
1.DVRL:強化学習を使って学習用データの影響を推定(1/2)まとめ
・DVRLはデータ価値の推定やノイズ影響の除去で従来手法より優れた成果を出した
・学習データが検証/テストデータと異なる分布に由来するドメイン適応シナリオも対応可
・データ評価を予測モデルのトレーニング手順に統合した事が今回の手法の特徴
2.DVRLの性能
以下、ai.googleblog.comより「Estimating the Impact of Training Data with Reinforcement Learning」の意訳です。元記事の投稿は2020年10月28日、Jinsung YoonさんとSercan O. Arikさんによる投稿です。
アイキャッチ画像のクレジットはPhoto by Leslie Jones on Unsplash
結果
DVRLのデータ値推定品質を複数のタイプのデータセットと使用例で評価しました。
・高品質/低品質のサンプルを削除した後のモデルのパフォーマンス
トレーニングデータセットから価値の低いサンプルを削除すると、特にトレーニングデータセットに破損したサンプルが含まれている場合に、予測モデルのパフォーマンスを向上させることができます。 一方、特にデータセットが小さい場合、価値の高いサンプルを削除すると、パフォーマンスが大幅に低下します。 全体として、高値/低値のサンプルを削除した後のパフォーマンスは、データ評価の品質を示す強力な指標です。
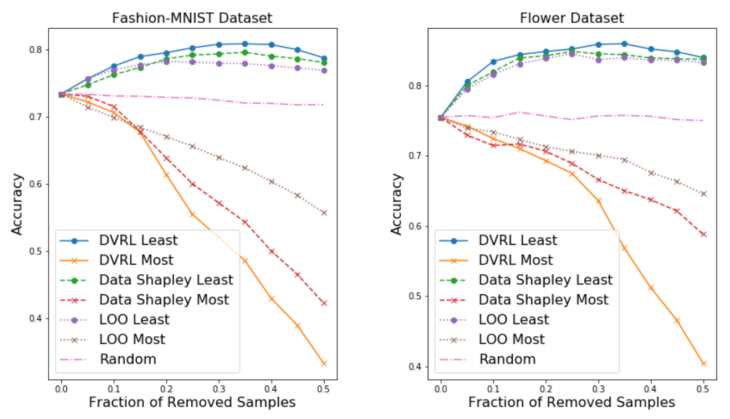
ラベルの20%にノイズが含まれている場合に、最も価値のあるサンプルと最も価値の低いサンプルを削除した際の精度
最も価値の低いサンプルなどのノイズの多いラベルを削除する事が出来るので、高品質のデータ評価方法は精度を向上できます。この観点から、DVRLが他の方法よりも大幅に優れていることを示されました。
DVRLは、ほとんどの場合、最も重要なサンプルを削除した後に最も迅速なパフォーマンス低下を示し、最も重要でないサンプルを削除した後に最も遅いパフォーマンスの低下を示し、競合する手法(Leave-One-OutおよびData Shapley)と比較してノイズの多いラベルの識別におけるDVRLの優位性を強調しています。
・ノイズの多いラベルによる堅牢な学習
価値の低いサンプルを削除せずに、DVRLがノイズの多いデータを直接確実に学習できるかどうかを検討しました。理想的には、DVRLが収束するとノイズの多いサンプルは低いデータ値を割り当てられるため、高性能モデルが達成されます。
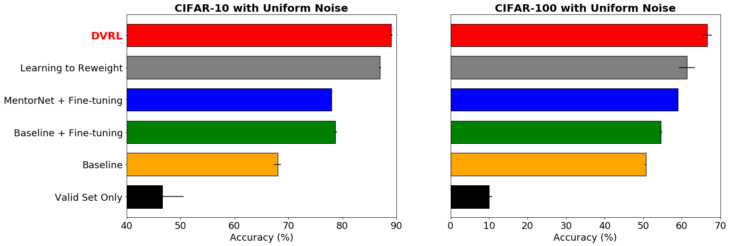
ノイズの多いラベルを使用時の堅牢な学習
CIFAR-10およびCIFAR-100データセットでResNet-32およびWideResNet-28-10の精度をテストし、ラベルに均一なランダムノイズが40%含まれています。DVRLは、メタ学習に基づく他の一般的な方法よりも優れています。
ノイズの多いラベルの影響を最小限に抑えるために、DVRLを使用した最先端の結果を示します。これらは、DVRLが複雑なモデルや大規模なデータセットに拡張できることも示しています。
・ドメイン適応
トレーニングデータセットが検証およびテストデータセットとは大幅に異なる分布に由来するシナリオを検討します。
データ値推定器は、検証データセットの分布に最も一致するサンプルをトレーニングデータセットから選択することにより、このタスクに役立つことが期待されます。
次の3つのケースに焦点を当てました。
(1)画像検索結果(低品質なWebスクレイピング画像)をHAM 10000データ(高品質医療画像)を使用して、皮膚病変分類タスクに適用する
(2)数字認識タスク用のMNISTデータセットをUSPSデータ(異なる視覚領域)を使っての数字認識タスクに適用する
(3)電子メールのスパムデータをSMSデータセット(別のタスク)を使ってスパムを検出タスクに適用する
DVRLは、データ評価者と対応する予測モデルを共同で最適化することにより、ドメイン適応を大幅に改善します。
| source | Target | Task | Baseline | Data Shapley | DVRL |
| HAM10000 | Skin Lesion Classfication | 0.296 | 0.378 | 0.448 | |
| MNIST | USPS | Digit Recognition | 0.308 | 0.391 | 0.472 |
| SMS | Spam Detection | 0.684 | 0.864 | 0.903 |
結論
各トレーニングサンプルが予測モデルのトレーニングで使用される可能性を決定する、データ評価のための新しいメタ学習フレームワークを提案します。
以前の研究とは異なり、私たちの方法は、データ評価を予測モデルのトレーニング手順に統合し、予測とDVEが互いのパフォーマンスを向上できるようにします。
RLを介してトレーニングされたDNNを使用して、このデータ値推定タスクをモデル化し、ターゲットタスクのパフォーマンスを表す小さな検証セットから報酬を取得します。
計算効率の高い方法で、DVRLは、ドメイン適応、破損したサンプルの発見、および堅牢な学習に役立つトレーニングデータの高品質なランキングを提供できます。 DVRLは、さまざまなタイプのタスクとデータセットで代替方法を大幅に上回っていることを示しています。
謝辞
トーマス・フィスターの貢献に感謝します。
3.DVRL:強化学習を使って学習用データの影響を推定(2/2)関連リンク
1)ai.googleblog.com
Estimating the Impact of Training Data with Reinforcement Learning
2)proceedings.icml.cc
Data Valuation using Reinforcement Learning(PDF)
3)aihub.cloud.google.com
Domain Adaptation using DVRL
Corrupted Sample Discovery & Robust Learning using DVRL
Robust Transfer Learning on Image Data with DVRL
Data Valuation using DVRL

