
1.YouTuber向けのSmartReply機能が実装(2/2)まとめ
・文字単位の処理は単語単位の処理よりも文字列の並びが長くなり推論速度が遅すぎた
・WaveNetが使った拡張手法を適用し計算量と品質の間で適切なトレードオフを実現
・最終的に単一のクロスリンガルモデルで単語単位ではなく文字単位で文章を理解するSmartReplyが誕生
2.文字単位の処理を実現した手法
以下、ai.googleblog.comより「SmartReply for YouTube Creators」の意訳です。元記事の投稿は2020年7月1日、Rami Al-Rfouさんによる投稿です。
アイキャッチ画像のクレジットはPhoto by Lidya Nada on Unsplash
初期の結果、特に絵文字やタイプミスのあるコメントの処理は有望でした。
しかし、文字単位の処理は単語単位の処理よりも文字列の並びが長くなるため、推論速度は製品化するには遅すぎました。更に、self-attentionレイヤーの計算の複雑さは、長さに相関して二次関数的に増大します。
私達はWaveNetで適用された拡張手法と同様な、ネットワークの各レイヤーに時間削減レイヤー(temporal reduction layers)を適用して文字の並びの長さを縮小しました。これにより、計算量と品質の間で適切なトレードオフが得られました。
以下の図は、デュアルエンコーダーネットワークを示しています。これは、コメントと返信の両方をエンコードし、対照的な目的でネットワークをトレーニングする事で潜在的な特徴表現間の伝達情報量(mutual information)を最大化します。
エンコードは、embedding化した後にtransformerに一連のバイトを供給することから始まります。
後続の各レイヤーの入力は、各文字を同じ割合で減らす事で削減されます。複数のtransformer層を適用した後、入力シーケンスの長さが大幅に切り捨てられ、計算の複雑さが大幅に軽減されます。
この圧縮手法は、average poolingなどの他の演算で置き換えることができますが、より洗練された手法から得られる利益に私達が気づかなかったため、単純化のために拡張する事にしました。
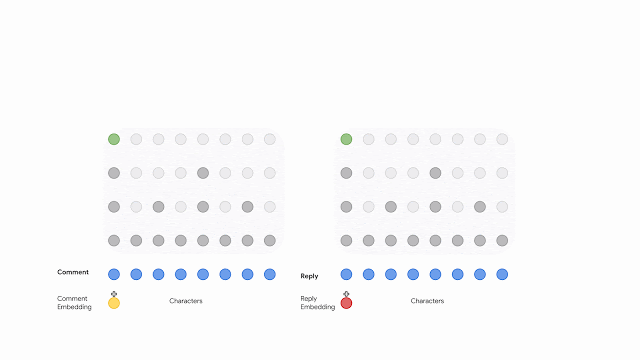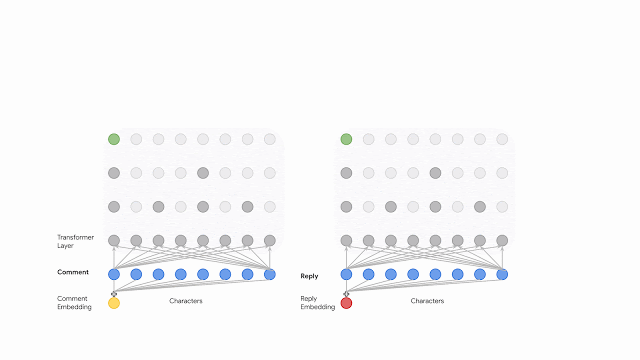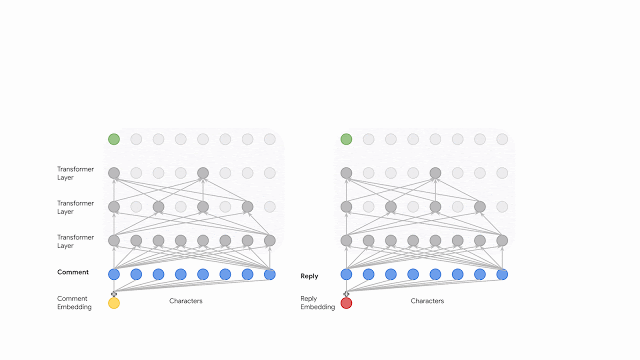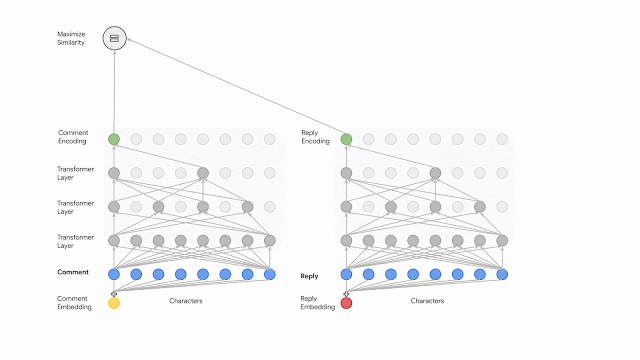
対照的な目的を通じてコメントとその返信の間の伝達情報量を最大化するデュアルエンコーダーネットワーク。各エンコーダーには一連のバイトが供給され、計算効率の高い拡張transformer ネットワークとして実装されます。
それら全てを学ぶモデル
言語ごとに個別のモデルをトレーニングする代わりに、サポートされている全ての言語に対して単一のクロスリンガルモデルをトレーニングする事にしました。
これにより、複数言語が混在しているコメント欄で使用する事が可能になり、モデルは1つの言語で学習した言語間で共通の知識、絵文字や数字などに関する知識を別の言語に流用できます。
更に、単一モデルを使用すると、メンテナンス時と更新時の手間が簡素化されます。モデルは英語とスペイン語向けがリリースされていますが、このクロスリンガルアプローチ固有の柔軟性により、将来的に他の言語にも拡張できるようになっています。
モデルによって生成された多言語の返信案セットのエンコーディングを調べると、モデルが属する言語に関係なく、モデルが適切な返信をクラスター化していることがわかります。このクロスリンガルな機能は、モデルの学習中に並列コーパスを使っていないのに出現しました。
訳注:つまり、機械翻訳モデルなどが一般的に使用する「同じ文章を複数言語で表現した学習用データ」を使っていないので「言語Aの単語a」=「言語Bの単語b」というアプローチで学習する事は出来なかったはずで、どうにかして「言語Aの単語aの意味」=「言語Bの単語bの意味」を学び取ったっぽいって事です。
以下の図は、3つの言語について、モデルの入力コメントに対する反応を精査し、モデルが「言葉の持つ意味」によってどのように応答をクラスタ化するかを示します。
例えば、英語のコメント「これは素晴らしい動画です(This is a great video)」には、「ありがとう!(Thanks!)」の意を持つ多言語の適切な返信が周囲に配置されています。
更に、他の言語で最も近い返信を調べると、それらも同じ意味で適切であることがわかります。
二次元に投影した以下の図では、同じ意味を持つ返信で構成されるいくつかのクロスリンガルクラスタが表示されています。このクラスタリングは、モデルが、サポートされている言語で豊かなクロスリンガルなユーザー体験をどのようにサポートできるかを示しています。
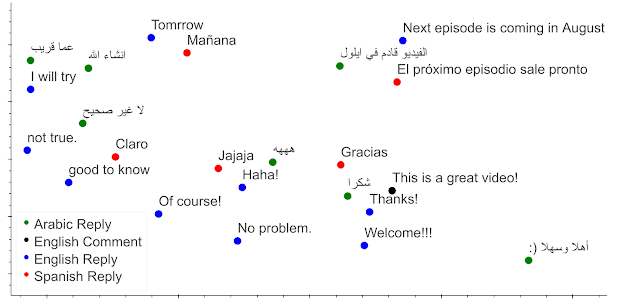
架空のコメントと潜在的な応答リストが提示された時のモデルエンコーディングの二次元投影
英語のコメント(黒色)の周辺は、英語での適切な返信と、スペイン語およびアラビア語でその英語に対応する意味を持つ言葉が配置されています。
ネットワークは、英語の返信とその翻訳文を適切に配置できていますが、並列コーパスを使わずにこれを学習した事に注目してください。
返信案の提案が行われるのはいつですか?
私達の目標はクリエイターを支援することなので、SmartReplyが役立つ可能性が非常に高い場合にのみSmartReplyが提案を行うようにする必要があります。
理想は、作成者がコメントに返信する可能性が高く、モデルが賢明で具体的な応答案を提供できる可能性が高い場合にのみ、提案が表示されます。これを実現するために、どのコメントでSmartReply機能を起動するべきかを識別する補助モデルをトレーニングしました。
結論
YouTube向けのSmartReplyの提供を開始しました。
最初は、英語とスペイン語のコメント用であり、これはクロスリンガルで、単語単位ではなく文字単位で文章を理解する最初のSmartReplyです。
YouTubeは、様々なコンテンツを生成する多様なユーザー層を基盤とするグローバルなプロダクトです。
従って、このグローバルな聴衆のコメントを継続的に改善することが重要であり、SmartReplyはこれを実現する方向へ踏み出した強力な第一歩となります。
謝辞
YouTubeクリエイター向けのSmartReplyは、Golnaz Farhadi, Ezequiel Baril, Cheng Lee, Claire Yuan, Coty Morrison, Joe Simunic, Rachel Bransom, Rajvi Mehta, Jorge Gonzalez, Mark Williams, Uma Roy, など多くの人々によって開発されました。
Nikhil Dandekar, Eileen Long, Siobhan Quinn, Yun-hsuan Sung, Rachel Bernstein, 及び Ray Kurzweilによるリーダーシップのサポートに感謝します。
3.YouTuber向けのSmartReply機能が実装(2/2)関連リンク
1)ai.googleblog.com
SmartReply for YouTube Creators
2)arxiv.org
Bridging the Gap for Tokenizer-Free Language Models
3)www.aaai.org
Character-Level Language Modeling with Deeper Self-Attention

