
1.CLIP:学習していない視覚タスクを実行なニューラルネット(2/3)まとめ
・ゼロショット機能実現は単純に事前トレーニングタスクを規模拡大するだけで十分だった
・CLIPは視覚タスクの抱える課題であるデータが高コストである事などを軽減する
・CLIPの効率性向上には対照学習とVision Transformerを採用した事が貢献している
2.CLIPのゼロショット性能
以下、openai.comより「CLIP: Connecting Text and Images」のまとめです。元記事の投稿は2021年1月5日、Alec Radfordさん、Ilya Sutskeverさん、Jong Wook Kimさん、Gretchen Kruegerさん、Sandhini Agarwalさん, Justin Jay Wangさんによる投稿です。
アイキャッチ画像のクレジットはPhoto by STIL on Unsplash
手法
様々な画像分類データセットで競争力のあるゼロショットパフォーマンスを実現するには、単純な事前トレーニングタスクを規模拡大するだけで十分であることを示します。私達の手法では、インターネット上で見つかった画像と組み合わさったたテキストという、豊富に利用可能なデータを教師として使用します。
このデータは、CLIPの次の代替トレーニングタスクを作成するために使用されます。画像を指定して、ランダムに抽出された32,768個の断片的なテキストのセットを使い、データセット内で実際に画像とペアになっているものを予測させます。
私たちの直感では、CLIPモデルはこれを解決するために、画像内の様々な視覚的概念を認識し、それらを名前に関連付けることを学習する必要があります。その結果、CLIPモデルをほぼ任意の視覚的分類タスクに適用できるようになります。
例えば、犬と猫の写真を分類するタスクの場合。 CLIPモデルが「犬の写真」または「猫の写真」というテキストがペアになる可能性が高いと予測できているかどうかを、各画像で確認します。
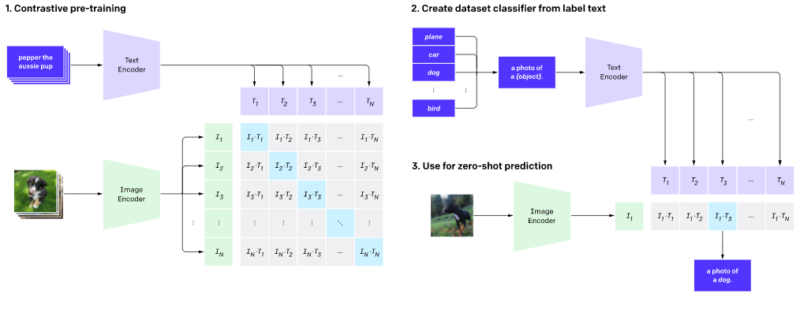
CLIPは、画像エンコーダーとテキストエンコーダーを事前トレーニングして、データセット内のどの画像がどのテキストとペアになっているかを予測します。次に、この動作を使用して、CLIPをゼロショット分類器に変換します。データセットのすべてのクラスを「犬の写真」などの説明文(キャプション)に変換し、説明文のクラスを予測します。CLIPは特定の画像とペアになる可能性が最も高い説明文を推定します。
CLIPは、コンピュータービジョンへの標準的な深層学習アプローチにおける多くの主要な問題を軽減するように設計されました。
(1)データセットの作成にコストがかかる事
ディープラーニングには大量のデータが必要であり、視覚モデルは従来、手作業でラベル付けされたデータセットでトレーニングされていました。この分野で最大の取り組みの1つであるImageNetデータセットでは、22,000のカテゴリの物体に対して1,400万の画像があり、それらに個々に注釈を付けるために25,000人を超える作業者が必要でした。対照的に、CLIPは、インターネット上で既に公開されている文章と画像のペアから学習します。高価で巨大なラベル付きデータセットの必要性を減らすことは、以前の研究、特に自己教師あり学習、対照的な手法、自己学習アプローチ、および生成モデリングによって広く研究されてきました。
(2)変更せずにできる事が少ない事
ImageNetモデルは、ImageNetに含まれる1000のカテゴリを予測する能力に優れていますが、モデルを変更せずにそのまま実行できるのはそれだけです。他のタスクを実行する場合、新しいデータセットを構築し、出力ヘッドを追加して、モデルを微調整する必要があります。
対照的に、CLIPは、追加のトレーニング例を必要とせずに、様々な視覚的分類タスクを実行するように適合させることができます。CLIPを新しいタスクに適用するには、CLIPのテキストエンコーダーにタスクの視覚的概念の名前を「伝える」だけで、CLIPの視覚的表現の線形分類器が出力されます。この分類器の精度は、完全な教師付きデータで学習した従来モデルに匹敵するレベルの性能に達する事がよくあります。
以下の様々なデータセットで、ゼロショットのCLIP分類器が出力した予測を示します。これらの結果はランダムに選択したもので、見栄えが良い結果を人が選択したわけではありません。
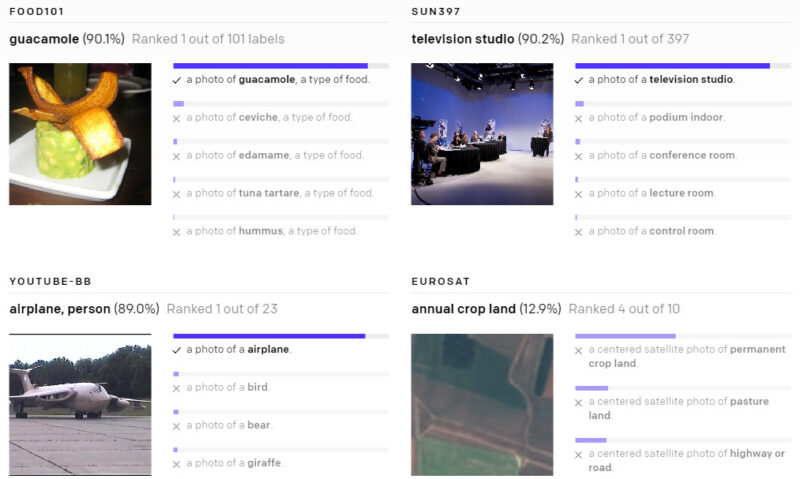
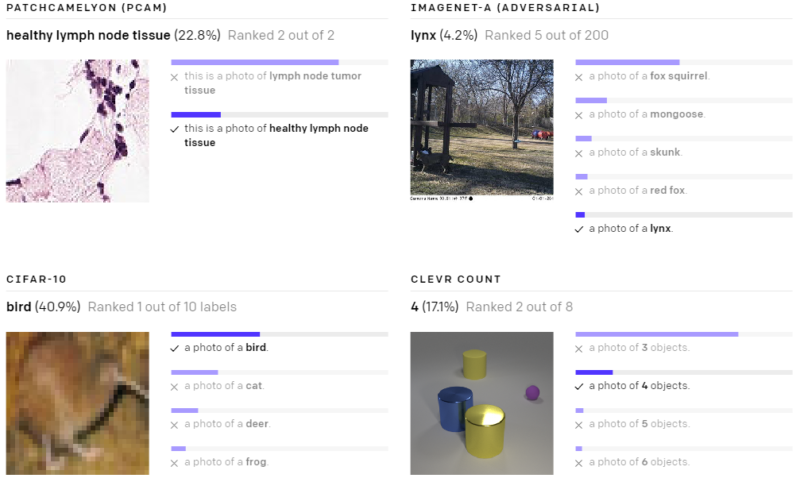
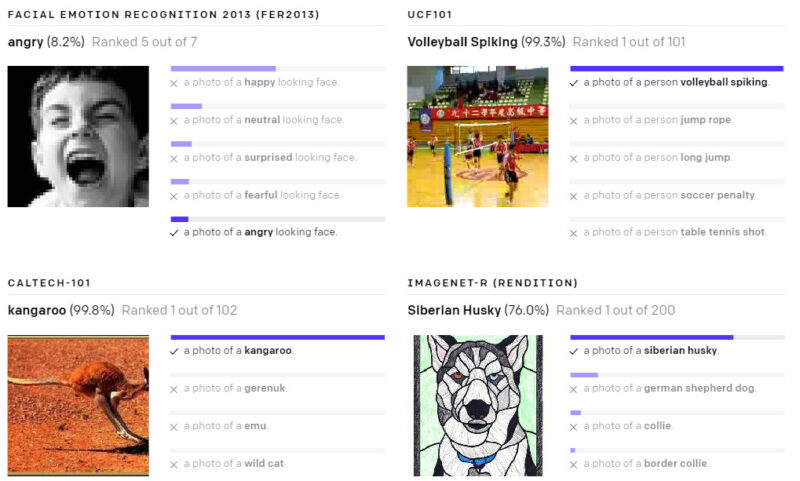
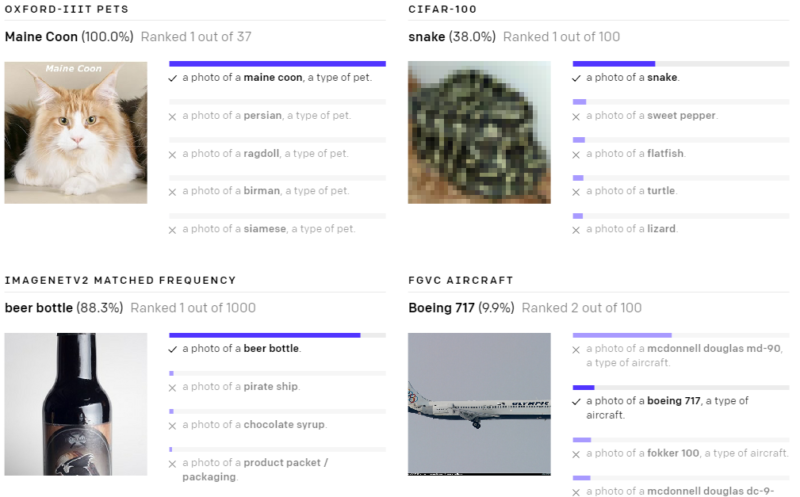
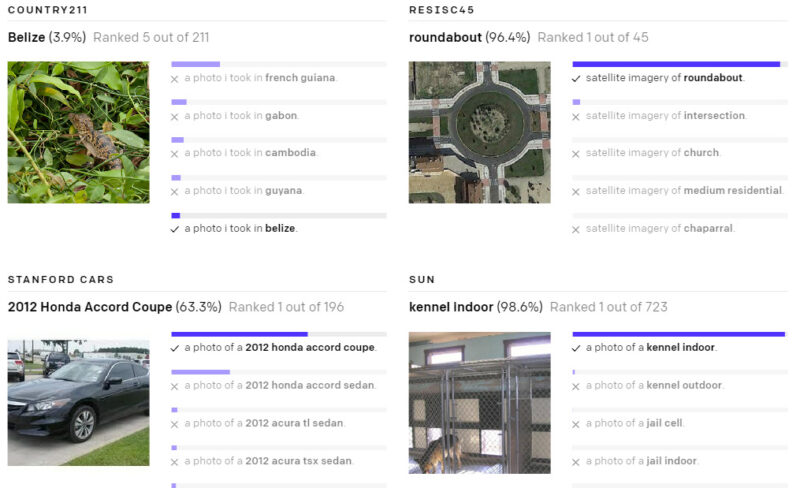
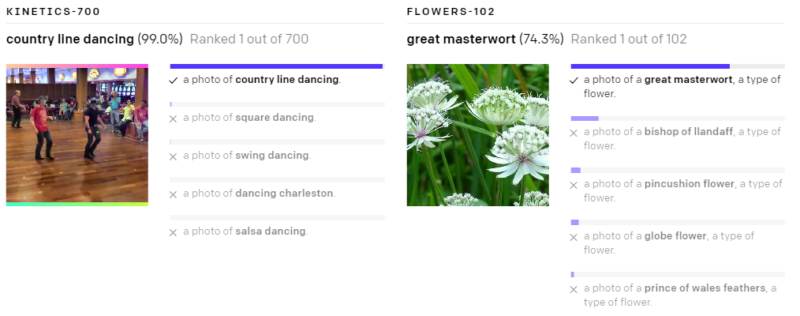
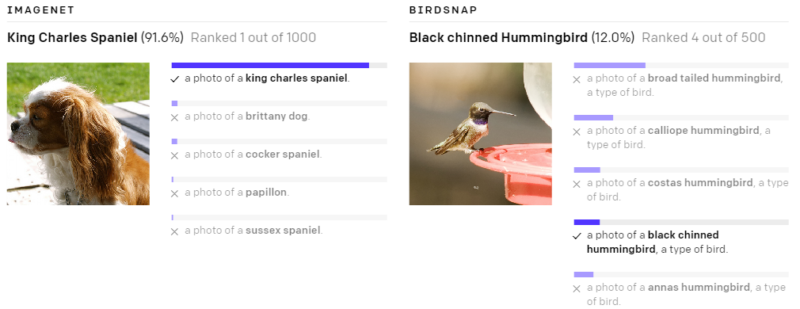
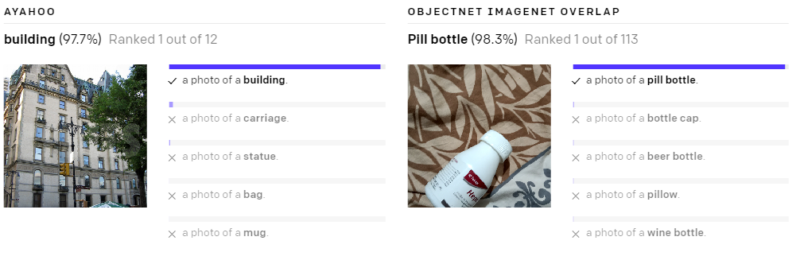
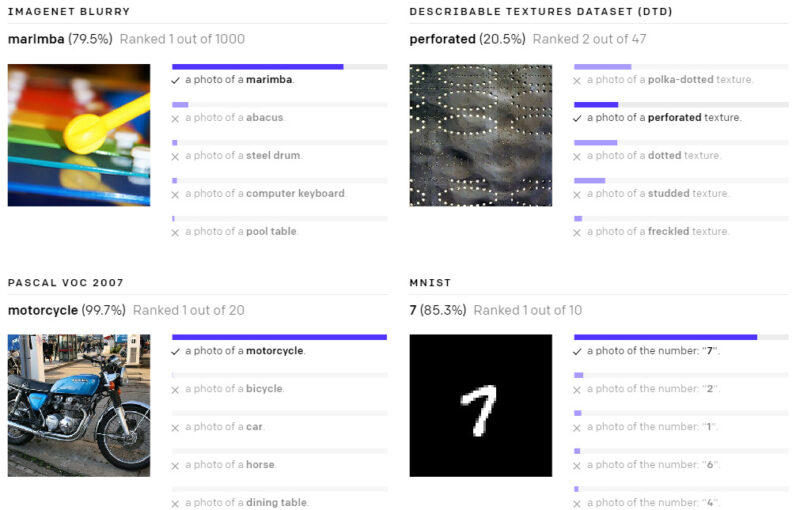
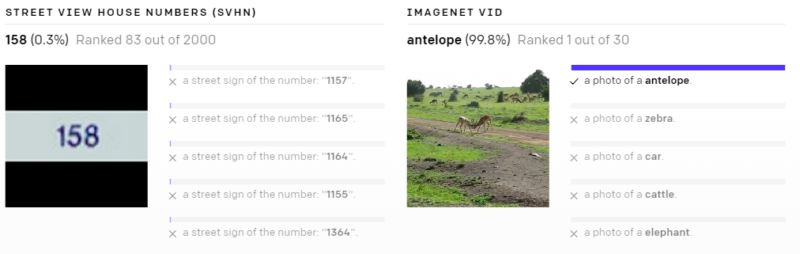
(3)現実世界でパフォーマンスが低下してしまう事
ディープラーニングシステムは、人間レベルまたは人間を超えるレベルのパフォーマンスを達成すると報告されることがよくあります。視覚タスクでは、現実世界に展開すると、パフォーマンスはベンチマーク結果から予測された期待値をはるかに下回る可能性があります。言い換えれば、「ベンチマーク時のパフォーマンス」と「現実世界での実際のパフォーマンス」の間にはギャップがあります。
このギャップは、過去数年間の試験問題だけを勉強して試験に合格する学生のように、ベンチマーク用にパフォーマンスを最適化するようにモデルが「ズル(cheat)」をするために発生していると推測されます。
対照的に、CLIPモデルは、ベンチマークに含まれるデータを使ってトレーニングせずとも評価できるため、この方法で不正をする事はできません。これにより、ベンチマークのパフォーマンスは、実際のパフォーマンスをよりよく表現するものになります。
「不正行為仮説」を検証するために、ImageNetを「学習」できる場合にCLIPのパフォーマンスがどのように変化するかも測定しました。線形分類器をCLIPの特徴表現上に取り付けると、ImageNetテストセットを使った際のCLIPの精度がほぼ10%向上します。ただし、この分類器は、「堅牢な」パフォーマンスを測定するために行った他の7つのデータセット群全体で見ると、全セットにおいて平均して優れているわけではありません。
重要なポイント
(1)CLIPは非常に効率的です
CLIPは、フィルタリングされていない、非常に多様で、非常にノイズの多いデータから学習し、ゼロショット方式で使用できる事を目的としています。GPT-2および3から、このようなデータでトレーニングされたモデルが魅力的なゼロショットパフォーマンスを達成できることがわかっています。ただし、このようなモデルには、かなりのトレーニングと計算が必要です。必要な計算量を減らすために、私たちはこの手法のトレーニング効率を改善するためのアルゴリズム的な方法に焦点を合わせました。
大幅な計算の節約につながった2つのアルゴリズムの選択を報告します。
最初の選択は、テキストと画像を接続するための対照的な目的(contrastive objective)の採用です。私たちは当初、VirTexと同様の「画像からテキスト(image-to-text)」アプローチを検討しましたが、最先端のパフォーマンスを実現するためにこれを規模拡大するのが困難でした。小規模から中規模の実験では、CLIPで使用される対照的な目的は、ゼロショットのImageNet分類で4倍から10倍効率的であることがわかりました。
2番目の選択肢は、Vision Transformerの採用でした。これにより、標準のResNetの3倍の計算効率が得られました。最終的に、最高のパフォーマンスを発揮するCLIPモデルは、既存の大規模画像モデルと同様に、256GPUで2週間トレーニングされました。
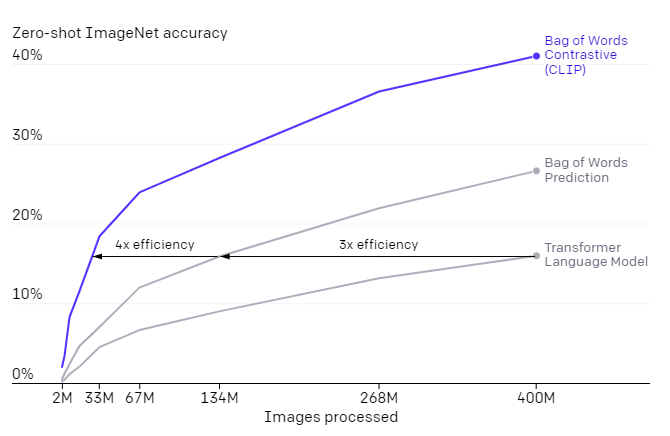
私達は当初、「画像から画像説明文」アプローチで言語モデルをトレーニングする手法を検討しましたが、このアプローチはゼロショット転移で苦戦する事がわかりました。この16GPU日の実験では、言語モデルは4億枚の画像をトレーニングした後、ImageNetで16%の精度しか達成しません。CLIPははるかに効率的で、同じ精度を約10倍速く達成できました。
3.CLIP:学習していない視覚タスクを実行なニューラルネット(2/3)まとめ
1)openai.com
CLIP: Connecting Text and Images
2)cdn.openai.com
Learning Transferable Visual Models From Natural Language Supervision(PDF)
3)github.com
openai / CLIP
