらのアプローチも多言語対応した密モデルより改善されますが、TaskMoEは比較対象より平均3.1BLEU改善され、TokenMoE+蒸留は比較対象より平均1.0BLEU改善されました。
次のステップ
機械学習モデルの規模を拡大すると品質向上がしばしば見られることから、研究コミュニティは、大規模モデルの学習を効率的に行うためのスケーリング技術の進歩に取り組むようになりました。
また、複数のタスクやモダリティに一般化できるモデルを学習させる必要が出てきており、モデルのスケーリングに対するニーズはさらに高まっています。しかし、このような大規模モデルの実用化には大きな課題が残されています。大規模モデルを効率的に展開可能にする事は、研究の重要な方向性であり、TaskMoEは、スケーリングによる品質向上を維持したまま、より推論に適したアルゴリズムを実現する有望なステップであると信じています。
謝辞
まず、共著者に感謝します。
Yanping Huang, Ankur Bapna, Maxim Krikun, Dmitry Lepikhin そして Minh-Thang Luong。
また、Wolfgang Macherey, Yuanzhong Xu, Zhifeng Chen 及び Macduff Richard Hughesには、有益なご意見をいただきました。また、TranslateチームとBrainチームには、有益な意見と議論をいただき、GShard開発チーム全体には、このプロジェクトに基礎的な貢献をしていただき、特に感謝しています。また、このブログ記事のアニメーションを作成してくれたTom Smallにも感謝します。
3.TaskMoE:効率的に推論を行うためにタスク別のルーティングを学習(2/2)関連リンク
1)ai.googleblog.com
Learning to Route by Task for Efficient Inference
2)arxiv.org
Beyond Distillation: Task-level Mixture-of-Experts for Efficient Inference

