
1.Lookout:視覚に困難を抱える人のためにスマホで商品を識別(2/2)まとめ
・LookoutはMediaPipe Box trackingやScaNNを使って実装されている
・大規模な分類モデルであるNASNetを教師モデルとしてトレーニングを行っている
・OCR結果はインデックス検索には使用せずスコアリングにのみ使用している
2.Lookoutの構成
以下、ai.googleblog.comより「On-device Supermarket Product Recognition」の意訳です。元記事の投稿は2020年8月11日、Chao Chenさんによる投稿です。
アイキャッチ画像のクレジットはPhoto by Paul Gilmore on Unsplash。
Lookoutのデザイン
Lookoutシステムは、フレームキャッシュ、フレームセレクター、検出器、オブジェクトトラッカー、Embedder、インデックスサーチャー、OCR、スコアラー、結果プレゼンターで構成されています。
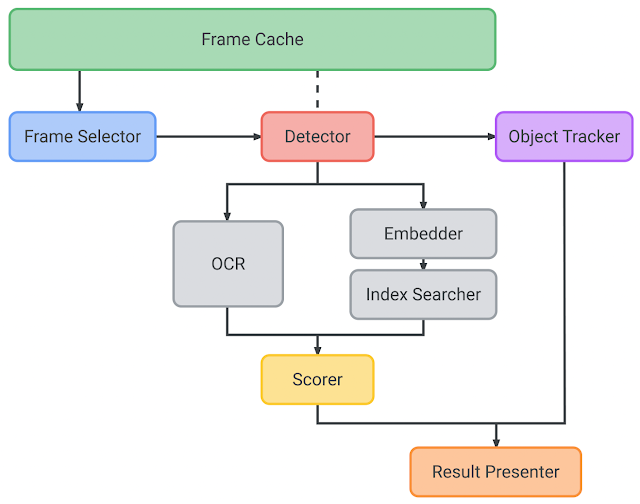
製品認識パイプラインの内部アーキテクチャ
(1)フレームキャッシュ
フレームキャッシュは、パイプライン内の入力カメラフレームのライフサイクルを管理します。他のモデルコンポーネントからの要求に応じて、YUV / RGB /グレーイメージを含むデータを効率的に配信し、データライフサイクルを管理して、複数のコンポーネントから要求された同じカメラフレームを繰り返し変換する事を防ぎます。
(2)フレームセレクター
ユーザーがカメラのビューファインダーを製品に向けると、軽量のIMUベースのフレームセレクターがプレフィルターステージとして実行されます。
角回転速度(deg/sec)に基いて測定された揺らぎ(jitter)を元に、カメラから継続的に受信する画像ストリームから特定の品質基準(画質と遅延のバランス)に最も一致するフレームを判断し、選択します。この手法により、高品質の画像フレームのみを選択的に処理し、ぼやけたフレームをスキップする事が可能になり、エネルギー消費を最小限に抑える事ができます。
(3)検出器(Detector)
次に、選択された各フレームが製品検出器モデルに渡されます。このモデルは、フレーム内の関心領域(別名、検出境界ボックス)を提案します。検出器モデルアーキテクチャは、高品質と低遅延のバランスをとるためMnasNetバックボーンを備えたシングルショット検出器を使っています。
(4)オブジェクトトラッカー
MediaPipe Box trackingは、検出された境界ボックスをリアルタイムで追跡するために使用され、重要な役割を果たします。検出された様々なオブジェクトの間のギャップを埋め、検出頻度を減らし、エネルギー消費を減らします。
オブジェクトトラッカーはオブジェクトマップも維持します。オブジェクトマップは実行時に各オブジェクトに一意のオブジェクトIDが割り当てられ、これは後で結果プレゼンターがオブジェクトを区別し、同一オブジェクトを複数回ランク付けする事を避けるために使用されます。
検出が実行される毎に、トラッカーは新しいオブジェクトをマップに登録するか、既存のオブジェクトを新しい境界ボックスで更新します。これは、既存のオブジェクト境界ボックスと検出結果のIoU(Intersection over Union)を使用して行われます。
(5)Embedder
検出器から関心領域(ROI:Regions Of Interest)がembedderモデルに送信され、embedderモデルは64次元のembeddingを計算します。
embedderモデルは、最初に大規模な分類モデル(NASNetに基づく教師モデルで何万ものクラスを分類可能)からトレーニングされます。
入力画像を「embedding空間」に投影するためにモデルにembeddingレイヤーが追加されます。embedding空間に存在する2つの点が近接している事は、それらの元となった画像が視覚的に類似していることを意味します。(つまり、2つの画像が同じ製品を示していると言う事です)
embeddingsのみを分析することで、モデルが柔軟になり、新製品が発表される度に再トレーニングする必要がなくなります。
ただし、教師モデルは大きすぎてオンデバイスで直接使用できないため、生成されるembeddingを使用して、モバイル対応の小規模な生徒モデルをトレーニングします。
生徒ネットワークは、入力画像をembedding空間の点に割り当てますが、教師ネットワークが割り当てる点と同じ点に割り当てるように学習します。
最後に、主成分分析(PCA:Principal Component Analysis)を適用して、embeddingベクトルの次元を256から64に減らし、デバイスに格納するためのembeddingを効率化します。
(6)インデックスサーチャー
インデックスサーチャーは、検索画像のembeddingを使用して、事前に作成され相性が良いScaNNインデックスに対してKNN検索を実行します。
結果として、製品名、パッケージサイズなどのメタデータを含む最上位のインデックスドキュメントが返されます。インデックス検索の待ち時間を短縮するために、すべてのembeddingは、k平均法でクラスター化されています。検索時に、関連するデータが含まれるクラスタが実際の距離計算のためにメモリに読み込まれます。
品質を犠牲にすることなくインデックスのサイズを小さくするために、インデックス作成時に「最近傍探索用の製品量子化手法(Product quantization for nearest neighbor search)」を使用しています。
(7)OCR
内容量、味付けなどの追加情報を抽出するために、各カメラフレームのROIでOCRが実行されます。従来の手法ではOCR結果をインデックス検索に使用していましたが、ここではスコアリングにのみ使用します。OCRテキストによって通知される適切なスコアリングアルゴリズムは、スコアラー(後述)が正しい結果を判断するのに役立ち、特に複数の製品に似たのパッケージがある場合に精度を向上させます。
(8)スコアラー
スコアラーは、入力としてembedding(インデックス検索結果を含む)およびOCRモジュールの出力を受け取り、以前に取得した各インデックスドキュメント(インデックスサーチャーを介して取得したembeddingとメタデータ)のそれぞれにスコアを付けます。
スコアリング後の上位結果が、システムからの最終的な認識として使用されます。
(9)結果プレゼンター
結果プレゼンターは、上記のすべての結果を取り込み、音声合成システムを介して製品名を発声する事で、ユーザーに結果を表示します。

スイスのスーパーマーケットで行ったオンデバイス製品認識の初期実験
結論/今後の作業
本投稿で説明したスマホ上で実行可能なシステムを使用すると、詳細な製品情報(栄養成分、アレルゲンなど)、顧客評価、製品比較、買い物リストとの連携、価格追跡などなど、様々な新しい店内体験を実現できます。私達は、これらの将来のアプリケーションの可能性を探求することに興奮しており、それと同時に基礎となるオンデバイスのモデルの品質と堅牢性を向上させるための研究を続けていきます。
謝辞
ここで説明されている作品は、Abhanshu Sharma, Chao Chen, Lukas Mach, Matt Sharifi, Matteo Agosti, Sasa Petrovic 及び Tom Binderによって作成されました。この作業は、Alec Go, Alessandro Bissacco, Cédric Deltheil, Eunyoung Kim, Haoran Qi, Jeff Gilbert そして Mingxing Tanから受けた支援と援助なしでは不可能でした。
3.Lookout:視覚に困難を抱える人のためにスマホで商品を識別(2/2)関連リンク
1)ai.googleblog.com
On-device Supermarket Product Recognition
2)lear.inrialpes.fr
Product quantization for nearest neighbor search(PDF)


コメント