
1.Data Cascades:皆モデルの開発をやりたいのです!データ整備ではなく!(1/2)まとめ
・機械学習ではモデル構築が優先されデータ関連作業の優先度が低くなる事はよくある
・データ整備を軽視すると時間経過とともに技術的負債が発生し下流工程で問題が大きくなる
・データカスケードと呼ばれるこの問題はML開発の初期段階で発生する事がよくある
2.データカスケードとは?
以下、ai.googleblog.comより「Data Cascades in Machine Learning」の意訳です。元記事は2021年6月4日、Nithya Sambasivanさんによる投稿です。
データの重要性は様々なところで言及されているので、皆さんも「データサイエンティストの実際の仕事では作業全体の7~8割はデータの整備に費やされる」なんて話は聞いた事はあると思うのですが、現実世界でもデータが重視されていない事によって、品質の悪いデータが連続的に積み重なって(カスケード)いき、最終的に色々なところで弊害が発生してコストになりますよ、というお話です。
タイトルは元論文のタイトルの意訳ですが、確かにデータ整備は重要ではあっても花形キャリアとは見なされないでしょうから、自然と後回しにされたりコスト削減対象となる傾向はあるよなぁと思います。
カスケードは何段も連なった小さな滝の意味もあるらしいので、そこから連想したアイキャッチ画像のクレジットはPhoto by Joe Green on Unsplash
データは機械学習(ML:Machine Learning)の基盤であり、MLシステムのパフォーマンス、公平性、堅牢性、規模拡張性に影響を与える可能性があります。逆説的ですが、MLにおいてはモデルの構築の優先度が高くなり、データ自体に関連する作業は優先度が最も低くなる事がよくあります。
データに関する作業には複数の役割(データ収集者、注釈付与作業者、ML 開発者など)が必要になる場合があり、多くの場合、データ インフラストラクチャを強化するために複数のチーム(データベース、法務、ライセンス チームなど)が関与するため、データ関連のプロジェクトは複雑になります。
このような状況を踏まえると、テクノロジーを人々にとって有用で使いやすいものにすることに焦点を当てたヒューマン・コンピューター・インタラクション(HCI:Human-Computer Interaction)の分野は、潜在的な問題を特定し、データ関連の作業が優先されない場合のモデルへの影響を評価するのに役立ちます。
2021 ACM CHI カンファレンスで発表された「Everyone wants to do the model work, not the data work: Data Cascades in High-Stakes AI」では、時間の経過とともに技術的負債をもたらすデータ問題の下流工程への影響を調査し、検証します。 (これを「データ カスケード(Data Cascades)」として定義します)。
具体的には、癌の検出、地滑りの検出、ローンの割り当てなど、重要な機械学習を扱う領域で働く世界中のML実務家のデータに関する実務と、課題を伴うデータ カスケード現象を示します。つまり、ML システムが進歩を可能にした領域だけでなく、データ カスケードに対処することで改善する機会がある領域を扱っています。
本研究は、現実世界のプロジェクトに適用される ML のデータ カスケードを定式化、測定、および議論する最初の研究です。更に、ML データを優先度の高いものとして全員で想像しなおす事によって提示される好機を議論します。
これには、
・ML データ作業とワーカーへの報酬
・MLのデータ研究における科学的経験主義の価値を認識する事
・データ パイプラインの可視性の改善
・世界中のデータの公平性の改善
が含まれます。
データ カスケードの起源
データ カスケードは、ML システムのライフサイクルの早い段階、つまりデータの定義と収集の段階で発生することがよくあります。
また、カスケードは診断や症状の発現が複雑で不透明な傾向があるため、その影響を検出して測定するための明確な指標、ツール、または指標がないことがよくあります。このため、データ関連の小さな障害が、モデルの開発および展開方法に影響を与える、より大きく複雑な課題に発展する可能性があります。
データ カスケードの課題には、開発プロセスのかなり後の段階でコストのかかるシステム レベルの変更を実行する必要があることや、データの問題に起因するモデルの予測の誤りによるユーザーの信頼の低下が含まれます。それにもかかわらず、励みにもなりますが、このようなデータのカスケードは、ML 開発時に早期介入する事によって回避できることも観察しています。
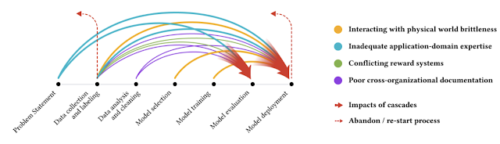
さまざまな色の矢印は、さまざまなタイプのデータ カスケードを示しています。これらは通常、上流工程で発生し、ML 開発プロセス時に悪化し、下流工程で出現します。
データ カスケードの具体例
データ カスケードの最も一般的な原因の 1 つは、ノイズがないデータセットでトレーニングされたモデルが、ノイズの多い現実世界で使用される場合です。
例えば、良くあるタイプのデータ カスケードは、ターゲット変数と独立変数がずれたときに発生する「モデル ドリフト(model drifts、モデルの漂流)」に起因します。これにより、モデルの精度が低下します。
モデルが新たにデジタル機器を導入する環境と密接に相互作用する場合、モデルドリフトはより一般的になります。これには、大気質センシング、海洋センシング、超音波スキャンなどの重要な領域が含まれます。何故なら、これらの環境には既存および/または精選されたデータセットがないためです。
このようなドリフトは、モデルのパフォーマンスをさらに低下させるより多くの要因(例えば、ハードウェア、環境、および人間の知識に関する)につながる可能性があります。
例えば、モデルのパフォーマンスを優れたものにするために、データは制御された社内環境で収集されることがよくあります。
しかし、リソースの制約がある新たにデジタル機器が導入される現実のライブ システムでは、指紋、影、ほこり、不適切な照明、ペンによる印などの物理的な人工物と共にデータが収集される事が一般的であり、モデルのパフォーマンスに影響を与えるノイズが追加される可能性があります。
場合によっては、雨や風などの環境要因によってイメージ センサーが開発中に予期せず移動し、カスケードが発生する場合もあります。インタビューしたモデル開発者の 1 人が報告したように、わずかな油シミや水滴でも、がん予測モデルのトレーニングに使用できるデータに影響を与える可能性があり、従って、モデルのパフォーマンスに影響します。
ドリフトは現実世界の環境のノイズによって引き起こされることも多いため、その場合、ドリフト顕在化までにかなり時間がかかることもあります。最長 2 ~ 3 年、ほとんどの場合、 顕在化した頃にはモデルは実稼働中です。
3.Data Cascades:皆モデルの開発をやりたいのです!データ整備ではなく!(1/2)関連リンク
1)ai.googleblog.com
Data Cascades in Machine Learning
2)research.google
“Everyone wants to do the model work, not the data work”: Data Cascades in High-Stakes AI

