
1.SupCon:対照学習を教師有り学習に拡張(2/2)まとめ
・SupConは他の手法と比較して様々なデータセットでtop1精度を一貫して向上させる
・SupConはAutoAugment、RandAugment、およびCutMixを一貫して上回る
・SupConは教師あり分類の分野に技術的な進歩をもたらし精度と堅牢性を向上させる
2.SupConの性能
以下、ai.googleblog.comより「Extending Contrastive Learning to the Supervised Setting」の意訳です。元記事は2021年6月4日、AJ MaschinotさんとJenny Huangさんによる投稿です。
アイキャッチ画像のクレジットはPhoto by Ostap Senyuk on Unsplash
主な調査結果
SupConは、CIFAR-10、CIFAR-100、およびImageNetデータセットで、クロスエントロピー、マージン分類器(ラベルを使用)、および自己教師あり対照学習手法と比較して、top1精度を一貫して向上させます。
SupConを使用すると、ResNet-50およびResNet-200アーキテクチャを使用してImageNetデータセットで優れたtop1の精度を達成できます。 ResNet-200では、top1精度で81.4%を達成しました。これは、同じアーキテクチャを使用した最先端のクロスエントロピー損失手法よりも0.8%向上しています。(これはImageNetを使ったベンチマークでの大幅な進歩を表しています)。
また、TransformerベースのViT-B/16モデルでクロスエントロピーとSupConを比較したところ、クロスエントロピーよりも一貫して改善されていることがわかりました。(ImageNetでは77.8%対76%、CIFAR-10では92.6%対91.6%)。同じデータ水増し手法(高解像度の微調整なし)を使った結果です。
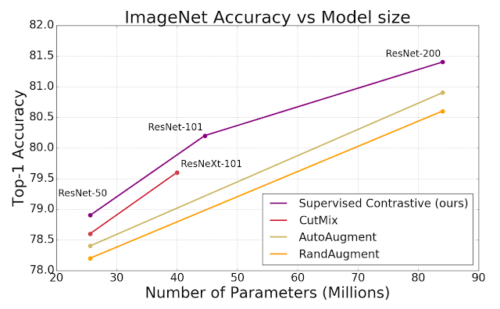
SupConの損失は、標準のデータ水増し戦略(AutoAugment、RandAugment、およびCutMix)を使用したクロスエントロピー損失を一貫して上回っています。ResNet-50、ResNet-101、ResNet200でのImageNetのtop1精度を示しています。
また、私達の損失関数の勾配がハードポジティブとハードネガティブからの学習を促進することを分析的に示します。ハードポジティブ/ネガティブからの勾配の寄与は大きく、イージーポジティブ/ネガティブからの勾配の寄与は小さいです。
この暗黙の特性により、対照的な損失により、明示的にハードマイニングする必要性を回避できます。これは、トリプレット損失など、多くの損失のデリケートですが重要な部分です。完全な定理展開については、私たちの論文の補足資料を参照してください。
SupConは、ノイズ、ブラー、JPEG圧縮などの自然な破損に対しても堅牢です。平均破損エラー (mCE:mean Corruption Error)は、ベンチマークとしたImageNet-C データセットと比較したパフォーマンスの平均的な低下を測定します。SupCon モデルは、クロスエントロピーモデルと比較して、さまざまな破損全体で mCE 値が低く、堅牢性の向上を示しています。
SupConの損失は、ハイパーパラメータの範囲に対してクロスエントロピーよりも感度が低いことを経験的に示しています。データ水増し、オプティマイザー、および学習率などを変化させても、対照的な損失の出力の分散は大幅に低くなっています。更に、他のすべてのハイパーパラメータを一定に保ちながら異なるバッチサイズを適用すると、各バッチサイズでのクロスエントロピーの精度よりもSupConのtop1精度が一貫して向上します。
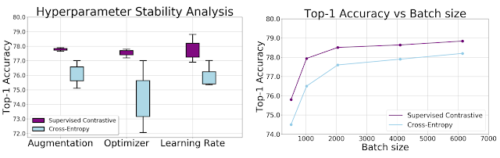
ResNet-50エンコーダーを使用してImageNetで測定された、クロスエントロピー損失と教師あり対照損失の精度。ハイパーパラメーターとトレーニングデータサイズの関係をグラフ化しています。
左:箱ひげ図は、top1精度と、画像水増し、オプティマイザー、および学習率の変化を示しています。SupConは、それぞれのバリエーション間でより一貫性のある結果を生成します。これは、最良の戦略が事前に不明な場合に役立ちます。
右: バッチ サイズの関数としてのtop1の精度は、両方の損失がバッチ サイズを大きくするとメリットがあることを示していますが、SupCon は小さいバッチ サイズでトレーニングした場合でもtop1 の精度が高いことを示しています。
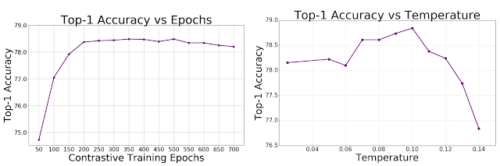
ResNet-50エンコーダーとImageNetで測定された、トレーニング期間と熱度(temperature)ハイパーパラメーターの関数としての教師あり対照損失の精度
左:SupConの事前トレーニングエポックの関数としてのTop1精度
右:SupConの事前トレーニング段階での熱度の関数としてのtop1精度。
熱度は対照学習における重要なハイパーパラメータであり、熱度に対する感度を下げることが望ましいです。
より広範な影響と次のステップ
本研究は、教師あり分類の分野で技術的な進歩をもたらします。教師あり対照学習は、最小限の複雑さで分類器の精度と堅牢性の両方を向上させることができます。
古典的なクロスエントロピー損失は、SupConの特殊ケースと見なすことができます。つまり、各視点が各画像に対応し、最終線形レイヤー内の学習したembeddingがラベルに対応するケースです。
SupConは大きなバッチサイズの恩恵を受けており、小さなバッチでモデルをトレーニングする事も可能であることは、将来の研究にとって重要なトピックであることに着目してください。
Githubリポジトリには、論文内のモデルをトレーニングするためのTensorflowコードが含まれています。事前トレーニングされたモデルは、TF-Hubでもリリースされます。
謝辞
NeurIPSの論文は、Prannay Khosla, Piotr Teterwak, Chen Wang, Aaron Sarna, Yonglong Tian, Phillip Isola, Aaron Maschinot, Ce Liu, Dilip Krishnanと共同で執筆しました。このブログ投稿の作成プロセスを主導してくれたJenny Huangに特に感謝します。
3.SupCon:対照学習を教師有り学習に拡張(2/2)関連リンク
1)ai.googleblog.com
Extending Contrastive Learning to the Supervised Setting
2)arxiv.org
Supervised Contrastive Learning
3)github.com
google-research/supcon/
4)tfhub.dev
supcon | TensorFlow Hub
