
1.ToTTo:表から文を抽出する能力を測るためのデータセット(2/2)まとめ
・最もパフォーマンスの高いモデルであっても約20%の確率で情報を幻覚化するように見える
・最先端のモデルでも幻覚、数値的推論、および稀なトピックに苦労している事がわかった
・モデルの出力が正しい場合でも元の情報にあった有益な情報が失われてしまう場合がある
2.ToTToを使った性能評価
以下、ai.googleblog.comより「ToTTo: A Controlled Table-to-Text Generation Dataset」の意訳です。元記事の投稿は2021年1月15日、Ankur ParikhさんとXuezhi Wangさんによる投稿です。
アイキャッチ画像のクレジットはPhoto by Juan Encalada on Unsplash
データセットの分析
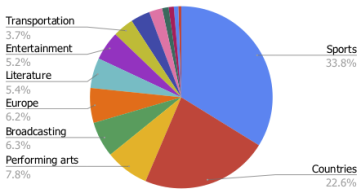
44のカテゴリにわたるToTToデータセットでトピック分析を行ったところ、以下の事がわかりました。
スポーツと世界各国のトピックがデータセットの56.4%を占めています。 それぞれが、サッカー/オリンピック競技や国の人口/建物など、さまざまなきめ細かいトピックで構成されており、残りの44%は、舞台芸術、交通機関、娯楽など、はるかに幅広いトピックで構成されています。
更に、ランダムに選択された100を超える事例を使用して、データセット内の様々なタイプの言語現象を手動で分析しました。
以下の表は、ページとセクションのタイトルへの参照が必要な例の一部と、現在のシステムに新たな課題をもたらす可能性のあるデータセット内のいくつかの言語現象をまとめたものです。
| 言語現象 | 割合 |
| ページタイトルへの参照が必要 | 82% |
| セクションタイトルへの参照が必要 | 19% |
| 表の説明への参照が必要 | 3% |
| 推論が必要(論理的、数値的、時間的など) | 21% |
| 行/列/セル間の比較が必要 | 13% |
| 背景情報が必要 | 12% |
比較結果
2つの評価指標、BLEUとPARENTについて、文献から3つの最先端モデル(BERT-to-BERT、Pointer Generator、およびPuduppully 2019モデル)の比較結果をいくつか示します。
テストセット全体のスコアに加えて、専門領域外の事例で構成されるより困難なサブセットで各モデルを評価しました。
次の表に示すように、BERT-to-BERTモデルは、BLEUとPARENTの両評価指標で最高のパフォーマンスを発揮しました。更に、全てのモデルは、専門領域外の一般化の課題を示すchallengeセットでかなり低いパフォーマンスになりました。
| Model | BLEU(overall) | PARENT(overall) | BLEU(challenge) | PARENT(challenge) |
| BERT-to-BERT | 43.9 | 52.6 | 34.8 | 46.7 |
| Pointer Generator | 41.6 | 51.6 | 32.2 | 45.2 |
| Puduppully et al. 2019 | 19.2 | 29.2 | 13.9 | 25.8 |
人の手を介さずに自動で評価できる指標はパフォーマンスをある程度測る事ができますが、テキスト生成システムの幻覚(hallucination)を評価するには十分ではありません。
幻覚をよりよく理解するために、不一致が幻覚を示しているという仮定の下で、パフォーマンスの高いベースラインを手動で評価し、元テーブルのコンテンツにどれだけ忠実であるかを判断しました。
専門家(Expert)のパフォーマンスを計算するために、マルチリファレンステストセットの各例について、1つのリファレンスを抽出して、注釈付け作業者に他のリファレンスと忠実に比較するように依頼しました。結果が示すように、最もパフォーマンスの高いモデルであっても約20%の確率で情報を幻覚化してしまうように見えます。
| Model | Faithfulness(overall) | Faithfulness(challenge) |
| Expert | 93.6 | 91.4 |
| BERT-to-BERT | 76.2 | 74.2 |
モデルのエラーと課題
以下の表では、ToTToデータセットのより困難な側面のいくつかを強調するために、観察されたモデルのエラーを示します。
最先端のモデルは、明確な参照が利用可能であっても、幻覚、数値的推論、および稀なトピックに苦労(赤のエラー)している事がわかります。 最後の事例は、モデルの出力が正しい場合でも、テーブルに関するより多くの推論を含む元の参照(青で表示)ほど有益ではない場合があることを示しています。
| 参照文 | モデルの予想 |
| in the 1939 currie cup, western province lost to transvaal by 17–6 in cape town. | the first currie cup was played in 1939 in transvaal1 at new- lands, with western province winning 17–6. |
| a second generation of micro- drive was announced by ibm in 2000 with increased capacities at 512 mb and 1 gb. | there were 512 microdrive models in 2000: 1 gigabyte. |
| the 1956 grand prix motorcy- cle racing season consisted of six grand prix races in five classes: 500cc, 350cc, 250cc, 125cc and sidecars 500cc. | the 1956 grand prix motorcycle racing season consisted of eight grand prix races in five classes: 500cc, 350cc, 250cc, 125cc and sidecars 500cc. |
| in travis kelce’s last collegiate season, he set personal career highs in receptions (45), re- ceiving yards (722), yards per receptions (16.0) and receiving touchdowns (8). | travis kelce finished the 2012 season with 45 receptions for 722 yards (16.0 avg.) and eight touchdowns. |
まとめ
本投稿では、ToTToを紹介しました。ToTToは、制御された生成タスクと、反復的な文の改訂に基づくデータ注釈プロセスの両方を提示する、大規模な表からテキストへの英語データセットです。
また、いくつかの最先端の比較モデルを調査し、ToTToがモデリング研究や、モデルの改善をより適切に検出できる評価指標の開発に役立つデータセットであることを示しました。
提案されたタスクに加えて、私たちのデータセットがテーブルの理解や文の改訂などの他のタスクにも役立つことを願っています。ToTToは、GitHubリポジトリから入手できます。
謝辞
著者は、Ming-Wei Chang, Jonathan H. Clark, Kenton Lee, Jennimaria Palomakiの洞察に満ちた議論とサポートに感謝します。注釈を手伝ってくれたAshwin Kakarlaと彼のチームにも感謝します。
3.ToTTo:表から文を抽出する能力を測るためのデータセット(2/2)関連リンク
1)ai.googleblog.com
ToTTo: A Controlled Table-to-Text Generation Dataset
2)arxiv.org
ToTTo: A Controlled Table-To-Text Generation Dataset
3)github.com
google-research-datasets / ToTTo

