
1.FELIX:タグ付けと挿入を使う効率的で柔軟なテキスト編集モデル(2/2)まとめ
・FELIXは完全に非自己回帰であり最先端のスコアを達成しながら高速な推論を実現可能
・事前トレーニングとマスク言語モデルを念頭に必要なトレーニングデータの量を削減
・FELIXは文の融合、テキストの簡略化、抽象要約、機械翻訳の事後編集で非常に高速に動作
2.FELIXの性能
以下、ai.googleblog.comより「Introducing FELIX: Flexible Text Editing Through Tagging and Insertion」の意訳です。元記事の投稿は2021年5月5日、Jonathan MallinsonさんとAliaksei Severynさんによる投稿です。
アイキャッチ画像のクレジットはPhoto by Nicolas Savignat on Unsplash
タグ付けモデル
FELIXの最初のステップは、2つの部品で構成されるタグ付けモデルです。まず、タガー(tagger)は、保持または削除する単語と、新しい単語を挿入する場所を決定します。タガーが挿入を予測すると、特別なMASKトークンが出力に追加されます。タグ付け後、ポインタが入力を並べ替えて出力を形成する並べ替え手順があります。これにより、新しいテキストを挿入する代わりに、入力の一部を再利用できます。並べ替え手順では、任意の書き換えがサポートされているため、大きな変更をモデル化できます。ポインタネットワークは、以下に示すように、入力の各単語が出力に表示される次の単語を指すようにトレーニングされています。

「心臓の壁は3層あります(There are 3 layers in the walls of the heart)」を「心臓<マスク>3層」に変換するポインティングメカニズムの実現
挿入モデル
タグ付けモデルからは、一部の単語が削除され、並べ替えられた入力テキストが出力されます。
入力テキスト内には内容が隠されたマスクトークンが含まれるため、挿入モデルは、マスクトークンの内容を予測する必要があります。FELIXの挿入モデルはBERTの事前トレーニングの目的と非常に似ているため、事前トレーニングを直接利用できます。これは、データが限られている場合に特に有利です。

挿入モデルの例。タガー(tagger)が2つの単語が挿入されることを予測し、挿入モデルがMASKトークンの内容を予測します。
結果
私達はFELIXを、文の融合、テキストの簡略化、抽象要約(Abstractive summarization、要約とは長い文章のなから必要な部分を抽出(Extractive)する作業と長い文章を抽象化(Abstractive)する作業に分けて考える事が出来るが、Extractive summarizationはもうかなりやりつくされたと考えられており、Abstractive summarizationの方が主要な研究対象手法となっている)、機械翻訳の事後編集について評価しました。これらのタスクは、必要な編集の種類と、それらが動作するデータセットのサイズが大きく異なります。
以下は、様々なデータセットサイズで、FELIXの事前にトレーニングされた大規模なseq2seqモデル(BERT2BERT)およびテキスト編集モデル(LaserTager)と比較した、センテンスフュージョンタスク(つまり、2つの文を1つに併合する)の結果です。 FELIXはLaserTaggerよりも優れており、わずか数百のトレーニング例でトレーニングできることがわかります。完全なデータセットの場合、自己回帰BERT2BERTはFELIXよりも優れています。ただし、このモデルは推論にかなり長い時間がかかります。
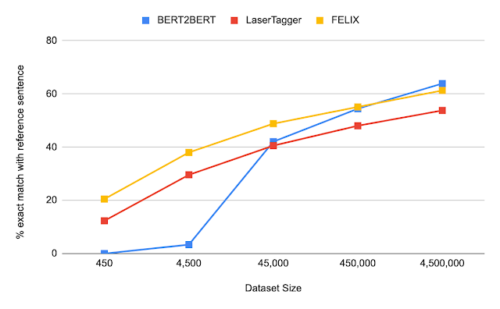
DiscoFuseデータセットのさまざまなトレーニングデータセットサイズの比較。 FELIX(最高のパフォーマンスを出したモデルを使用)をBERT2BERTおよびLaserTaggerと比較します。
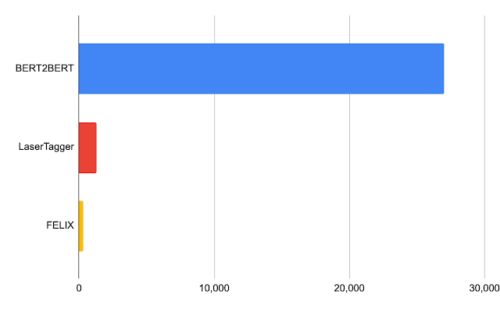
Nvidia TeslaP100を使った32バッチの処理時間(ミリ秒単位)
結論
完全に非自己回帰であり、最先端の結果を達成しながら、さらに高速な推論を提供するFELIXを紹介しました。FELIXはまた、事前トレーニングされたチェックポイントの微調整、少数の編集操作の学習、事前トレーニングからマスク言語モデルタスクを模倣する挿入タスクの3つの手法を使用して、必要なトレーニングデータの量を最小限に抑えます。
最後に、FELIXは、学習した編集操作の複雑さと、処理できる入出力変換の割合のバランスを取ります。FELIXのコードをオープンソース化し、研究者に、より速く、より効率的で、より柔軟なテキスト編集モデルを提供できる事を願っています。
謝辞
この研究は、Jonathan Mallinson, Aliaksei Severyn(同等の貢献), Aleksandr Chuklin, Daniil Mirylenka, Ryan McDonald, そして Sebastian の有益な議論、初期の実験の実行、論文に関する提案に感謝します。
3.FELIX:タグ付けと挿入を使う効率的で柔軟なテキスト編集モデル(2/2)関連リンク
1)ai.googleblog.com
Introducing FELIX: Flexible Text Editing Through Tagging and Insertion
2)www.aclweb.org
FELIX: Flexible Text Editing Through Tagging and Insertion
3)github.com
google-research/felix/

