
1.PAIRED:3つのエージェントを使って強化学習の効率を向上(1/2)まとめ
・強化学習でシミュレートされたトレーニング環境を利用するケースが近年増加している
・シミュレート環境の弱点は作成される環境が多様性を欠く事であり環境の自動構築が必要
・従来手法は解法がない環境を作り出すなどの問題がありPAIREDはこれを解決した
2.PAIREDとは?
以下、ai.googleblog.comより「PAIRED: A New Multi-agent Approach for Adversarial Environment Generation」の意訳です。元記事の投稿は2021年3月5日、Natasha JaquesさんとMichael Dennisさんによる投稿です。
アイキャッチ画像のクレジットはPhoto by Juliana Amorim on Unsplash
機械学習の有効性は、そのトレーニングデータに大きく依存しています。
強化学習(RL:Reinforcement Learning)の場合、現実世界で実際に動かしたエージェントによって収集された限られたデータ、または必要なだけのデータを収集可能なシミュレートされたトレーニング環境から得たデータのいずれかに依存できます。
シミュレーションでトレーニングするこの後者の手法はますます一般的になっていますが、問題があります。RLエージェントはシミュレータに組み込まれているものを学習できますが、シミュレーション環境とは少しでも異なるタスクに一般化する事は苦手です。そして明らかに、現実世界のすべての複雑さをカバーするシミュレーターを構築することは非常に困難です。
これに対処するためのアプローチの1つは、シミュレーターの全てのパラメーターをランダム化することにより、より多様なトレーニング環境を自動的に作成することです。これは、ドメインのランダム化(DR:Domain Randomization)と呼ばれるプロセスです。ただし、DRは非常に単純な環境でも失敗する可能性があります。
例えば、以下のアニメーションでは、青いエージェントが緑の目標に移動しようとしています。左側のパネルは、障害物とゴールの位置がランダム化されたDRで作成された環境を示しています。これらのDR環境の多くは、エージェントのトレーニングに使用され、これを使って訓練されたエージェントは中央図の単純な四つの部屋がある環境に転送されます。エージェントが目標を見つけられないことに注意してください。これは、壁を伝って歩き回ることを学んでいないためです。
四つの部屋が存在するこの部屋構成は、ランダムに部屋を生成するDRトレーニングフェーズ中に生成される可能性はありますが、あまり期待できません。その結果、エージェントは四部屋構造と同様の部屋構成で十分なトレーニングを行う事が出来ておらず、目標を達成することができません。
ドメインのランダム化(左)は、4つ部屋のシナリオ(中央)など、今まで見た事のない環境に転送されても対応出来るようにエージェントを効果的に学習させる事が出来ません。これに対処するために、ミニマックス敵対法(Minimax Adversary)は未見の環境を構築するために使用されますが、解決することが不可能な環境(右)を作り出す可能性があります。
環境パラメーターをランダム化するだけでなく、第二のRLエージェントをトレーニングして、環境パラメーターの設定方法を学習させる事もできます。このミニマックス敵対法は、ポリシーの弱点を見つけて悪用することにより、第一のRLエージェントのパフォーマンスを最小限に抑える事を目的にトレーニングされます。例えば、これまでに第一のRLエージェントが遭遇したことのないような構成の部屋を生成する事などでこれを達成しようとします
しかし、ここでも問題があります。 上図の右端のパネルは、ミニマックス敵対法によって構築された環境を示しています。この環境では、エージェントが目標を達成することは実際には不可能です。ミニマックス敵対法はその目的を達成しましたが(第一のエージェントのパフォーマンスを最小限に抑えました)、エージェントが学習する機会を提供していません。純粋に敵対的な目的を使用することも、トレーニング環境を生成するのにはあまり適していません。
カリフォルニア大学バークレー校と共同で、NeurIPS 2020で最近発表された出版物である「Emergent Complexity and Zero-shot Transfer via Unsupervised Environment Design」では敵対的に訓練するための新しいマルチエージェントアプローチを提案します。
本研究では「PAIRED(Protagonist Antagonist Induced Regret Environment Design、競争者の後悔を誘発する環境デザイン)」アルゴリズムを紹介します。これは、ミニマックス法の反省に基づいており、エージェントのポリシーの弱点を修正できるようにしながら、敵対者が解決不可能な環境を作成するのを防ぎます。
PAIREDは、生成する環境の難易度をエージェントの現在の能力を少しだけ超える難度に調整するように敵対者を動機付け、次第に困難になるトレーニングタスクのカリキュラムを自動で作成するようにさせます。PAIREDでトレーニングされたエージェントは、より複雑な動作を学習し、未知のテストタスクによりよく一般化することを示します。 GitHubリポジトリでPAIREDのオープンソースコードを公開しています。
PAIRED
敵対者を柔軟に制限するために、PAIREDは3番目のRLエージェントを導入します。これは、敵対的エージェント、つまり環境を設計するエージェントと連携しているため、「競争者(Antagonist)」エージェントと呼ばれます。
最初のエージェント、つまり環境を探索するエージェントの名前を「主人公(Protagonist)」に変更します。敵対者(Adversary)が環境を生成すると、主人公と競争者の両方がその環境を介してプレイします。
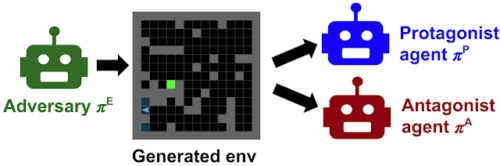
敵対者の仕事は、主人公の報酬を最小限に抑えながら、競争者の報酬を最大化することです。これは、実行可能であるが(競争者がそれらを解決して高得点を得ることができるため)、主人公にとって挑戦的な(現在のポリシーの弱点を悪用する)環境を作成する必要があることを意味します。2つの報酬のギャップは後悔です。敵対者は後悔(regret)を最大化しようとしますが、主人公はそれを最小化しようとし、競い合います。
3.PAIRED:3つのエージェントを使って強化学習の効率を向上(1/2)関連リンク
1)ai.googleblog.com
PAIRED: A New Multi-agent Approach for Adversarial Environment Generation
2)arxiv.org
Emergent Complexity and Zero-shot Transfer via Unsupervised Environment Design
Adversarial Environment Generation for Learning to Navigate the Web
3)github.com
google-research/social_rl/adversarial_env/

