
1.Hum to Search:鼻歌検索の背後に存在する技術(2/2)まとめ
・トレーニングデータは元の歌声をハミングや口笛に変換して認識率を向上させている
・トレーニング時にはトリプレット損失関数をベースに信頼性の概念に改良を加えた
・現在のシステムは継続的に更新されており50万以上の楽曲を対象に高レベルの精度を達成
2.Hum to Searchとは?
以下、ai.googleblog.comより「The Machine Learning Behind Hum to Search」の意訳です。元記事の投稿は2020年11月12日、Christian Frankさんによる投稿です。
アイキャッチ画像のクレジットはPhoto by bruce mars on Unsplash
トレーニングデータ
モデルのトレーニングには歌のペア(曲を録音したデータと、その曲を歌ったデータ)が必要だったため、最初の課題は十分なトレーニングデータを取得することでした。
私達の最初のデータセットは、主に歌ったデータで構成されていました(これらのほとんどはハミングを含んでいませんでした)。モデルをより堅牢にするために、トレーニング中にデータを水増ししました。例えば、歌ったデータの音程やテンポをランダムに変更しました。結果として得られたモデルは、曲を歌って検索する場合は十分に機能しましたが、ハミングや口笛の場合は十分に機能しませんでした。
ハミングでのモデルのパフォーマンスを向上させるために、FreddieMeterプロジェクトの一環として幅広いチームによって開発されたピッチ抽出モデルであるSPICEを使用して、既存のオーディオデータセットからシミュレートされた「ハミングされた」メロディーの追加トレーニングデータを生成しました。
SPICEは、指定されたオーディオから音の高さ(ピッチ値)を抽出します。これを使用して、個別のオーディオトーンで構成されるメロディーを生成します。このシステムの最初のバージョンは、この元の音楽データをトーンに変換しました。
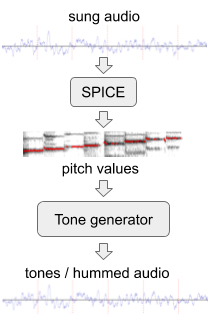
曲を歌ったデータからハミングされたデータを生成
その後、単純なトーンジェネレーターを、現実のハミングや口笛に似た音声を生成するニューラルネットワークに置き換えることで、このアプローチを改良しました。例えば、ネットワークは、下記のように歌データからハミングデータ、または口笛データを生成します。
第九を歌ったデータ(元データ)
第九を歌ったデータをハミングにしたもの
第九を歌ったデータを口笛にしたもの
最後のステップとして、オーディオサンプルをミキシングおよびマッチングすることによってトレーニングデータを比較しました。
例えば、2人の異なる歌手から採取された似たデータがある場合、それらの2つを整列し、同じメロディーを表す追加のオーディオのペアとしてモデルに与える事ができます。
機械学習の改善
Hum to Searchモデルをトレーニングするとき、トリプレット(triplet)損失関数から始めました。この損失は、画像や録音された音楽などのさまざまな分類タスクでうまく機能することが示されています。同じメロディーに対応するオーディオのペア(以下に示すembedding空間のRとP)が与えられた場合、トリプレット損失は、異なるメロディーから派生したトレーニングデータの特定の部分を無視します。
この性質は、機械の学習動作を改善するのに役立ちます。
例えば、RとPから遠く離れており判別が簡単すぎる別のメロディー(E)や、モデルの現在の学習状況から考えるとRに近すぎて判別が難しい別のメロディー(H)を判別する場合などです。

embedding空間の視覚化とオーディオセグメントの例
これらの追加のトレーニングデータ(HおよびE)を考慮に入れることによって、モデルの精度を向上させる事ができることがわかりました。具体的には、バッチ全体でモデルの信頼性に関する一般的な概念を定式化しました。
示された全てのデータが正しく分類できますか?
現在の理解に適合しないサンプルが表示されたことをモデルがどの程度確信していますか?
この信頼性の概念に基づいて、embedding空間の全ての領域でモデルの信頼性を100%に近づける損失を追加しました。これにより、モデルの適合率と再現率が向上しました。
上記の変更がありますが、特にトレーニングデータのバリエーション、水増し、重ね合わせにより、Google検索に適用されたニューラルネットワークモデルは歌やハミングで入力されたメロディーを認識できるようになりました。現在のシステムは、継続的に更新されている50万曲を超える楽曲に対して高い認識精度を達成しています。
この楽曲データベースには、世界の多くのメロディーを更に含めるために成長させる余地がまだあります。
Google Appで動作中のHum to Search
Google Appの最新バージョンを開き、マイクのアイコンをタップして、「この曲は何ですか?(what’s this song?)」と話す事でこの機能を試せます。または、曲を検索(Search a song)ボタンをクリックすると、口ずさむ、歌う、または口笛を吹く事で検索できます。
Hum to Searchがあなたの頭からイヤーワームを追い出すために役立つことを願っています。あるいは、名前を入力せずに曲を見つけて再生したい場合にも役立つかもしれません。
謝辞
ここで説明する作品は、Alex Tudor, Duc Dung Nguyen, Matej Kastelic, Mihajlo Velimirović, Stefan Christoph, Mauricio Zuluaga, Christian Frank, Dominik Roblek, 及び Matt Sharifiによって作成されました。Krishna Kumar, Satyajeet Salgar そして Blaise Aguera y Arcasの継続的なサポート、および完全なHum to Searchを製品として構築するために協力してくれたすべてのGoogleチームに深く感謝します。
また、歌ったりハミングしたりしてこの作品の基礎を築く事に協力してくれたGoogleの同僚全員と、Google内部向けに歌の寄付アプリを作成してくれたNick Moukhineにも感謝します。最後に、この投稿の草稿に関するフィードバックを寄せてくれたMeghan DanksとKrishna Kumarに感謝します。
3.Hum to Search:鼻歌検索の背後に存在する技術(2/2)関連リンク
1)ai.googleblog.com
The Machine Learning Behind Hum to Search
2)freddiemeter.withyoutube.com
FreddieMeter

