
1.VoiceFilter-Lite:オンデバイスの音声認識の改善(2/2)まとめ
・VoiceFilter-Liteは使用者が自分の音声を登録しなかった場合はアプリ側で無効化できる
・音声分離モデルに発生しがちな抑制不足と抑制過剰への対処も考慮されている
・わずか2.2MBのVoiceFilter-Liteモデルで混声時の単語誤り率が25.1%向上した
2.抑制不足と抑制過剰
アイキャッチ画像のクレジットはPhoto by GESPHOTOSS on Unsplash
VoiceFilter-Liteはプラグアンドプレイモデルであり、使用者が自分の音声を登録しなかった場合に、VoiceFilter-Liteを使っているアプリケーションが簡単にVoiceFilter-Liteを迂回できるようにします。これは、音声認識モデルとVoiceFilter-Liteモデルを個別にトレーニングおよび更新できる事も意味します。これにより、製品展開プロセスにおけるエンジニアリング作業の複雑さが大幅に軽減されます。
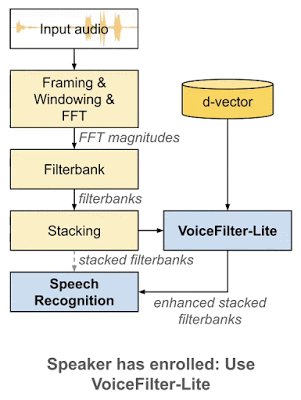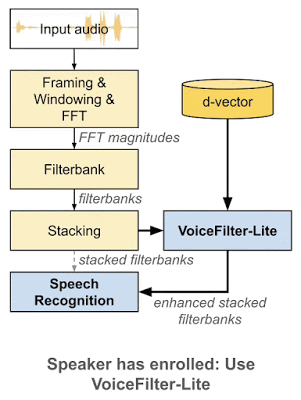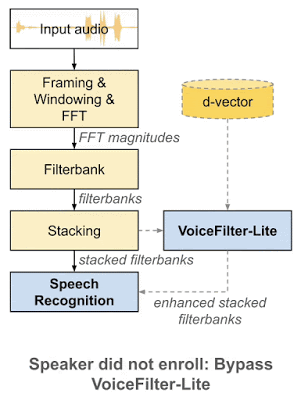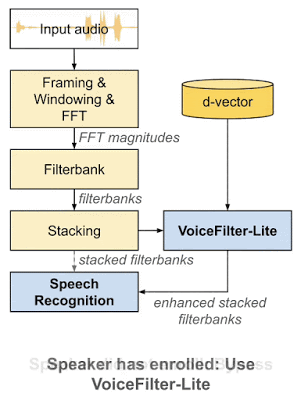
着脱が用意なプラグアンドプレイモデルとして、VoiceFilter-Liteは、話者が自身の音声を登録しなかった場合は簡単に迂回できます。
過剰に抑制してしまう課題への対処
音声認識を改善するために音声分離モデルを使用すると、2種類のエラーが発生する可能性があります。
1)抑制不足(under-suppression)
モデルが信号からノイズの多い成分をフィルターで除去できないエラーです。
2)抑制過剰(over-suppression)
モデルが有用な信号を保持できず、認識されたテキストから一部の単語が削除されてしまうエラーです。
現代の音声認識モデルは通常、様々な場面を想定して水増しされたデータ(部屋内での発声をシミュレーションしたりSpecAugmentを使う事など)ですでにトレーニングされており、抑制不足に対してより堅牢であるため、抑制過剰の方が特に問題になります。
VoiceFilter-Liteは、2つの新しいアプローチで抑制過剰の問題に対処します。
まず、トレーニングプロセス中に非対称損失を使用するため、モデルは抑制不足よりも抑制過剰を受けにくなります。次に、実行時のノイズの種類を予測し、この予測に従って抑制強度を適応的に調整します。
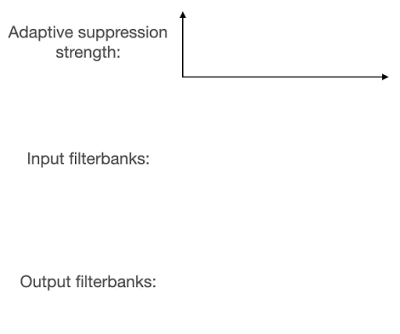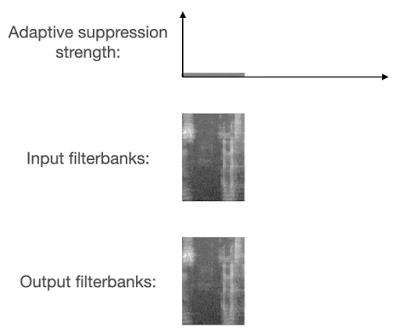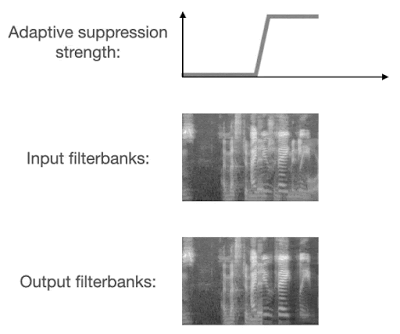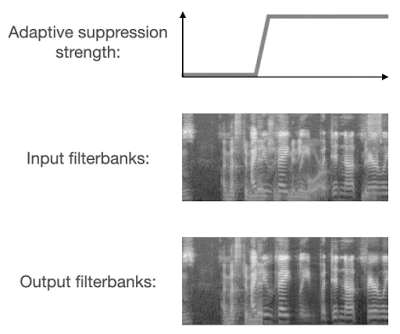
VoiceFilter-Liteは、入り混じった音声を検出すると、抑制強度を必要に応じて強めます。
これらの2つの解決策により、VoiceFilter-Liteモデルは、通常のストリーミング音声認識、つまり、静かな環境、または様々なノイズが入り混じる環境下で、一人が発声している状況での優れたパフォーマンスを維持しながら、入り混じった音声の音声認識を大幅に改善します。
私達の実験では、2.2MBのVoiceFilter-Liteモデルを入り混じった音声に適用した後、単語誤り率が25.1%向上することが観察されました。
発声が反響効果を受ける環境でも検証しました。スマートホームスピーカーなどの離れた箇所に設置される機器は、シミュレートが難しいのですが、VoiceFilter-Liteを使用すると単語誤り率が14.7%向上することも確認されました。
今後の研究
VoiceFilter-Liteは、様々なオンデバイス音声アプリケーションで大きな成功が期待されますが、VoiceFilter-Liteをより便利にするために他のいくつかの方向性も模索しています。
まず、現在のモデルは英語の音声のみでトレーニングおよび評価されています。同じテクノロジーを採用して、より多くの言語の音声認識を改善できる事に興奮しています。次に、VoiceFilter-Liteのトレーニング中に音声認識の損失を直接最適化したいと考えています。これにより、入り混じった音声の対処を超えて音声認識をさらに改善できる可能性があります。
謝辞
この投稿で説明されている調査は、Google内の複数のチームによる共同の取り組みを表しています。貢献者には以下の皆さんが含まれます。
Quan Wang, Ignacio Lopez Moreno, Mert Saglam, Kevin Wilson, Alan Chiao, Renjie Liu, Yanzhang He, Wei Li, Jason Pelecanos, Philip Chao, Sinan Akay, John Han, Stephen Wu, Hannah Muckenhirn, Ye Jia, Zelin Wu, Yiteng Huang, Marily Nika, Jaclyn Konzelmann, Nino Tasca, Alexander Gruenstein。
3.VoiceFilter-Lite:オンデバイスの音声認識の改善(2/2)関連リンク
1)ai.googleblog.com
Improving On-Device Speech Recognition with VoiceFilter-Lite
2)arxiv.org
VoiceFilter-Lite: Streaming Targeted Voice Separation for On-Device Speech Recognition
VoiceFilter: Targeted Voice Separation by Speaker-Conditioned Spectrogram Masking
Generalized End-to-End Loss for Speaker Verification

