
1.SEED RLによる大規模強化学習(3/3)まとめ
・SEED RLが4,160CPUで達成する性能と同等な性能を出すにはIMPALAでは14,000CPUが必要となる
・DeepMindラボでは毎秒240万フレームを達成、これは、以前の最先端のモデルIMPALAの80倍
・SEED RLによって今後は強化学習もGPUやTPUなどのハードウェアの進化の恩恵を受ける事が出来る
2.SEED RLの性能
以下、ai.googleblog.comより「Massively Scaling Reinforcement Learning with SEED RL」の意訳です。元記事の投稿は2020年3月23日、Lasse Espeholtさんによる投稿です。アイキャッチ画像のクレジットはPhoto by Kyle Head on Unsplash
実証実験
SEED RLは、一般的に使用されているArcade Learning Environment、DeepMind Lab環境、および最近リリースされたGoogle Research Football環境で試験されています。
| アーキテクチャー | アクセラレータ | アクター用CPU数 | Frame/秒 | IMPALAを1とした時の性能 |
| IMPALA | Nvidia P100 | 176 | 30,000 | 1.0 |
| SEED | Nvidia P100 | 44 | 19,000 | 0.6 |
| SEED | TPU v3, 2 cores | 104 | 74,000 | 2.5 |
| SEED | TPU v3, 8 cores | 520 | 330,000 | 11.0 |
| SEED | TPU v3, 64 cores | 4160 | 2,400,000 | 80.0 |
DeepMind Labを使用して行ったIMPALAとSEED RLの1秒あたりのフレーム数比較
SEED RLは、4,160個のCPUを使用して毎秒2.4Mフレームを実現しました。 同じ速度を達成するためには、IMPALAは14,000個のCPUを必要とします。
DeepMindラボでは、64のCloud TPUコアで毎秒240万フレームを達成しています。これは、以前の最先端の分散エージェントであるIMPALAよりも80倍向上しています。 これにより、実時間と計算効率が大幅に向上します。 IMPALAは、同じ速度でSEED RLの3~4倍のCPUを必要とします。
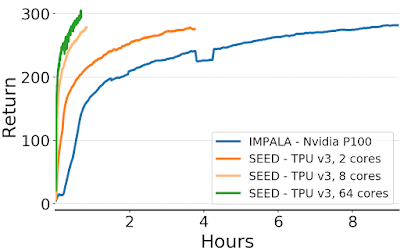
IMPALAとSEED RLでのDeepMind Labゲーム「explore_goal_locations_small」のエピソードリターン(つまり、報酬の合計)の比較。SEED RLを使用すると、トレーニングにかかる時間が大幅に短縮されます。
アーキテクチャが最新のアクセラレータを使った実行に最適化されているため、データ効率を向上させるためにモデルサイズを大きくすることは自然な流れです。モデルのサイズと入力解像度を大きくすることで、これまでに解決されていないGoogle Research Footballのタスク「ハード」を解決できることを示しています。
| アーキテクチャー | アクセラレータ | モデルサイズ/入力解像度 | Frame数 | スコア |
| SEED | TPU v3, 8 cores | Default | 500万 | -0.2 |
| SEED | TPU v3, 8 cores | Medium | 500万 | 0.12 |
| SEED | TPU v3, 8 cores | Large | 500万 | 0.46 |
| SEED | TPU v3, 64 cores | Large | 40億 | 4.76 |
Google Research Footballの「ハード」タスクにおける様々なアーキテクチャのスコア。
入力解像度とモデルを大きくすることでスコアが向上し、トレーニングを増やすことで、モデルがデォフォルトのAIを大幅に上回ることが示されています。
アーケード学習環境での結果を含む、追加の詳細は論文内で提供されてます。
SEED RLと今回提示された結果は、他のディープラーニング手法に強化学習が後れを取っていた「アクセラレータの活用」というフィールドで再び追いついたことを示しています。
謝辞
このプロジェクトは、Raphaël Marinier, Piotr Stanczyk, Ke Wang, Marcin Andrychowicz そして Marcin Michalskiの共同研究です。 また、可視化作業についてTom Smallにも感謝します。
3.SEED RLによる大規模強化学習(3/3)関連リンク
1)ai.googleblog.com
Massively Scaling Reinforcement Learning with SEED RL
2)arxiv.org
SEED RL: Scalable and Efficient Deep-RL with Accelerated Central Inference
IMPALA: Scalable Distributed Deep-RL with Importance Weighted Actor-Learner Architectures
3)github.com
google-research/seed_rl
4)openreview.net
Recurrent Experience Replay in Distributed Reinforcement Learning


コメント