
1.Image GPT:自然言語処理用の人工知能で画像を生成(2/3)まとめ
・モデルは画像生成を学んだ際に物体のカテゴリについても学習している可能性がある
・本研究で、より良い生成モデルがより強力な分類パフォーマンスを達成する事が示された
・この結果は脳が最初に分析を行いその結果を合成していると言う説を補強している
2.合成による分析とは?
以下、openai.comより「Image GPT」の意訳です。元記事の投稿は2020年6月17日、Mark ChenAlecさんとRadfordIlya Sutskeverさんによる投稿です。
アイキャッチ画像のクレジットはPhoto by Soragrit Wongsa on Unsplash
言語GPTから画像GPTへ
自然言語を扱う研究分野では、次に現れる単語を予測する事を学習させた教師なし学習アルゴリズム(GPT-2やBERTなど)が非常に成功しており、様々な言語タスクで最高のパフォーマンスを実現しています。
この成功の考えられる理由の1つは、実際の言語タスクの実例が文章中に自然に含まれている事です。
一般的な文章では、質問文の後に回答文が続くことが多く(質問回答タスクに役立つ可能性があります)、文の一節の後にその要約が続くことがよくあります。(文章要約タスクに役立つ可能性があります)。
対照的に、画素の並びには、それらが属する画像が何であるかを示すラベルは明確に含まれていません。
しかし、この明示的な教師情報がなくても、画像でGPT-2が機能する理由はまだあります。次に出現する画素を予測するようにトレーニングされた十分に大きなtransformerは、明確に認識できる物体を使って多様なサンプル画像を生成する事を最終的に学習している可能性があります。
「合成による分析(Analysis by Synthesis)」として知られるアイデアは、モデルが画像の生成を学んだ際に、物体のカテゴリについても学習している事を示唆しています。
多くの初期の生成モデルはこのアイデアに動機付けられており、最近では、BigBiGANが有望なサンプルと特徴表現を生成した事例でした。
私達の研究では、最初に、より良い生成モデルがより強力な分類パフォーマンスを達成することを示します。次に、生成機能用にGPT-2を最適化することにより、多くの設定でトップレベルの分類パフォーマンスを実現できる事を示し、「合成による分析」の更なる証拠を提供します。
一般的な教師なし学習
生成シーケンスモデリングは、普遍的で、広い用途に使える一般性を持つ、教師なし学習アルゴリズムです。
全てのデータ型はバイトの並びとして表すことができるため、追加のエンジニアリング作業なしで、transformerを任意のデータ型に直接適用できます。
私達の研究は、自然言語でGPT-2をトレーニングするために使用されたアーキテクチャを画像生成に直接適用する事により、この一般性をテストする事でした。私達は、relative attention、sparse attention、 2-D position embeddingsなどの手法や畳み込みなど、画像分野固有の知識を手作業で取り込む事を意図的に放棄することを選択しました。
この一般性の代償として、私達の手法は、教師なし設定で競争力のあるパフォーマンスを達成するために、かなり多くの計算量を必要とします。
実際、対照的な手法は、画像から高品質な特徴表現を生成するための最も計算効率の高い方法です。
しかしながら、教師なしtransformerモデルが教師なし畳み込みネットと競合可能な事を示す際に、「手動でコード化された特定分野に固有の知見」と「計算量」がトレードオフできるという証拠を提供します。
コード化するための知見があまりない新しい研究分野では、コンピュータパワーの規模を拡大する事はテストに適切な手法のようです。
具体的な手法
ImageNetで、それぞれ7,600万、4億5500万、および14億のパラメータを持つtransformerであるiGPT-S、iGPT-M、およびiGPT-Lをトレーニングしました。また、ImageNetとWebからの画像を組み合わせて、68億のパラメータを持つtransformersであるiGPT-XLをトレーニングしました。dense attentionを使って長いシーケンスをモデル化するのは大量の計算量が必要になるため、32×32、48×48、および64×64の低解像度画像を使ってトレーニングしています。
計算コストをさらに削減するために更に低い解像度の画像を使って作業することは魅力的ですが、以前の研究では、これ以上解像度を下げると人間の画像分類パフォーマンスが急劇に下回り始める事が示唆されています。
代替手段として、昔のカラー表示パレットにヒントを得て、画素を表す独自のビットカラーパレットを作成します。このパレットを使用すると、色を忠実にエンコードしながら、標準(R, G, B)パレットを使った時よりサイズを1/3に短縮した入力データを得る事ができます。
実験結果
モデルのパフォーマンスを評価するために使用した2つの手法があり、どちらも実際の分類タスクを用います。
1つ目は、線形探触子(linear probe)と呼ばれる手法で、トレーニングされたモデルを使用して画像から特徴表現を抽出し、ロジスティック回帰を行いラベルに適合させます。2番目の手法は、下流タスクのデータセットにモデル全体を微調整します。
次の画素を予測するタスクは明らかに画像分類タスクと関連がないため、(画素を予測するタスクに最適化されている)最終レイヤーの特徴表現では、物体のカテゴリを予測できない可能性があります。
最初の結果は、特徴表現の品質が急激に増加し、次に後半のレイヤーに進むに連れ、緩やかに減少していく事を示しています。
この動作は、transformerを使った生成モデルが2つのフェーズで動作することを示しています。
最初のフェーズでは、画素の周囲の情報も含んだ画像特徴表現を構築するために、各位置で周囲情報を収集します。第2フェーズでは、この周囲の情報を含んだ特徴表現を使用して、次の画素を予測するタスクを解決します。
線形探触子(linear probe)で観察された2段階パフォーマンスは、別の教師なしニューラルネットであるボトルネックオートエンコーダー(bottleneck autoencoder)を彷彿させます。ボトルネックオートエンコーダーは、中心部の特徴表現が使用できるように手動で設計されています。
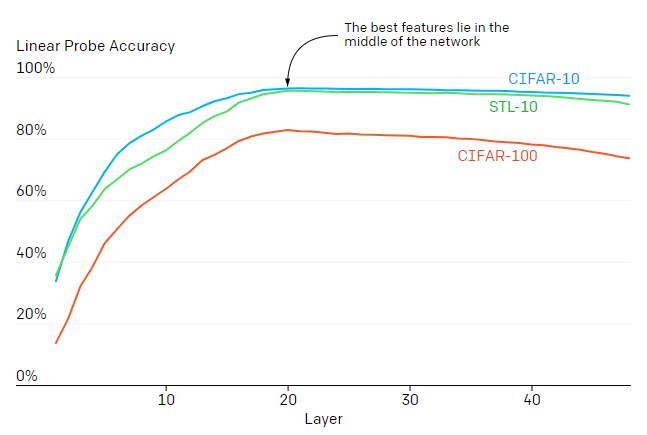
特徴表現の品質は、どの位置のレイヤーかに大きく依存します。教師ありモデルとは対照的に、これらの生成モデルの最良の特徴表現はネットワークの中央にあります。
3.Image GPT:自然言語処理用の人工知能で画像を生成(2/3)関連リンク
1)openai.com
Image GPT
Generative Pretraining from Pixels V2(PDF)
2)github.com
openai / image-gpt
