
1.データセンター内のBERTに匹敵する性能を持つPixel 6搭載の言語モデル(2/3)まとめ
・様々なタイプのIBNを含めた探索空間を構築しNASで画像像分類用のモデルを発見
・発見されたMobileNetEdgeTPUV2はCPU上でも他モデルを上回る性能を発揮
・セマンティックセグメンテーションや物体検出も大きく改善をしている
2.Pixel 6の画像処理機能
以下、ai.googleblog.comより「Improved On-Device ML on Pixel 6, with Neural Architecture Search」の意訳です。元記事は2021年11月8日、Suyog GuptaさんとMarie Whiteさんによる投稿です。
アイキャッチ画像のクレジットはPhoto by Shardar Tarikul Islam on Unsplash
より速く、より正確な画像分類
ディープニューラルネットワークのどの段階でどのIBN(Inverted Bottleneck)のバリエーションを使用するかは、ターゲットとなるハードウェア上の応答時間と、与えられたタスクに対するニューラルネットワークの性能に依存します。
私たちは、これらの異なるIBNバリエーションをすべて含む探索空間を構築し、NASを使用して、TPU上で所望の応答時間で分類精度を最適化する画像分類タスク用のニューラルネットワークを発見しました。
その結果、MobileNetEdgeTPUV2モデルファミリーは、TPU上で実行した場合、既存のオンデバイスモデルと比較して、与えられた応答時間での精度(または所望の精度での応答時間)を向上させます。また、MobileNetEdgeTPUV2は、前世代のTPU向けに設計された画像分類モデルであるMobileNetEdgeTPUを凌駕しています。
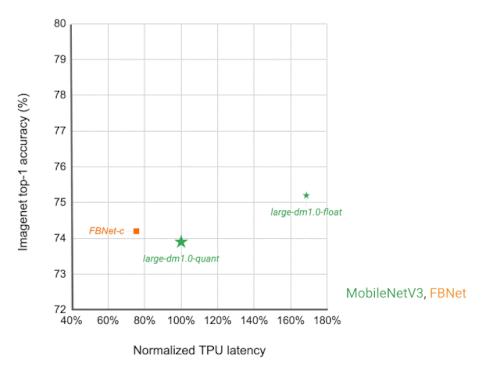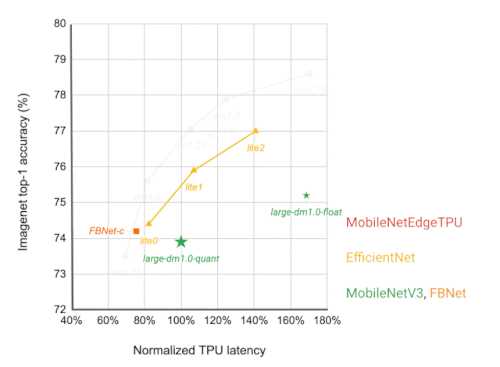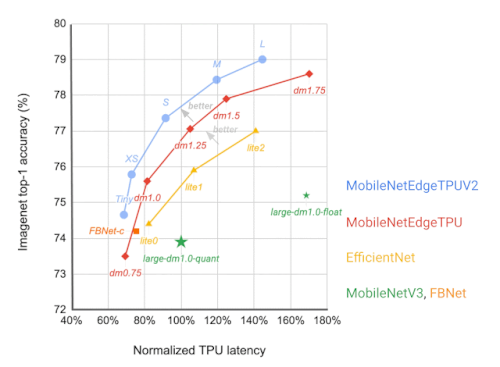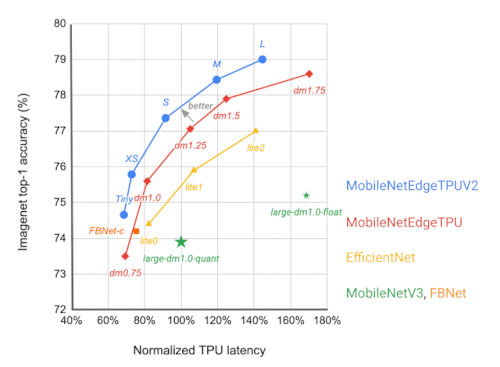
各ネットワーク・アーキテクチャは、異なる応答時間をターゲットにした点として視覚化されています。FBNet、MobileNetV3、EfficientNetsなどの他のモバイルモデルと比較して、MobileNetEdgeTPUV2モデルは、Google TensorのTPU上で実行した場合、より短い応答時間で高いImageNet top-1精度を達成しています。
MobileNetEdgeTPUV2モデルは、CPUなどのGoogle Tensor SoCの他の計算要素においても、応答時間と精度のトレードオフを改善する土台を使用して構築されています。
TPUなどのアクセラレータとは異なり、CPUはニューラルネットワーク内の乗算・積和演算の数と応答時間の間に強い相関関係を示します。GC-IBNはfused-IBNに比べて乗算・積算回数が少ない傾向にあり、Pixel 6のCPUでもMobileNetEdgeTPUV2が他のモデルを上回る結果となっている。
MobileNetEdgeTPUV2モデルは、Pixel 6のCPU上で、より短い応答時間でImageNetのtop-1精度を達成し、MobileNetV3などの他のCPUに最適化されたモデルアーキテクチャを凌駕しています。
オンデバイスでのセマンティックセグメンテーション性能の改善
多くの視覚ビジョンモデルは、2つの部品から構成されています。
「画像の一般的な特徴を理解するためのベースとなる特徴抽出器」と「セマンティックセグメンテーション(画像の各画素に空、車などのラベルを割り当てるタスク)や物体検出(画像内の猫、ドア、車などの物体の実体を検出するタスク)などの特定領域を対象とした特徴表現を理解するヘッド部」です。
これらの視覚タスクの特徴抽出器には、画像分類モデルがよく使われます。以下に示すように、MobileNetEdgeTPUV2分類モデルとDeepLabv3+のセグメンテーションヘッドを組み合わせることで、オンデバイスのセグメンテーションの品質が向上します。
セグメンテーションモデルの品質をさらに向上させるために、セグメンテーションヘッドとして双方向特徴ピラミッドネットワーク(BiFPN:BIdirectional Feature Pyramid Network)を使用し、特徴抽出器によって抽出された異なる特徴表現の重み付き融合を行います。
NASを用いて、特徴抽出器とBiFPNヘッドの両方の土台の最適な構成を見つけました。結果として得られた「Autoseg-EdgeTPU」と名付けられたモデルは、より高品質なセグメンテーション結果を得ることができ、さらに高速に動作するようになりました。
セグメンテーションモデルの最終層は、主に高解像度のセグメンテーションマップを生成するための演算により、全体の応答時間に大きく影響します。TPUでの応答時間を最適化するために、高解像度画像でのセグメンテーションマップを生成するための近似手法を導入しました。これにより、セグメンテーションの品質に大きな影響を与えることなく、必要なメモリ量を削減し、約1.5倍の高速化を実現しました。
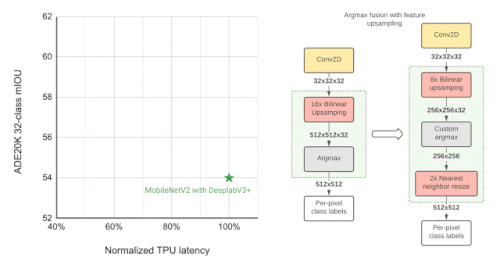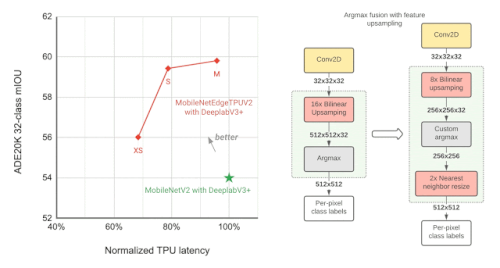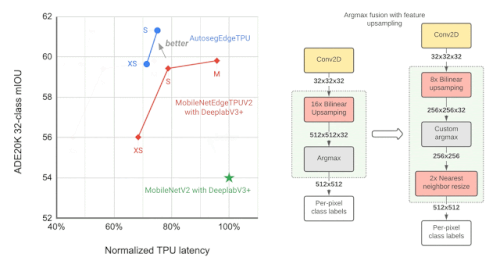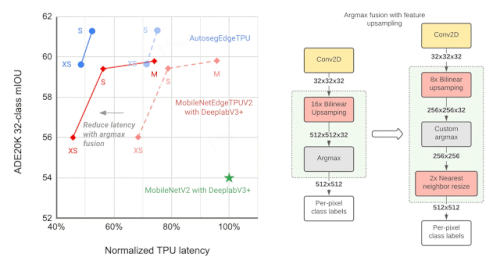
左:ADE20Kのセマンティック・セグメンテーション・データセット(上位31クラス)において、異なるセグメンテーション・モデルのパフォーマンス(mIOU:mean intersection-over-union)を測定して比較
右:近似的な特徴のアップサンプリング(例:解像度を32×32→512×512にする)。画素単位のラベルを計算するArgmax演算が、バイリニアアップサンプリング(bilinear upsampling)と融合しています。より小さい解像度の特徴でArgmaxを実行することで、品質に大きな影響を与えることなく、メモリ要件を減らし、TPUでの応答時間を向上させることができます。
高品質かつ低エネルギー消費の物体検出
従来の物体検出アーキテクチャでは、計算資源の約70%を特徴抽出部に、約30%を検出ヘッドに割り当てていました。このタスクでは、GC-IBNブロックを「スパゲティ探索空間(Spaghetti Search Space)」と呼ぶ探索空間に組み込み、より多くの計算資源をヘッドに割り当てる柔軟性を実現しています。この探索空間では、MnasFPNなどの最近のNASに見られる非自明な接続パターンを利用して、ネットワークの異なっているが関連するステージを統合し、理解を深めています。
3.データセンター内のBERTに匹敵する性能を持つPixel 6搭載の言語モデル(2/3)関連リンク
1)ai.googleblog.com
Improved On-Device ML on Pixel 6, with Neural Architecture Search
