
1.Translatotron 2:音声間直接翻訳アプローチの品質を更に改良(2/2)まとめ
・翻訳前後で話者の声を保持するために同じ話者の声を使用してS2STモデルをトレーニングする
・多数のバイリンガルに協力して貰うのは難しいのでPnG NATで学習用データを作成した
・より難しいデータでTranslatotron2の性能はカスケードシステムに迫っている
2.Translatotron 2の性能
以下、ai.googleblog.comより「High-Quality, Robust and Responsible Direct Speech-to-Speech Translation」の意訳です。元記事は2021年9月23日、Ye JiaさんとMichelle Tadmor Ramanovichさんによる投稿です。
アイキャッチ画像のクレジットはPhoto by Miguel Henriques on Unsplash
翻訳前後で話者の声を保持するために、研究者は一般に、前後で同じ話者の声を使用して、並列発話でS2ST(Speech-to-Speech Translation)モデルをトレーニングすることを好みます。
2つの言語を喋れる人間の声がデータとして録音出来ている事が必要なこのようなデータセットは、流暢なバイリンガルスピーカーを多人数必要とするため、収集するのが非常に困難です。
この問題を回避するために、PnG NATの修正バージョンを使用します。これは、言語を超えた音声転送が可能なTTSモデルであり、このようなトレーニングターゲットを合成できます。
以下は、元の話者の音声が保持されているTranslatotron2を使った音声間音声翻訳の例です。
スペイン語の入力
英語のTTS-synthesized参照データ
英語のTranslatotron 2の予想
英語のTranslatotronの予想
入力音声内で複数の話者が順番に話している場合に、S2STモデルが翻訳された音声で各話者の声を保持できるようにするために、ConcatAugと呼ばれる単純な連結ベースのデータ拡張手法を提案します。
この手法は、トレーニング事例のペアをランダムにサンプリングし、翻訳元の発言、翻訳先の発言、および翻訳先の音素の並びを新しいトレーニング事例に連結することにより、直接トレーニングデータを拡張します。
結果のサンプルには、翻訳元の発言と翻訳先の発言の両方に2人の話者の声が含まれています。これにより、モデルは話者が順番に続く例を学習できます。以下は、話者が順番に話す際のTranslatotron2のオーディオサンプルです。
スペイン語の入力
英語のTTS-synthesized参照データ
英語のTranslatotron 2の予想(ConcatAugを使用)
英語のTranslatotron2の予想(ConcatAugを未使用)
その他のオーディオサンプルはgoogle-research.github.ioから入手できます。
パフォーマンス
Translatotron 2は、測定したすべての面で元のTranslatotronを大幅に上回っています。つまり、翻訳品質が高い(BLEUで測定、高いほど良い)、音声の自然さ(MOSで測定、高いほど良い)、音声の堅牢性(UDRで測定、低いほど優れている)です。
それは、より難しいフィッシャーコーパス(Fisher corpus、スペイン語-英語音声翻訳用データセット)で特に優れていました。翻訳品質と音声品質に関するTranslatotron2のパフォーマンスは、強力なベースラインであるカスケードシステムのパフォーマンスに近づき、音声の堅牢性に関するカスケードベースラインよりも優れています。
スペイン語と英語の2つの言語資料で評価された翻訳品質(BLEUで測定、高いほど良い)
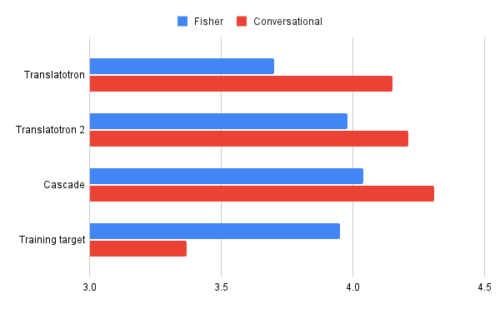
スペイン語と英語の2つの言語資料で評価された音声の自然さ(MOSで測定、高いほど良い)
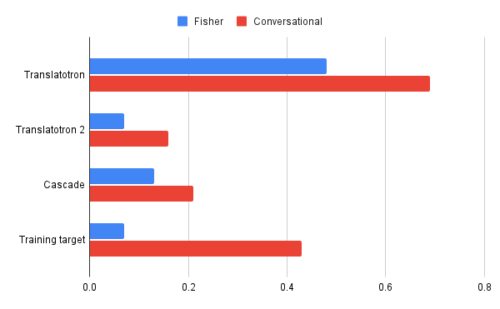
スペイン語と英語の2つの言語資料で評価された音声の堅牢性(UDRで測定、低いほど良い)
多言語の音声から音声への翻訳
スペイン語から英語へのS2STに加えて、モデルが4つの異なる言語から音声入力を受け取り、それらを英語に翻訳する多言語設定でのTranslatotron2のパフォーマンスも評価しました。
入力音声の言語が何語であるかは提供されなかったため、モデルはそれ自身で言語を検出する必要がありました。
| Source Language | fr | de | es | ca |
| Translatotron 2 | 27 | 18.8 | 27.7 | 22.5 |
| Translatotron | 18.9 | 10.8 | 18.8 | 13.9 |
| ST (Wang et al. 2020) | 27 | 18.9 | 28 | 23.9 |
| Training Target | 82.1 | 86 | 85.1 | 89.3 |
CoVoST 2言語資料での多言語X => En S2STのパフォーマンス。このタスクでも、Translatotron2は元のTranslatotronを大幅に上回りました。
この結果はS2ST(Speech-to-Speech Translation)とST(Speech-to-Text)間で直接比較できませんが、近い数値は、Translatotron 2の翻訳品質がベースラインのST翻訳モデルに匹敵することを示唆しています。これらの結果は、Translatotron2が多言語S2STでも非常に効果的であることを示しています。
謝辞
この研究の直接の貢献者には、Ye Jia, Michelle Tadmor Ramanovich, Tal Remez, Roi Pomerantzが含まれます。また、Chung-Cheng Chiu, Quan Wang, Heiga Zen, Ron J. Weiss, Wolfgang Macherey, Yu Zhang, Yonghui Wu, Hadar Shemtov, Ruoming Pang, Nadav Bar, Hen Fitoussi, Benny Schlesinger, Michael Hassidにも有益な議論とサポートを提供してくれたことに感謝します。
1.Translatotron 2:音声間直接翻訳アプローチの品質を更に改良(2/2)関連リンク
1)ai.googleblog.com
High-Quality, Robust and Responsible Direct Speech-to-Speech Translation
2)arxiv.org
Translatotron 2: Robust direct speech-to-speech translation
3)google-research.github.io
Audio samples from “Translatotron 2: Robust direct speech-to-speech translation”

