1.発声に困難を抱える人を自分自身の声で話せるようにする試み(1/2)まとめ
・ルー・ゲーリッグはALSで亡くなった野球選手で最も幸運な男というスピーチを行った
・ALSを発症して発声が困難になった元NFL選手がゲーリッグのスピーチを自声で再現
・声の再現を実現した技術であるPnG NATはPnG BERTとNATを組み合わせた最新モデル
2.ALSで失った自分の声を再現してスピーチを行う
以下、ai.googleblog.comより「Recreating Natural Voices for People with Speech Impairments」の意訳です。元記事は2021年8月30日、Ye JiaさんとJulie Cattiauさんによる投稿です。
アイキャッチ画像はカナダで行われたアイスバケツチャレンジ for ALSでクレジットはPhoto by Major Tom Agency on Unsplash
2021年6月2日、米国のメジャーリーグベースボールはルー・ゲーリッグ(Lou Gehrig)の日を祝い、ルー・ゲーリッグがヤンキースの一塁手になった1925年の日と、筋萎縮性側索硬化症(ALS:Amyotrophic Lateral Sclerosis、ルー・ゲーリッグ病としても知られています)で37歳で亡くなった1941年の日を記念しました。
ALSは進行性の神経変性疾患であり、脳と全身の筋肉をつなぐ運動ニューロンに影響を及ぼし、筋肉の制御と随意運動を支配します。自発的な筋肉の制御が影響を受けると、人々は話したり、食べたり、動かしたり、呼吸したりする能力を失う可能性があります。
ALSの擁護者であるルー・ゲーリッグに敬意を表して、ALSで話す能力を失った元NFLプレーヤーのスティーブ・グリーソン(Steve Gleason)は機械学習(ML:Machine Learning)モデルによって彼自身の声を再現し、6月2日のイベントでゲーリックの有名な「最も幸運な男(Luckiest Man)」のスピーチを引用しました。
グリーソンの音声の再現は、GoogleのProject Euphoniaと共同で開発されました。このプロジェクトは、ALSにより発話能力が低下した人々が、自分の声を使ってより良いコミュニケーションを行えるようにすることを目的としています。
本日は、スティーブ・グリーソンの声を再現するためにProject Euphoniaが採用したモデルであるPnG NATについて説明します。
PnG NATは、2つの最先端テクノロジーであるPnG BERTとNon-Attentive Tacotron(NAT)を1つのモデルに統合した、新しいテキスト読み上げ合成(TTS:Text-To-Speech synthesis)モデルです。これは、以前のテクノロジーよりも大幅に優れた品質と流暢さを示しており、より幅広いユーザーに拡張できる有望なアプローチを表しています。
声の再現
Non-Attentive Tacotron(NAT)は、2017年に提案されたシーケンス間ニューラルTTSモデルであるTacotron 2の後継です。Tacotron2は、Attentionモジュールを使用して、入力テキストシーケンスと出力音声スペクトログラムフレームシーケンスを接続しました。
モデルは、合成された音声スペクトログラムの各タイムステップを生成するときに、テキストのどの部分に注意を払うべきかを認識しています。Tacotron 2は、人が話すのと同じくらい自然に聞こえる音声を合成可能な最初のTTSモデルでした。ただし、広範な実験により、Attentionメカニズムの固有の柔軟性により、モデルがカタコト、繰り返し、スキップなどの一部のテキストに悩まされる堅牢性の問題が少しある事がわかりました。
NATは、Attentionモジュールを「継続時間ベースのアップサンプラー(duration-based upsampler)」に置き換えることでTacotron 2を改善します。このアップサンプラーは、各入力音素の継続時間を予測し、エンコードされた音素表現をアップサンプリングして、出力長が予測音声スペクトログラムの長さに対応するようにします。このような変更は、堅牢性の問題を解決し、合成された音声の自然さを向上させます。
このアプローチにより、非常に自然な合成品質を維持しながら、入力テキストの各音素の発話時間の正確な制御も可能になります。ALSの人の発声を録音する際はしばしば非流暢な発声になるため、音素ごとの制御を実行するこの機能は、再現された音声の流暢さを達成するための鍵となります。
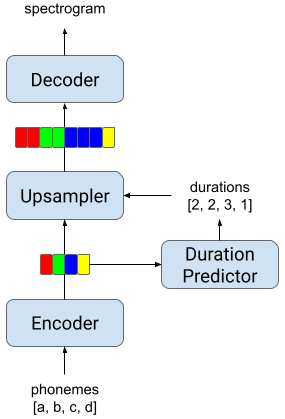
Non-Attentive Tacotron(NAT)モデルの概要
NATは堅牢性の問題に対処し、ニューラルTTSでの正確な継続時間制御を可能にしますが、それを基に、TTS入力の自然言語理解をさらに向上させます。このために、BERTと同様のアプローチを使用するPnG BERTを適用しますが、TTS用に特別に設計されています。
これは、大きなテキスト資料から得た同じコンテンツの音素表現と書記素表現の両方で自己教師手法で事前トレーニングされ、TTSモデルのエンコーダーとして使用されます。これにより、特に困難なケースで、合成された音声の韻律(prosody)と発音が大幅に改善されます。
3.発声に困難を抱える人を自分自身の声で話せるようにする試み(1/2)関連リンク
1)ai.googleblog.com
Recreating Natural Voices for People with Speech Impairments
2)sites.research.google
Project Euphonia
3)baseballhall.org
LUCKIEST MAN
4)www.youtube.com
The Age of A.I.

