
1.取り返しのつかない行動を避ける可逆性を意識した自己教師型強化学習(2/3)まとめ
・強化学習に可逆性を統合する手法として探索のRAEと制御のRACを提案した
・RAEとRACの重要な違いはRAEは可逆的な動作を推奨するだけで禁止していない事
・RAEは不可逆的な副作用を回避可能でRACは安全で可逆的な操作を保証可能
2.RAEとRAC
以下、ai.googleblog.comより「Self-Supervised Reversibility-Aware Reinforcement Learning」の意訳です。元記事の投稿は2021年11月3日、Johan Ferretさんによる投稿です。
アイキャッチ画像のクレジットはPhoto by National Cancer Institute on Unsplas
強化学習(RL)に可逆性を統合
私達は、RLに可逆性を統合する2つの並行した手法を提案します。
(1)可逆性を意識した探索(RAE:Reversibility-Aware Exploration)
このアプローチは、報酬関数を修正して不可逆的な遷移にペナルティを課すものです。エージェントが不可逆的と考えられる行動を選択した場合、環境の報酬から正の固定ペナルティを引いたものに相当する報酬を受け取ることになります。
(2)可逆性を考慮した制御(RAC:Reversibility-Aware Control)
RACでは、すべての不可逆的な行動がフィルタリングされ、ポリシーと環境の間の中間層としての役割を果たす制御が行われます。エージェントが不可逆的と考えられる行動を選択すると、可逆的な行動が選択されるまで、行動選択プロセスが繰り返されます。
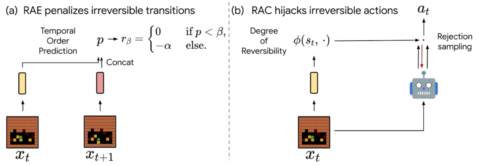
可逆性を考慮したRLを実現するRAE(左)とRAC(右)
RAEとRACの重要な違いは、RAEは可逆的な動作を推奨するだけで、禁止していないことです。つまり、以下の倉庫番の例のように、コストよりもメリットが大きい場合には、不可逆的な動作を行うことができます。そのため、RACは不可逆的な副作用によるリスクを完全に回避すべき安全なRLに適しており、RAEは不可逆的な行為をほとんど回避すべきだと思われる作業に適しています。
RAEとRACの違いを説明するために、2つの手法の能力を評価しました。
いくつかの例を以下に示します。

(1)不可逆的な副作用を回避(禁止ではなく)
安全なRLが従うべき一般的な規則は、注意の原則(principle of caution)として、不可逆的な相互作用を可能な限り最小化することです。
このような能力をテストするために、オープンフィールドにいるエージェントがゴールに到達することを課題とする合成環境を導入しました。エージェントが確立された道に沿っていれば、環境は変化しませんが、道から離れて草むらに入ると、エージェントが踏んだ経路は茶色に変わります。このように環境が変化しても、ペナルティは発生しません。
このシナリオでは、Proximal Policy Optimization(PPO)エージェントのような典型的なモデルフリーエージェントは、平均的に最短経路をたどる傾向があり、芝生の一部を台無しにしてしまいますが、PPO+RAEエージェントは不可逆的な副作用をすべて回避します。
左上:エージェント(青)がゴール(ピンク)に到達するようにタスクを与えられている合成環境。エージェントからゴールまでの道筋はグレーで示されていますが、両者の間の最も直線的ルートを通っているわけではありません。
右上:エージェントの行動による不可逆的な副作用を伴う行動の履歴。エージェントが道から外れると、フィールドに茶色の道ができます。
左下:PPOエージェントの訪問経路のヒートマップ。エージェントは、灰色で示された経路よりも、より直接的な経路をたどる傾向があります。
右下:PPO+RAEエージェントの訪問経路のヒートマップ。経路を外れる事は不可逆性を伴うため、エージェントが確立されたグレーの道筋に留まることを促します。
(2)不可逆的操作の禁止による安全な操作
また「Cartpole」と呼ばれる古典的な課題では、エージェントが台車(cart)を操作して,その上に不安定に直立した棒(pole)のバランスを取ることができるかどうかをテストしました。このタスクでは、操作可能数の上限を、通常の200ステップから50,000ステップに設定しました。このタスクでは、不可逆的なアクションは棒の落下を引き起こす傾向があるため、そのようなアクションは一切行わない方がよいです。
RACと任意のRLエージェント(ランダムなエージェントでもよい)との組み合わせは、ある行動が不可逆的である確率に適切な閾値(threshold)を選択すれば、決して失敗しないことを示しました。このように,RACは環境の中での最初の一歩から、安全で可逆的な操作を保証することができます。
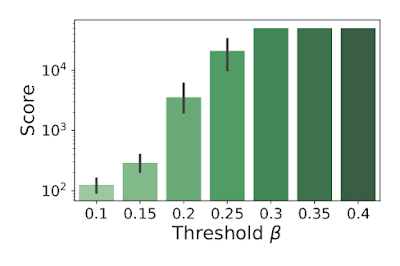
RACを搭載したランダムポリシーによるCartpoleスコアが、異なる閾値でどのように変化するかを示しました。標準的なモデルフリーエージェント(DQN, M-DQN)のスコアは通常3000以下であるのに対し、閾値β=0.4のランダム+RACポリシーを適用したエージェントのスコアは50000(最大)です。
3.取り返しのつかない行動を避ける可逆性を意識した自己教師型強化学習(2/3)関連リンク
1)ai.googleblog.com
Self-Supervised Reversibility-Aware Reinforcement Learning
2)arxiv.org
There Is No Turning Back: A Self-Supervised Approach for Reversibility-Aware Reinforcement Learning
