
1.LIT:自然言語モデルを対話的に調査して理解を深める解釈性ツール(2/2)まとめ
・LITは事前トレーニング済みモデルを使用したいくつかのデモが公開されている
・感情分析は映画のレビューが肯定的か否定的かを予測する機能をデモできる
・マスクされた単語の予測デモではモデルがどの単語を予測するのか確認できる
2.LITの使用例
以下、ai.googleblog.comより「The Language Interpretability Tool (LIT): Interactive Exploration and Analysis of NLP Models」の意訳です。元記事の投稿は2020年11月20日、James WexlerさんとIan Tenneyさんによる投稿です。
アイキャッチ画像のクレジットはPhoto by Fernando @cferdo on Unsplash
デモ
LITの機能の一部を説明するために、事前トレーニング済みモデルを使用していくつかのデモを作成しました。完全なリストはLITのWebサイトpair-code.github.ioで入手できます。そのうちの2つをここで説明します。
(1)感情分析
この例では、ユーザーは、文に肯定的な感情があるか否定的な感情があるかを予測するBERTベースのバイナリ分類器を探索できます。デモでは、映画のレビュー文であるStanford Sentiment Treebankを使用して、モデルの動作を示します。
様々な手法(LIMEや統合勾配など)によって提供される顕著性マップを使用して局所的な解釈を調べることができます。また、逆翻訳、単語置換、または敵対的攻撃などの手法を使用して、微妙に変更した(反事実)サンプルを使用してモデルの動作をテストできます。
これらの手法は、どのような時にモデルが失敗するかのシナリオと、それらの失敗が一般化可能かどうかを特定するのに役立ちます。これらの知見を使って、モデルを改善するための最善の方法を知る事ができます。

誤った予測に関して単語単位で顕著性を分析します。 「笑える(laughable)」という言葉は、この事例では肯定的な感情のスコアを誤って上げているようです。
(2)マスクされた単語の予測
マスク言語モデリングは「文章内の空白を埋める」タスクであり、モデルは文を完成させる可能性のある様々な単語を予測します。たとえば、「___を散歩に連れて行った」という文が表示された場合、モデルは「犬」を高スコアで予測する可能性があります。
LITでは、文章を入力するか、事前に読み込まれた言語資料から選択し、特定のトークンをクリックして、BERTのようなモデルが言語や世界について何を理解しているかを確認することで、これを対話的に調べることができます。
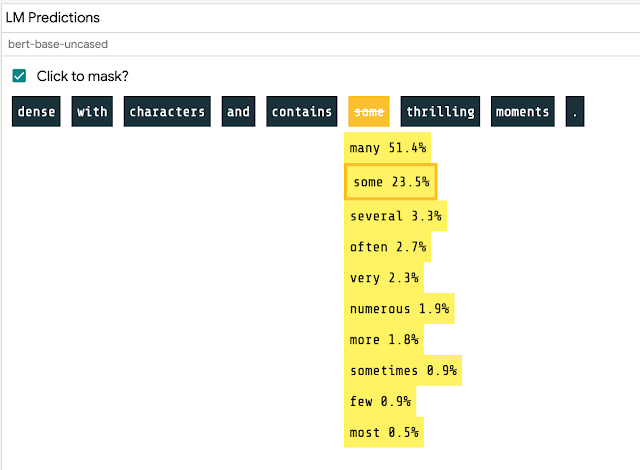
マスク部分を対話的に選択し、言語モデルの予測確率を表示します
LITの実践と将来の研究
ITは新しいツールですが、モデルを理解するためにLITが提供できる価値は既に見てきました。この視覚化を使用して、embedding空間内の離れたクラスターや、予測にとって非常に重要な単語など、モデルの動作のパターンを見つけることができます。
共参照モデルで性別の決めつけを調査するLITのケーススタディで示されているように、LITでの調査では、モデルの潜在的なバイアスをテストできます。このタイプの分析は、MinDiffを適用して構造的偏りを軽減するなど、モデルのパフォーマンスを改善するための次のステップに情報を提供できます。また、任意のNLPモデルの対話的なデモを作成するための簡単で高速な方法としても使用できます。
提供されているデモを使用するか、独自のモデルとデータセット用にLITサーバーを起動して、ツールを確認してください。LITの研究は始まったばかりであり、最先端のMLおよびNLP研究からの新しい解釈可能性手法の追加など、多くの新しい機能と改良が計画されています。
ツールに追加してほしいテクニックが他にある場合は、お知らせください。メーリングリストに参加して、LITの進化に合わせて最新情報を入手してください。また、コードはオープンソースとして公開されているため、ツールに関するフィードバックと貢献を歓迎します。
謝辞
LITは、Google ResearchのPAIRチームと言語チームの共同作業です。
本投稿は、Andy Coenen, Ann Yuan, Carey Radebaugh, Ellen Jiang, Emily Reif, Jasmijn Bastings, Kristen Olson, Leslie Lai, Mahima Pushkarna, Sebastian Gehrmann, そしてTolga Bolukbasiなど、Google全体の多くの貢献者の作業によるものです。Googleの内外を問わず、プロジェクトに貢献してくれた全ての人と、プロジェクトを試用し、貴重なフィードバックを提供してくれたチームに感謝します。
3.LIT:自然言語モデルを対話的に調査して理解を深める解釈性ツール(2/2)関連リンク
1)ai.googleblog.com
The Language Interpretability Tool (LIT): Interactive Exploration and Analysis of NLP Models
2)github.com
PAIR-code / lit
3)pair-code.github.io
Language Interpretability Tool
4)arxiv.org
The Language Interpretability Tool: Extensible, Interactive Visualizations and Analysis for NLP Models

