
1.無限に続く行動履歴を学習可能な強化学習のオフポリシー評価(2/2)まとめ
・定常分布がわからなくても重みの分布がターゲットポリシーの分布が持つ属性を満たす確認すれば良い
・「トリッキー」な数学的手法を使い履歴データからターゲットポリシーの予想報酬を見積もる事ができる
・古典的な制御問題で本手法のパフォーマンスを比較したところ従来手法より実際に優れていた
2.Infinite-Horizon Reinforcement Learningの性能
以下、ai.googleblog.comより「Off-Policy Estimation for Infinite-Horizon Reinforcement Learning」の意訳です。元記事は2020年4月17日、Ali MousaviさんとLihong Liさんによる投稿です。
アイキャッチ画像のクレジットはPhoto by Sam Shin on Unsplash
この問題を解決する1つの方法は、この分布が実際に何であるかわからなくても、重みの分布がターゲットポリシーの分布が持つ属性を満たしている事を確認することです。
幸いなことに、これを解決するためにいくつかの「トリッキー」な数学的手法を利用できます。
完全な詳細は私達の論文で見つかりますが、結果として、(ターゲットポリシーを使ってデータを収集していないため)ターゲットポリシーの定常分布はわからなくとも、backward operatorを含む最適化問題を解くことで分布を決定できます。backward operatorでは、入力と出力の確率分布を使用して、エージェントが現在の状態とアクションから特定の状態とアクションにどのように遷移するかを示します。
この作業が完了すると、履歴データからの報酬の加重平均により、ターゲットポリシーの予想報酬を見積もる事ができます。
実験結果
3つの状態と2つのアクションを持つModelWinと呼ばれる簡易環境を使用して、私達の研究を以前の最新のアプローチ(以降のグラフで「IPS」)、及び行動ポリシーから報酬を単純に平均化する単純な手法(naive method)比較しています。
以下の図は、行動ポリシーによって収集されたステップ数を変更したときの、ターゲットポリシーの報酬に関する二乗平均平方根誤差(RMSE)を示しています。
naive methodは大きな偏りに悩まされ、履歴を長くして収集データを増やしても、その誤差は変わりません。IPS法の推定誤差は、履歴が長くなると減少します。一方、私達の方法で示される誤差は、履歴が短くても小さくなります。
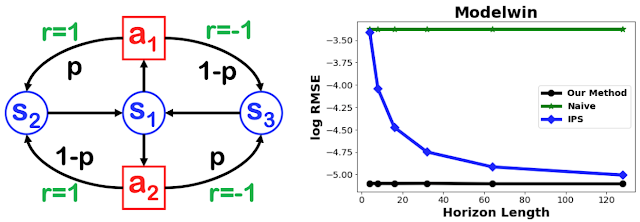
左:3つの状態(s1-s3)と2つのアクション(a1, a2)を持つModelWin環境
右:ModelWin環境を使い計測した様々なアプローチのRMSE(対数スケール)
私達のアプローチは、収束するために非常に長い履歴が必要であった従来の最先端の方法(IPS)と比較して、この単純な問題で非常に迅速に収束しました。
また、いくつかの古典的な制御問題について、このアプローチのパフォーマンスを他のアプローチ(naive estimator、IPS、model-based estimator)と比較しました。以下の図からわかるように、単純な平均パフォーマンスは、履歴の数にほとんど依存していません。この方法は、CartPole、Pendulum、MountainCarの3つのサンプル環境で他のアプローチよりも優れています。

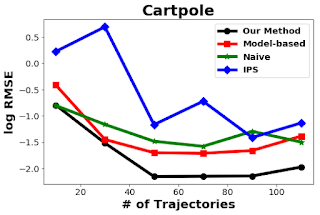

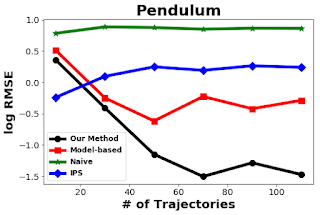

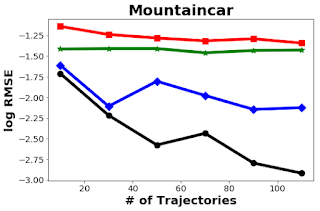
カートポール、ペンデュラム、マウンテンカーの3タスクで様々な手法を比較
左図は実行環境を示しています。右図は、横軸が行動ポリシーによって収集された履歴の数、縦軸がターゲットポリシーの報酬に関するRMSE(root mean squared error:二乗平均平方根誤差)。50回実行した結果に基づいています。
要約すると、本投稿では、行動ポリシーにより収集された履歴データを使用して、新しいターゲットポリシーの品質を評価する方法について説明しました。
この研究の興味深い将来の方向性は、特定領域の構造的な知識(structural domain knowledge)を使用してアルゴリズムを改善することです。興味のある読者の方は、私達の論文を読んで、この研究の詳細を学んでください。
謝辞
このプロジェクトに貢献してくれたQiang LiuとDenny Zhouに特に感謝します。
3.無限に続く行動履歴を学習可能な強化学習のオフポリシー評価(2/2)関連リンク
1)ai.googleblog.com
Off-Policy Estimation for Infinite-Horizon Reinforcement Learning
2)openreview.net
BLACK-BOX OFF-POLICY ESTIMATION FOR INFINITE-HORIZON REINFORCEMENT LEARNING(PDF)


コメント