
1.FLAN:指示調整により初見タスク実行能力を向上した言語モデル(2/2)まとめ
・FLANはGPT-3よりサイズが小さいがゼロショット設定のGPT-3を上回った
・一部のタスクでは小数ショット設定のGPT-3よりも優れた結果を出した
・モデルの規模は指示調整からメリットを得る際に重要な事も判明
2.GPT-3のゼロショットを超えるFLAN
以下、ai.googleblog.comより「Introducing FLAN: More generalizable Language Models with Instruction Fine-Tuning」の意訳です。元記事は2021年10月6日、Maarten BosmaさんとJason Weiさんによる投稿です。
微調整(Finetune:BERT, T5)とPrompting(GPT-3)と指示調整(Instruction tuning:FLAN)の対比は元論文の以下の図がわかりやすいと思いました。
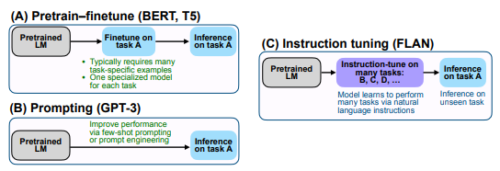
アイキャッチ画像のクレジットはPhoto by Daniel J. Schwarz on Unsplash
FLANモデルの評価
FLANを他の手法と違いがわかるように比較するために、確立されたベンチマークデータセットを使用して、モデルのパフォーマンスを既存のモデルと比較しました。また、トレーニング中にそのデータセットの例を見てない場合に、FLANがどのように機能するかを評価しました。
ただし、評価用データセットに類似しすぎているデータセットでトレーニングした場合にも、パフォーマンス結果が影響を受けて歪む可能性があります。たとえば、ある質問応答データセットでトレーニングを行うと、モデルが別の質問応答データセットでより適切に機能するようになる場合があります。
このため、すべてのデータセットをタスクの種類ごとにグループ化し、データセットのトレーニングデータだけでなく、データセットが属するグループ全体を保持します。
データセットは以下のようにグループ化しました。
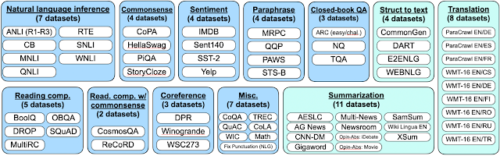
結果
FLANを25のタスクで評価したところ、4つを除くすべてのタスクでゼロショットプロンプトよりも改善されていることがわかりました。 結果は、25のタスクのうち20でゼロショット設定のGPT-3よりも優れており、一部のタスクでは小数ショット設定のGPT-3よりも優れていることがわかりました。
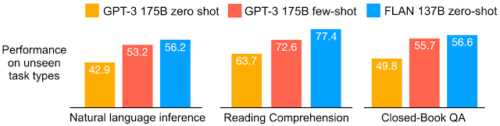
さまざまなモデルについて、タスクに関連するグループ内のすべてのデータセットでの平均精度を示します。
自然言語推論データセット:ANLI R1–R3、CB、およびRTE
読解データセット:BoolQ、MultiRC、OpenbookQA
クローズドブックQAデータセット:ARC、NQ、TriviaQA
また、モデルの規模は、モデルが指示調整から利益を得る能力にとって非常に重要であることがわかります。小規模モデルでは、FLANは実際にはパフォーマンスを低下させ、大規模モデルでのみ初めてのタスクに一般化できるようになります。これは、モデルが小さすぎると、多数のタスクを実行するのに十分なパラメーターがないことが原因である可能性があります。
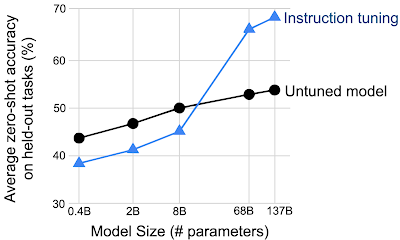
指示調整は、特定以上のサイズのモデルに関してのみ、見た事のないタスクのパフォーマンスを向上させます。
結論
FLANモデルは、一連の指示を使ってトレーニングする最初のモデルではありませんが、私たちの知る限り、この手法を大規模に適用した最初のモデルであり、モデルの一般化能力を向上できることを示しています。 私たちが提示した方法が、初めて見るタスクを実行し、ごくわずかなデータから学ぶことができるモデルのより多くの研究を刺激するのに役立つことを願っています。
また、他の研究者が結果を再現して構築できるように、変換を実行するためのコードをgithubで公開しました。
謝辞
Google Researchの協力者であるVincent Y. Zhao, Kelvin Guu, Adams Wei Yu, Brian Lester, Nan Du, Andrew M. Dai, そして Quoc V. Lに感謝します。
3.FLAN:指示調整により初見タスク実行能力を向上した言語モデル(2/2)関連リンク
1)ai.googleblog.com
Introducing FLAN: More generalizable Language Models with Instruction Fine-Tuning
2)arxiv.org
Finetuned Language Models Are Zero-Shot Learners
3)github.com
google-research / FLAN

