
1.ViP-DeepLab:深度推定とパノプティックセグメンテーションを動画に対して同時に適用(2/2)
・Panoptic-DeepLabは複数フレームにおける深度推定やインスタンスID付与ができない
・ViP-DeepLabは2つの連続するフレームに追加の予測を実行することでこれを実現
・動画のパノプティックセグメンテーション、単眼深度推定などでSOTAを実現
2.ViP-DeepLabの性能
以下、ai.googleblog.comより「Holistic Video Scene Understanding with ViP-DeepLab」の意訳です。元記事の投稿は2021年4月27日、Siyuan QiaoさんとLiang-Chieh Chenさんによる投稿です。
アイキャッチ画像のクレジットはPhoto by lucas Favre on Unsplash
概要
Panoptic-DeepLabは、単一フレームのセマンティックセグメンテーション、中心予測、および中心回帰を出力できますが、複数フレームにおける深度推定と時間の経過に関わらず一貫したインスタンスIDを付与する機能がありません。
しかしながら、ViP-DeepLabは、入力として2つの連続するフレームに追加の予測を実行することでこれを実現します。最初の追加出力は、最初のフレームの深度推定であり、各ピクセルに推定深度が割り当てられます。
更に、ViP-DeepLabは、最初のフレームに表示される物体の中心に対してのみ、2つの連続するフレームの中心の予測を行います。このプロセスはセンターオフセット予測と呼ばれ、ViP-DeepLabが2つのフレームの全ての画素を最初のフレームに表示される同じ物体にグループ化できるようにします。
以前に検出された実体にグループ化されていない場合、新しい実体が出現します。このプロセスは、ビデオシーケンス内の2つの連続するフレーム(1つのオーバーラップフレームを含む)毎に続行され、パノプティック予測をつなぎ合わせて、時間的に一貫したインスタンスIDを持つ予測を形成します。
つまり、物体がどこにあるか、および物体がビデオシーンで時間とともにどのように移動するかをつなぎ合わせます。

ビデオパノプティックセグメンテーションのためのViP-DeepLabの出力
2つの連続するフレームが入力として連結されます。セマンティックセグメンテーション出力は、各画素をそのセマンティッククラスに関連付けますが、インスタンスセグメンテーション出力は、最初のフレームの個々の物体に関連付けられた2つのフレームから画素を識別します。入力画像はCityscapesデータセットからのものです。
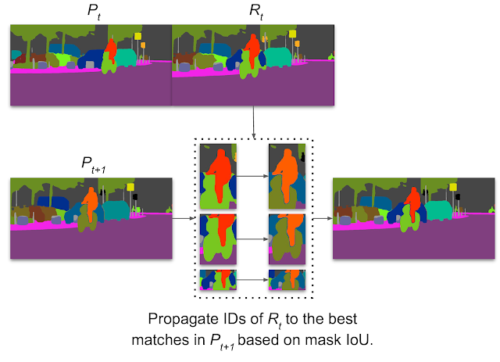
スティッチングビデオパノプティック(stitching video panoptic)予測の視覚化
ViP-DeepLabは、リージョンペア間のマスク交差オーバーユニオンに基づいてIDを伝播します。画像内の自転車乗りなど、動きの大きい物体を追跡できます。
ニューラルネットワークの設計
Panoptic-DeepLabの上に構築されたViP-DeepLabには、さらに2つの予測ブランチが含まれています。
(1)深度予測ブランチ
(2)次フレームインスタンスブランチ
です。
具体的には、深度予測ヘッドは、すべての画素の深度回帰を予測する単純な設計ですが、次フレームインスタンスブランチは、最初のフレームの中心に対する2番目のフレームの画素の中心オフセットを予測します。
結果
ViP-DeepLabは、Cityscapes-VPS、KITTI Depth Prediction、KITTI Multi-Object Tracking and Segmentation(MOTS)など、複数の一般的なベンチマークでテストされています。
具体的には、ViP-DeepLabは最先端の(SOTA)結果を達成し、Cityscapes-VPSテストセットで5.1%のビデオパノプティック品質(VPQ)を達成する事によって従来の方法を大幅に上回っています。
| Method | VPQAll | VPQThings | VPQStuff |
| VPSNet | 57.40% | 45.80% | 64.80% |
| ViP-DeepLab | 62.5% (+5.1%) | 50.2% (+4.4%) | 70.3% (+5.5%) |
Cityscapes-VPSテストセットでのVPQ比較。
ViP-DeepLabは、KITTI深度予測ベンチマークで1位にランクされました。従来の手法より0.65 SILog向上しています(数値が小さいほど良い性能を意味しています)。
| Method | SILog | sqErrorRel | absErrorRel | iRMSE |
| PWA | 11.45 | 2.3 | 9.05 | 12.32 |
| ViP-DeepLab | 10.8 | 2.19 | 8.94 | 11.77 |
KITTI深度予測ベンチマークでの単眼深度推定の比較
深度推定基準については、値が小さいほどパフォーマンスの向上を意味することに注意してください。違いは小さいように見えるかもしれませんが、このベンチマークで最もパフォーマンスの高い手法間では、通常、SILogの差分は0.1未満となります。
更に、ViP-DeepLabは、sMOTSA基準でランク付けされた際にKITTI MOTS歩行者で1位、KITTI MOTS車で3位でした。そして現在、歩行者と新しい評価基準HOTAでランク付けされた際には歩行者と車の両方で3位になりました。
| Class | Method | HOTA |
| Car | PointTrack | 62.00% |
| ViP-DeepLab | 76.4% (+14.4%) | |
| Pedestrian | PointTrack | 54.40% |
| ViP-DeepLab | 64.3% (+9.9%) |
KITTIマルチオブジェクトトラッキングとセグメンテーションのパフォーマンス比較。
最後に、新しいタスク用の2つの新しいデータセット、深度認識ビデオパノプティックセグメンテーションを提示し、それらでViP-DeepLabをテストします。これら2つの新しいデータセットでのViP-DeepLabの結果が、コミュニティが比較対象とする強力な基準として役立つことを願っています。
結果を以下に示します。
| Dataset | DVPQAll | DVPQThings | DVPQStuff |
| Cityscapes-DVPS | 55.10% | 43.30% | 63.60% |
| SemKITTI-DVPS | 45.60% | 36.60% | 52.20% |
2つの新しいデータセットにおける深度認識ビデオパノプティックセグメンテーションタスクに対するViP-DeepLabのパフォーマンス
結論
シンプルな設計で、ViP-DeepLabは、ビデオパノプティックセグメンテーション、単眼深度推定、および複数物体の追跡とセグメンテーションで最先端のパフォーマンスを実現します。
画像パノプティックセグメンテーションの直接実行を可能にする効率的なデュアルパストランスモジュールを提案するMaX-DeepLabとともに期待しています。ViP-DeepLabはコミュニティに役立ち、現実世界のシーンをより包括的に理解するための研究を促進します。
謝辞
ukun Zhu, Hartwig Adam, Alan Yuille(ViP-DeepLabの共著者)、Maxwell Collins、およびMobileVisionチームとのサポートと貴重な議論に感謝します。
3.ViP-DeepLab:深度推定とパノプティックセグメンテーションを動画に対して同時に適用(2/2)関連リンク
1)ai.googleblog.com
Holistic Video Scene Understanding with ViP-DeepLab
2)arxiv.org
ViP-DeepLab: Learning Visual Perception with Depth-aware Video Panoptic Segmentation

