
1.RepNet:人工知能で動画内の反復行動を数える(1/2)
・月の満ち欠けや心拍や呼吸、製造ラインや交通パターンなどの反復行動は現実世界で一般的
・反復行動を理解する事でより複雑な行動パターンを認識できたり様々な洞察を得る事ができる
・RepNetは様々な反復行動を含む動画を受け取り、その繰り返し期間を認識可能なモデル
2.RepNetとは?
以下、ai.googleblog.comより「RepNet: Counting Repetitions in Videos」の意訳です。元記事は2020年6月22日、Debidatta Dwibediさんによる投稿です。
繰り返し動作に着目した研究は過去にTCC(Temporal Cycle-Consistency)が発表されていましたが、同じ方の投稿です。TCCより一般化性能が向上して学習の際に使った動画内に出てこない繰り返し動作も対応可能になったそうです。
アイキャッチ画像は地球の画像を元にTSMの挙動を説明した箇所が大変わかりやすかったので感銘を受けて捜した月の画像でクレジットはPhoto by Ryan Tasto on Unsplash
月の満ち欠けや心拍や呼吸などの自然のサイクルから、製造ラインや交通パターンで見られるような人為的な繰り返しまで、私たちの日常生活の様々な場面で反復行動を見る事ができます。
反復行動には、広く一般的だと言うだけでなく、研究者がそこから様々な洞察を引き出すことができため興味の対象となっています。
複数回行動が発生する根本的な原因が背後に何かあるのだろうか?
反復行動を理解するために役立つ可能性のある段階的な変化が存在するのではないか?
時々、反復行動は明確な「行動単位」、つまり反復行動を構成する「細分化された行動」を提供します。
例えば、人が玉ねぎを刻んでいる場合、行動単位は、追加で玉ねぎを一切れ切る行動です。
これらの行動単位は、より複雑な活動を示している可能性があり、これらの行動単位にラベルを付けなくても、より細かい時間間隔でより多くの行動を自動的に分析できる場合があります。
上記の理由により、私達の世界を長時間観察して理解することを目的とする知覚システムは、繰り返し行動を理解するシステムから恩恵を得ます。
私達の論文「Counting Out Time: Class Agnostic Video Repetition Counting in the Wild」では、幅広い反復行動を理解できるRepNetを紹介しています。
RepNetは、人間の運動や工具の使用場面、走っている動物や羽ばたく鳥、振り子の揺れ、およびその他の多種多様な反復行動を理解できる単一モデルです。
以前の研究(TCC)では、繰り返し行動の時間的一貫性制約を利用して、同じ行動を撮影した様々な動画をきめ細かいレベルで認識する事に成功しました。
それに対し、今回の研究では、単一動画内の繰り返し行動を認識できるシステムを紹介します。
このモデルとともに、対象となる繰り返し行動を限定せずに動画内の繰り返し行動をカウントする能力をベンチマークするためのデータセットと、RepNetを実行するためのColabノートブックを公開しています。
RepNet
RepNetは、様々な種類の周期的な行動を含む動画(トレーニングに使った動画内には含まれていなかった行動もOK)を入力として受け取り、動画内に存在する繰り返し動作の期間を返すモデルです。
従来手法は、繰り返し動作を数える問題を、フレーム内の画素強度を直接比較することで対処してきました。
しかし、現実世界の動画には、カメラの動き、フィールド内の物体が写り込んで邪魔になる事、縮尺の大幅な違い、及び形状変化など様々なノイズ要因があり、そのため、これらに影響されない不変の特徴を学習する必要があります。
これを実現するために、反復期間を直接推定するために、機械学習モデルをエンドツーエンドでトレーニングします。
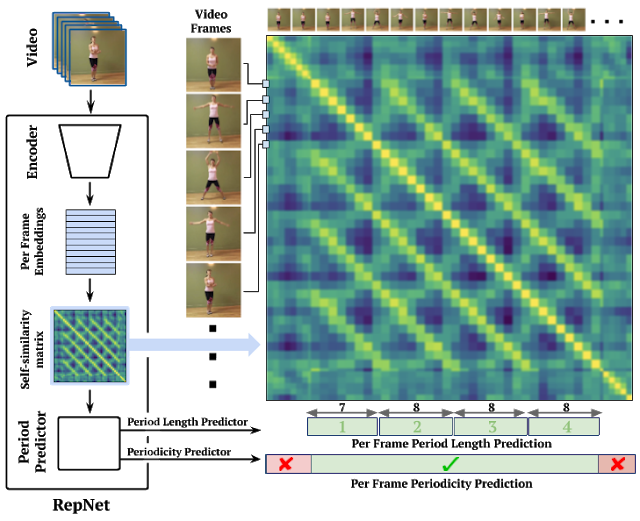
モデルは3つの部分で構成されています。フレームエンコーダー、以下で説明する時間自己相似行列(temporal self-similarity matrix)と呼ばれる中間特徴表現、および周期予測器(period predictor)です。
まず、フレームエンコーダーはResNetアーキテクチャーをフレーム毎のモデルとして使用して、ビデオの各フレームのembeddingsを生成します。ResNetアーキテクチャーは、多数の画像及びビデオタスクで成功したために選択されました。
ビデオの各フレームをResNetベースのエンコーダーに渡すと、一連のembeddingsが生成されます。
この時点で、ビデオ内の各フレームのembeddingsを他の全てのフレームと比較することにより、時間的自己相似性行列(TSM:Temporal Self-similarity Matrix)を計算します。
この行列により、後続のモジュールが繰り返しカウントを分析するのが簡単になります。
このプロセスは、各ビデオフレームの自己相似性を明らかにし、期間推定を可能にします。
以下の動画で示します。
TSMが地球の昼夜サイクルの画像を処理するデモ
次に、フレーム毎にTransformerを使用して、繰り返しの周期と周期性を予測します。
(つまり、フレームが周期的なプロセスの一部であるかどうかを一連のTSMの類似性から直接予測します)
周期を取得したら、周期的な単位で捕捉されたフレームの数を周期の長さで割って、フレーム毎の数を取得します。
これを合計して、ビデオ内の繰り返し数を予測します。
時間的自己相似性行列(TSM:Temporal Self-Similarity Matrix)
前述の地球の昼夜サイクルを扱うTSMは、固定周期が繰り返される動画を扱った理想的な事例です。
以下の3つの例で示されているように、現実世界の動画を扱うTSMは、世界の魅力的な構造を明らかにします。
ジャンピングジャック(Jumping jacks)は一定の周期で動作が繰り返される理想的な周期動作に近いのに対し、バウンドを繰り返すボールは徐々に運動エネルギーを失い、バウンドするボールの周期は減少していきます。
また、コンクリートを混ぜている作業者のビデオは、前後の動きが発生しない期間に挟まれた繰り返し行動を示しています。これらの3つの動作は、学習済みTSMで明確に区別できます。モデルは風景の細かい変化に注意を払う事ができるためです。
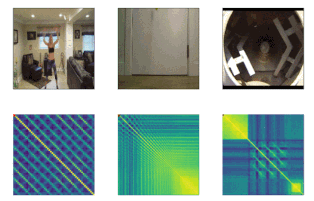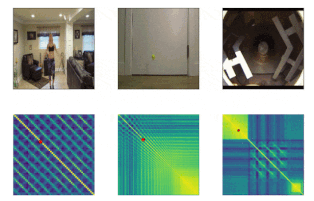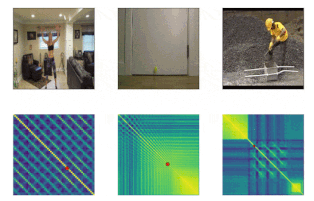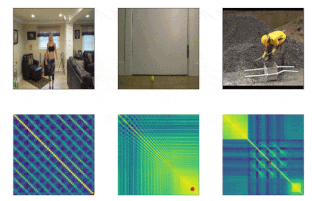
ジャンピングジャック(一定の期間。Kineticsデータセットから取得したビデオ)、弾むボール(減少していく期間。Kineticsから)、コンクリートとの混合(ビデオ内の非周期的な期間。PERTUBEデータセットより)
TSMをRepNetの中間層として使用する利点の1つは、Transformerによる後続の処理が、特徴表現空間ではなく自己相似空間で行われることです。
これにより、未見の行動に対しても一般化が促進できます。例えば、上の動画のジャンピングジャックや水泳などの様々なアクションによって生成されたTSMは、アクションが同じペースで繰り返されている限り、同じです。
そのため、一部の繰り返し行動のみを使って学習をしても、初見の繰り返し行動に対しても一般化出来る事を期待できます。
3.RepNet:人工知能で動画内の反復行動を数える(1/2)関連リンク
1)ai.googleblog.com
RepNet: Counting Repetitions in Videos
2)openaccess.thecvf.com
Counting Out Time: Class Agnostic Video Repetition Counting in the Wild(PDF)
3)colab.research.google.com
repnet_colab.ipynb
4)storage.googleapis.com
countix.tar.gz

