
1.PSM:行動の類似性に着目して強化学習の一般化性能を改善(2/2)まとめ
・本研究は効果的な特徴表現を学習するために強化学習で固有構造を活用する利点を示した
・ポリシー類似性指標(PSM)と対照指標埋め込み(CME)の提唱によって強化学習の一般化を促進
・ポリシー類似性埋め込み(PSE)はPSMとCMEを組み合わせて、一般化を更に強化した
2.PSEとは?
以下、ai.googleblog.comより「Improving Generalization in Reinforcement Learning using Policy Similarity Embeddings」の意訳です。元記事の投稿は2021年9月29日、Rishabh Agarwalさんによる投稿です。
アイキャッチ画像のクレジットはPhoto by Bùi Thanh Tâm on Unsplash
一般化能力を強化するために、私たちのアプローチは「状態埋め込み(state embeddings)」を学習します。これは「タスクの状態」を「ニューラルネットワークベースの特徴表現」で対応したもので、動作的に類似した状態(前回の図など)を近くなるようにし、動作的に異なる状態を引き離す事を学習します。
これを行うために、状態類似性指標に基づいて特徴表現を学習するために対照学習の利点を活用する対照指標埋め込み(CME:Contrastive Metric Embeddings)を紹介します。
ポリシー類似性埋め込み(PSE:Policy Similarity Embeddings)を学習するために、ポリシー類似性指標(PSM)を使用して対照的な埋め込みを実体化します。PSEは、上の画像に示されている2つの初期状態など、これらの状態と将来の状態の両方で同様の動作をする状態に同様の特徴表現を割り当てます。
以下の結果に示すように、PSEは、前述の画素を用いたジャンプタスクの一般化を大幅に強化し、従来の手法よりも優れています。
| Method | Grid Configuration | ||
| “Wide” | “Narrow” | “Random” | |
| Regularization | 17.2 (2.2) | 10.2 (4.6) | 9.3 ( 5.4) |
| PSEs | 33.6 (10.0) | 9.3 (5.3) | 37.7 (10.4) |
| Data Augmentation | 50.7 (24.2) | 33.7 (11.8) | 71.3 (15.6) |
| Data Aug. + Bisimulation | 41.4 (17.6) | 17.4 (6.7) | 33.4 (15.6) |
| Data Aug. + PSEs | 87.0 (10.1) | 52.4 (5.8) | 83.4 (10.1) |
ジャンプタスクの結果
データ増強(Data Augmentation)の有無にかかわらず、さまざまな方法で解決されたテストタスクの割合(%)。「wide」、「narrow」、および「random」グリッドは、下の図に示す構成であり、18個のトレーニングタスクと268個のテストタスクが含まれています。括弧内に標準偏差を使用して、さまざまなランダム初期化を使用した100回の実行にわたる平均パフォーマンスを報告します。
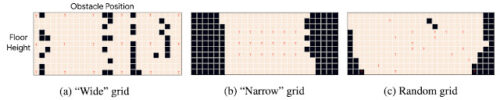
ジャンプタスクのグリッド構成
さまざまな構成にわたるデータ増強を使用したPSEの平均パフォーマンスの視覚化。グリッド構成ごとに、高さはy軸に沿って変化し(11段階の高さ)、障害物の位置はx軸に沿って変化します(26の位置)。 赤い文字Tは、トレーニングタスクを示します。ベージュのタイルはPSEが解決したタスクであり、黒のタイルは解決できなかったタスクです。データ増強と組み合わせています。
また、高次元データを視覚化する際に良く使われるUMAPを使用して、PSEとベースラインによって学習された特徴表現を二次元空間に投影することで視覚化します。視覚化によって示されるように、PSEは、以前の方法とは異なり、動作が類似した状態を一緒にクラスター化し、異なる状態を分離します。さらに、PSEは、状態を2つのセットに分割します。(1)ジャンプ前のすべての状態と(2)アクションが結果に影響を与えない状態(ジャンプ後の状態)です。
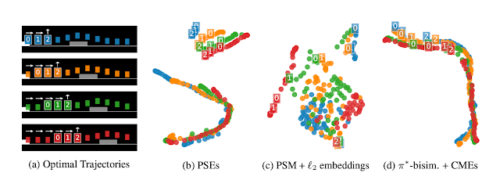
学習した特徴表現の視覚化
(a)さまざまな位置の障害物で実施したジャンプタスク(色付きのブロックとして視覚化)の最適な軌道。同じ番号ラベルのポイントは、障害物とエージェントの同じ距離に対応します。これは、さまざまなジャンプタスクにわたる基本的な最適な不変特徴です。
(b-d)UMAPを使用して隠れ特徴表現を視覚化します。ここで、点の色は対応する観測のタスクを示します。
(b)PSEは、同じ番号ラベルが一緒にクラスター化されている事からわかるように、不変特徴を正しく捕捉します。つまり、ジャンプアクション(番号付きブロックの2番)の後、他のすべてのアクション(番号なしブロック)は、重なり合う曲線で示されている事からも類似しています。PSEとは異なり、(c)l2損失の埋め込み(対照的な損失の代わりに使用)および(d)報酬ベースの双模倣指標(reward-based bisimulation metrics)を含むベースラインは、同様の番号ラベルを持つ動作的に類似した状態をまとめません。cとdの一般化が不十分なのは、互いに似ている最適動作が離れた埋め込み状態として学習されてしまう事が原因である可能性があります。
結論
全体として、この研究は、効果的な特徴表現を学習するために強化学習で固有の構造を活用することの利点を示しています。
具体的には、この研究は、ポリシー類似性指標(policy similarity metric)と対照指標埋め込み(contrastive metric embeddings)という2つの貢献によってRLの一般化を促進します。PSEは、これら2つのアイデアを組み合わせて、一般化を強化します。将来の研究のための刺激的な道は、行動の類似性を定義するためのより良い方法を見つけることと、特徴表現学習のためにこの構造を活用することを含みます。
謝辞
これは、ablo Samuel Castro, Marlos C. Machado and Marc G. Bellemareとの共同研究です。また、この研究について洞察に満ちたコメントを寄せてくれたDavid Ha, Ankit Anand, Alex Irpan, Rico Jonschkowski, Richard Song, Ofir Nachum, Dale Schuurmans, Aleksandra Faust そして Dibya Ghoshにも感謝します。
3.PSM:行動の類似性に着目して強化学習の一般化性能を改善(2/2)関連リンク
1)ai.googleblog.com
Improving Generalization in Reinforcement Learning using Policy Similarity Embeddings
2)agarwl.github.io
Contrastive Behavioral Similarity Embeddings for Generalization in Reinforcement Learning
3)github.com
google-research / jumping-task

