
1.Pr-VIPE:異なる視点から撮影した画像間で人間の姿勢の類似性を認識(2/2)まとめ
・Pr-VIPEを使用して異なった視点から撮影された動画から同じポーズを検索する事が可能
・カメラパラメータを使用せずに異なる視点から同じポーズを取得できる事が特徴
・Pr-VIPEを使用して繰り返し動作を映したビデオの位置合わせを行う事も可能
2.Pr-VIPEの応用
以下、ai.googleblog.comより「Recognizing Pose Similarity in Images and Videos」の意訳です。元記事の投稿は2021年1月14日、Jennifer J. SunさんとTing Liuさんによる投稿です。
アイキャッチ画像のクレジットはPhoto by Andrey Zvyagintsev on Unsplash
視点不変
2つのソース、「複数視点画像」と「真の三次元ポーズを投影した画像」から二次元ポーズを取得して使用します。
二次元ポーズのトリプレット(アンカー(anchor、錨)、ポジティブ(positive、正)、ネガティブ(negative、負))はバッチから選択されます。ここで、アンカーとポジティブは同じ三次元ポーズの2つの異なる投影であり、ネガティブは異なった三次元ポーズの投影です。
次に、Pr-VIPEは、embeddingから二次元ポーズ同士のペアの一致確率を推定します。トレーニング中に、ポジティブペアワイズ損失を使いポジティブペアが一致する確率を1に近づけるようにポジティブペア間のembedding距離を最小化します。更に、ネガティブペア間が一致する確率を小さくします。トリプレット比損失を使い、ポジティブとネガティブのペアが一致する確率を最大化する事でこれを行います。
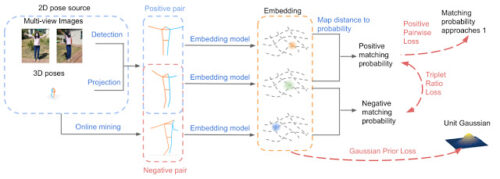
Pr-VIPEモデルの概要。トレーニング中に、3つの損失(トリプレット比損失, ポジティブペアワイズ損失, embeddingに単位ガウス分布を適用する事前損失)を使います。推論中に、モデルは入力二次元ポーズを確率的で視点不変のembedding空間に割り当てます。
確率的Embedding
Pr-VIPEは、2つの分布間の類似性スコア計算にサンプリングベースのアプローチを使用して、二次元ポーズを多変量ガウス分布として確率的Embeddingにマッピングします。トレーニング中、予測分布を正規化するためにガウス事前損失を使用します。
Pr-VIPEの評価
Embeddingの視点不変特性を評価するために、新しい視点横断的にポーズを検索するベンチマークを提案します。
1つの視点から撮影されたポーズ画像が与えられた場合、視点横断的な検索(cross-view retrieval、クロスビュー検索)は、カメラパラメータを使用せずに異なる視点から同じポーズを取得することを目的としています。
以下の結果は、Pr-VIPEが、評価された両方のデータセット(Human3.6M、MPI-INF-3DHP)の比較対象とした手法より、視点全体でポーズをより正確に取得出来ている事を示しています。
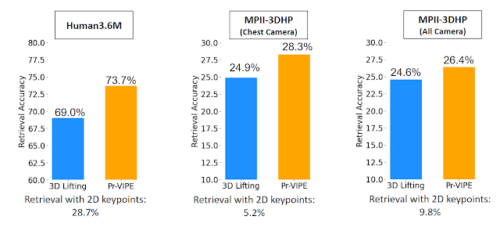
Pr-VIPEは、比較対象とした手法(3D pose estimation)と比較して、様々な視点から撮影されたポーズをより正確に取得できます。
応用
視点不変のポーズEmbeddingは、多くの画像およびビデオ関連のタスクに適用できます。以下に、カメラパラメータを使用せずに通常の環境で撮影された画像を入力に使って、異なった視点から撮影された動画内から同じポーズを検索した応用事例を示します。

Pr-VIPEを使用して二次元ポーズをEmbedding化して入力に与える事により、カメラパラメータを使用せずに、異なった視点から撮影された動画から同じポーズを検索する事ができます。
入力画像(上段)を使用して、別のカメラ視点から一致するポーズを検索し、最近傍検索を行い同じポーズを表示(下の行)できます。これにより、様々なカメラ視点から一致するポーズをより簡単に検索できます。
同じPr-VIPEモデルをビデオの位置合わせに使用することもできます。これを行うには、Pr-VIPE Embeddingを短い時間間隔で切り出してし、ダイナミックタイムワーピング(DTW:Dynamic Time Warping)アルゴリズムを使用してビデオ同士を整列させます。

手動でビデオを位置合わせする事は難しく、時間がかかります。ここでは、Pr-VIPEを適用して、異なる視点から繰り返される同じアクションのビデオを自動的に位置合わせしています。
DTWを介して計算されたビデオアライメント距離は、最近傍探索を使用してビデオを分類することにより、アクション認識に使用できます。
Penn Actionデータセットを使用してPr-VIPE Embeddingを評価し、ターゲットデータセット用に微調整せずともPr-VIPEEmbeddingを使用すると、非常に競争力のある認識精度が得られる事がわかりました。
更に、Pr-VIPEは、インデックスセット内の単一視点から撮影されたビデオのみを使用して比較的正確な結果を達成できる事さえ示しています。
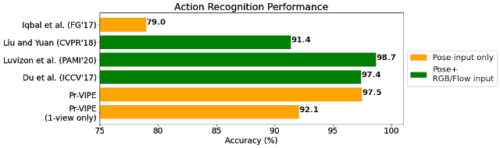
Pr-VIPEは、ポーズ入力のみを使用してビュー全体のアクションを認識し、ポーズのみを使用する方法、または(Iqbal et al, Liu and Yuan, Luvizon et al, and Du et alの研究のように)追加の場面情報を使用する方法と同等またはそれ以上の精度を出せます。アクションラベルが単一視点から撮影したビデオにしかない場合でも、Pr-VIPE (1-view only)は比較的正確な結果を得ることができます。
結論
二次元空間で表現される人間の姿勢を視点不変の確率的embedding空間にマッピングするためのPr-VIPEモデルを紹介し、学習したembeddingがポーズの取得、行動認識、およびビデオの位置合わせに直接使用できることを示しました。cross-view retrievalベンチマークを使用して、他のembeddingの視点不変属性をテストできます。ポーズのembeddingで何ができるかをお聞きするのを楽しみにしています!
謝辞
Jiaping Zhao, Liang-Chieh Chen, Long Zhao (Rutgers University), Liangzhe Yuan, Yuxiao Wang, Florian Schroff, Hartwig Adamおよびモバイルビジョンチームの素晴らしい共同作業とサポートに感謝します。
3.Pr-VIPE:異なる視点から撮影した画像間で人間の姿勢の類似性を認識(2/2)関連リンク
1)ai.googleblog.com
Recognizing Pose Similarity in Images and Videos
2)arxiv.org
View-Invariant Probabilistic Embedding for Human Pose
3)github.com
POEM: Human POse EMbedding

