
1.教師あり学習を使って外れ値を発見する(1/3)まとめ
・アノマリー検出、外れ値検出、分布外検出は欠陥品検出や不正取引検出など応用範囲が広い
・1クラスサポートベクターマシンは異常検出に良く使われるが最近の進歩の恩恵を受けていない
・自己教師特徴表現学習と古典的な1クラスアルゴリズムの2段階フレームワークを開発した
2.インライヤーとアウトライヤー
以下、ai.googleblog.comより「Discovering Anomalous Data with Self-Supervised Learning」の意訳です。元記事は2021年9月2日、Chun-Liang LiさんとKihyuk Sohnさんによる投稿です。
異常検出の話題が続きますが、今回のDeepな手法とBefore Deepな手法を組み合わせて「ある特定の1つのクラスに属しているか否か?」を判別する手法はかなり様々な分野で応用できそうですね。
今回、インライヤー(inliers)とアウトライヤー(outliers)と言う概念が出てくるのですが、英語圏でも使われ方が異なる事があるため要注意です。
今回の投稿では以下のような使われ方をしています
「犬の画像を分類したいときに犬画像群の中に混ざっている猫の画像はアウトライヤー(外れ値)で、犬の画像は全てインライヤー(通常値)です。」
しかし、以下のようなケースもあります。
「柴犬の画像を分類したいときに犬画像群の中に混ざっている猫の画像はアウトライヤー(外れ値)で、チワワの画像はインライヤー(アウトライヤーではないけれども、適正なデータではない)です。」
更に余談ですが、1万時間の法則(どんな才能や技量も、傑出した存在になるためには1万時間の練習が必要と言う説)を世に広めたマルコム・グラッドウェルの本(邦題:「天才! 成功する人々の法則」)の原題は「Outliers」で、外れ値というと負のイメージがありますが、平均的な分布から傑出した存在との意味合いでも使われたりもします。
アイキャッチ画像のクレジットはPhoto by Yan Laurichesse on Unsplash
異常検出(アノマリー検出(Anomaly detection)、外れ値検出(outlier detection)または分布外検出(out-of-distribution detection)と呼ばれることもあります)は、製造業における欠陥品検出から金融における不正取引検出まで、多くの領域で最も一般的な機械学習アプリケーションの1つです。
これは、既知の正常な例を大量に収集するのは簡単であっても、異常なデータがまれであり、見つけるのが難しい場合に最もよく使用されます。
そして、1クラスサポートベクターマシン(OC-SVM:One-Class Support Vector Machine)やサポートベクターデータ記述法(SVDD:Support Vector Data Description)などの1クラス分類は、トレーニングデータがすべて正常な例であると想定し、与えられたデータがトレーニングデータと同じ分布に属しているかどうかを識別する事を目的としているため、異常検出に特に関係があります。
残念ながら、これらの古典的なアルゴリズムは、機械学習を非常に強化する特徴表現学習の恩恵を受けていません。
一方、回転予測(rotation prediction)や対照学習(contrastive learning)などの自己教師あり学習を介して、ラベルのないデータから視覚的特徴表現を学習する手法は大幅に進歩しています。
そのため、1クラス分類器と、深層特徴表現学習におけるこれらの最近の成功を組み合わせることは、異常なデータを検出するために有望そうですが十分に検討されていません。
ICLR 2021で発表された「Learning and Evaluating Representations for Deep One-class Classification」では、自己教師特徴表現学習と古典的な1クラスアルゴリズムの最近の進歩を利用する2段階のフレームワークの概要を説明します。
アルゴリズムはトレーニングが簡単で、CIFAR、f-MNIST、Cat vs Dog、CelebAなどのさまざまなベンチマークで最先端のパフォーマンスを実現します。次に、CVPR 2021で発表された「CutPaste: Self-Supervised Learning for Anomaly Detection and Localization」でこれをフォローアップします。ここでは、現実的な産業界における欠陥品検出問題に対して同じフレームワークの下で新しい特徴表現学習アルゴリズムを提案します。このフレームワークは、MVTecベンチマークで新しい最先端のスコアを実現します。
深層1クラス分類のための2段階フレームワーク
エンドツーエンド学習(end-to-end learning)は、深層学習アルゴリズムの設計を含む多くの機械学習の問題で成功を収めていますが、深層1クラス分類器のこのようなアプローチは、モデルが入力に関係なく同じ結果を出力する縮退(degeneration)に悩まされることがよくあります。
これに対抗するために、2段階フレームワークを適用します。最初の段階では、モデルは自己教師によって深層特徴表現を学習します。第2段階では、第1段階で学習した特徴表現を使用して、OC-SVMやカーネル密度推定器などの1クラス分類アルゴリズムを採用します。
この2段階のアルゴリズムは、縮退に対して堅牢であるだけでなく、より正確な1クラス分類器を構築することもできます。さらに、このフレームワークは特定の特徴表現学習と1クラス分類アルゴリズムに限定されません。つまり、さまざまなアルゴリズムを簡単に組み合わせる事ができます。これは、先進的なアプローチが開発された時に役立ちます。
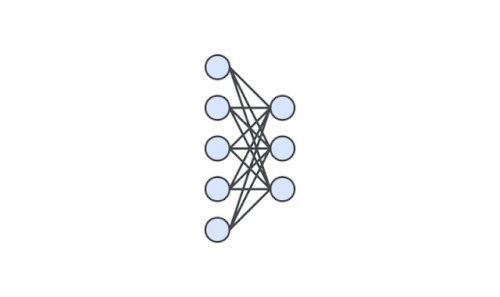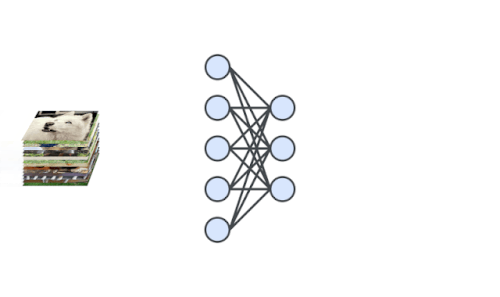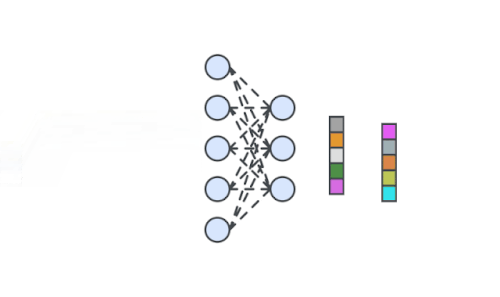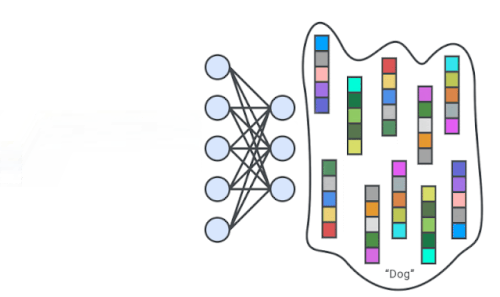
深層ニューラルネットワークは、自己教師学習で入力画像の特徴表現を生成するようにトレーニングされています。次に、学習した特徴表現を使って1クラス分類器をトレーニングします。
3.教師あり学習を使って外れ値を発見する(1/3)関連リンク
1)ai.googleblog.com
Discovering Anomalous Data with Self-Supervised Learning
2)arxiv.org
Learning and Evaluating Representations for Deep One-class Classification
CutPaste: Self-Supervised Learning for Anomaly Detection and Localization
Self-Trained One-class Classification for Unsupervised Anomaly Detection
3)github.com
google-research / deep_representation_one_class

