
1.解釈しやすいニューロンがディープラーニングの性能を低下させる可能性まとめ
・一部のニューロンは猫画像など特定クラスを優先する性質を持ちこれをクラス選択性という
・クラス選択性は学習中に自動出現するので解釈可能性に関するツールとして注目されている
・DNNのクラス選択性を高めるとネットワークのパフォーマンスに重大な悪影響が見られた
2.解釈しやすいニューロンの問題点とは?
以下、ai.facebook.comより「Easy-to-interpret neurons may hinder learning in deep neural networks」の意訳です。元記事の投稿は2020年10月28日、Matthew LeavittさんとAri Morcosさんによる投稿です。
効率の良いモデルが公平性の観点で劣る可能性がある事はZariで示されましたが、今度は解釈可能性を追求すると性能が悪化する可能性があるとのお話です。
おそらくこれらはトレードオフの関係にあるのだろうな、と感じて選んだアイキャッチ画像のクレジットはPhoto by noodle kimm on Unsplash
AIモデルは何を「理解」しているのでしょうか?そして、その理由は何故ですか?
この質問に答えることは、AIシステムを再現および改善するために重要です。
残念ながら、ディープニューラルネットワーク(DNN:Deep Neural Networks)を解釈するコンピューター科学者の能力は、それらを使用して有用な結果を達成する能力に大きく遅れをとっています。DNNを理解するための一般的な方法の1つは、個々のニューロンの特性に焦点を当てています。
例えば、猫の画像に対してはアクティブになるが、他のタイプの画像に対してはアクティブにならない個々のニューロンを見つけることです。
特定の画像タイプに対するこの優先(preference)を「クラス選択性(class selectivity)」と呼んでいます。
選択性は、人間の言葉で直感的で理解しやすいため(例えば、これらのニューロンはネットワークの「猫」の部分です!など)、広く使用されています。
そして、これらの種類の解釈可能なニューロンが実際にそのように行動しており、様々な異なるタスクでトレーニングされたネットワークに自然に出現します。
例えば、さまざまな種類の画像を分類するようにトレーニングされたDNNには、ラブラドールレトリバーに対して最も強く活性化する(つまり、選択的である)個々のニューロンが含まれています。
また、製品レビューで個々の文字を予測するようにトレーニングされたDNNには、ポジティブまたはネガティブな感情に選択的なニューロンが含まれています。
しかし、DNNが機能するためには、このように解釈しやすいニューロン(easy-to-interpret neurons)が実際に必要なのでしょうか?
自動車の排気ガスを研究して自動車の推進力を理解するようなものかもしれません。排気ガスは車の速度に関係していますが、それが推進力ではありません。クラス選択性はエンジンの一部なのでしょうか?それとも排気ガスの一部なのでしょうか?
驚いたことに、ニューロンの大部分がクラス選択的でなくても、DNNがうまく機能できることを示す強力な証拠が見つかりました。実際、簡単に解釈できるニューロンはDNNの機能を損ない、ネットワークをランダムに歪んだ入力の影響を受けやすくする可能性があります。
DNNのニューロンのクラス選択性を直接制御する新しい手法を開発する事で、これを発見しました。
私達の調査結果は、DNNを理解するための直感ベースの方法への過度の依存は、これらの方法が厳密にテストおよび検証されていない場合、誤解を招く可能性がある事を示すのに役立ちます。
AIシステムを完全に理解するには、直感的であるだけでなく、経験に基づいた方法を模索する必要があります。
私達が発見した事
DNNの解釈可能性に関するツールとしてクラス選択性が広く検討されてきましたが、DNNが最適に機能するために、解釈しやすいニューロンが実際に必要かどうかについての研究は驚くほどありません。
研究者たちは最近、簡単に解釈できるニューロンが実際にDNN機能にとって重要であるかどうかを調べ始めましたが、様々な研究で矛盾する結果が報告されています。
私達はクラス選択性を操作する新しいアプローチを通じて、この質問に取り組みました。
画像を分類するためにネットワークをトレーニングするとき、画像を分類する能力を向上させるようにネットワークに指示しただけでなく、ニューロンのクラス選択性の量を減らす(または増やす)インセンティブも追加しました。
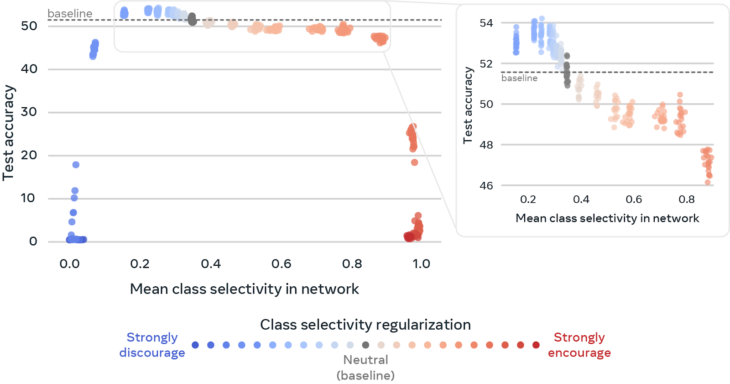
ここでは、DNN内のニューロン間でクラス選択性を操作すると、画像を正しく分類するDNNの機能にどのように影響するかを示します。(具体的には、Tiny ImageNetでトレーニングされたResNet18で確認)。
各ポイントは単一のDNNを表します。ドットの色は、DNNのニューロンでクラス選択性がどれほど強く推奨または推奨されなかったかを表しています。x軸は、DNN内のニューロン全体の平均クラス選択性を示し、y軸は、DNNが画像をどの程度正確に分類するかを示します。
灰色の点は中立であり(クラス選択性は推奨も推奨もされていません)、分類の精度を比較するためのベースラインとして使用する、このタイプのDNNで自然発生するクラス選択性のレベルを表しています。クラス選択性(青い点)を阻止することで、テストの精度を2%以上向上させることができます。対照的に、クラス選択性(赤い点)を奨励すると、DNNの画像分類能力に急速に悪影響が生じます。データのサブセットを拡大して、クラス選択性の減少と増加の影響をわかりやすく説明します。
私達はこれを、ネットワークのトレーニングに使用される損失関数にクラス選択性の概念を追加することで実現しました。単一のパラメーターを使用して、ネットワークに対するクラス選択性の重要性を制御します。
このパラメーターを変更すると、簡単に解釈できるニューロンを推奨するか、または推奨しないかの程度が変わります。これにより、ネットワーク内のすべてのニューロンにわたるクラス選択性を操作できる単一のつまみ(knob)が得られます。これを試してみたところ、次の事がわかりました。
(1)DNNのクラス選択性を下げる事は、パフォーマンスにほとんど影響がなく、場合によってはパフォーマンスが向上することさえありました。これらの結果は、クラス選択性がDNN機能に不可欠ではなく、タスクやモデル全体に遍在しているにもかかわらず、DNN機能に悪影響を与えることさえあることを示しています。
(2)DNNのクラス選択性を高めると、ネットワークパフォーマンスに重大な悪影響が見られました。この2番目の結果は、クラス選択性の存在がDNNが正しく機能することを保証するものではないことを示しています。
(3)現実世界に展開されているDNNは、研究環境と比較して、ノイズが多く歪んだデータを処理することがよくあります。例えば、研究環境のDNNは、ウィキペディアから非常に鮮明な猫の画像を与えられますが、現実世界では、DNNは、逃げていく猫の暗くぼやけた画像を処理する必要があります。クラス選択性が低下すると、DNNがボヤケやノイズなどの自然な歪みに対してより堅牢になることがわかりました。興味深いことに、クラス選択性を下げると、DNNは、画像を意図的に操作してDNNを騙そうとする標的型攻撃に対してより脆弱になります。
これらの調査結果は、2つの理由で驚くべきものです。
1つは、クラス選択性がDNN機能を理解するために広く使用されているため、もう1つは、クラス選択性がほとんどのDNNに自然に存在するためです。
また、私達の研究によればクラス選択性を外部から操作されない場合、DNNは、パフォーマンスに悪影響を与える事なく、可能な限り多くのクラス選択性を自然に学習することも示唆されています。これは、今後の作業で答えたいと考えているより深い質問につながります。
優れたパフォーマンスに必要でないのに、なぜネットワークはクラス選択性を学習するのでしょうか?
これが重要な理由
クラス選択性つまみ(class selectivity knob)のシンプルさと有用性により、他の研究者がこの手法を採用して、クラス選択性とDNNにおけるその役割についての集合的な理解を深めることができることを願っています。
複雑なニューラルネットワークシステムを理解するためのアプローチは、実際に意味のある特性に基づいて開発する事が重要です。
猫用のニューロンを持たないが猫を認識する能力に問題がないDNNをトレーニングできるのであれば、猫用のニューロンに焦点を当ててDNNを理解しようとすべきではありません。
別のアプローチとして、AI研究者は、ニューロンの大きなグループがどのように共同で機能するかを分析する事にもっと焦点を合わせる必要があります。
また、私達はクラス選択性に対して正則化することによる潜在的なパフォーマンス上の利点が、実用的なアプリケーションに繋がる可能性がある事を楽観的に考えています。
より広く言えば、私達の研究結果は一般的に、DNNがどのように機能するかを理解するための鍵として単一ニューロンの特性に焦点を当てることに対して警告しています。
実際、これらの結果に続くものとして、広く使用されている解釈可能性に関する手法が誤解を招く結果をどのように招くかを調べました。
この問題に対処するために、直感への過度の依存が研究者を迷わせた2つのケーススタディをレビューするポジションペーパー「Towards falsifiable interpretability research」をリリースしました。そして、直接テストされ、証明または反証される可能性のある、具体的で批判的に反証可能な仮説を構築することを中心とした解釈可能性研究のフレームワークについて議論しています。
私達の「直感をテストする堅牢で定量化可能な解釈可能性の研究」は、DNNの理解に有意義な進歩をもたらします。この全ての作業は、AIの説明性をさらに高めるためのFacebookの幅広い取り組みの一環で、機械学習開発者向けのオープンソースの解釈可能性ツール(Captum)や主要なプラットフォームとのパートナーシップを含みます。
最終的に、本研究は、研究者が複雑なAIシステムがどのように機能するかをよりよく理解し、より堅牢で信頼性が高く、有用なモデルにつながるのに役立ちます。
3.解釈しやすいニューロンがディープラーニングの性能を低下させる可能性関連リンク
1)ai.facebook.com
Easy-to-interpret neurons may hinder learning in deep neural networks
Open-sourcing Captum: A model interpretability library for PyTorch
2)arxiv.org
Towards falsifiable interpretability research
Selectivity considered harmful: evaluating the causal impact of class selectivity in DNNs
On the relationship between class selectivity, dimensionality, and robustness
Towards falsifiable interpretability research

