
1.MediaPipe Objectron:モバイル上でリアルタイムに物体の三次元形状を認識(2/2)まとめ
・実世界データとAR合成データを組み合わせることで、精度を約10%向上させる事に成功
・バックボーンとなっている技術は、MobileNetv2上に構築されたエンコーダーデコーダーアーキテクチャー
・ モバイルパイプラインの効率をさらに高めるために、数フレームごとに1回だけモデルの推論を実行
2.AR Synthetic Data Generation
以下、ai.googleblog.comより「Real-Time 3D Object Detection on Mobile Devices with MediaPipe」の意訳です。元記事の投稿は2020年3月11日、Adel AhmadyanさんとTingbo Houさんによる投稿です。アイキャッチ画像のクレジットはPhoto by Yiran Ding on Unsplash
AR(拡張現実)を使ってトレーニングデータを合成
一般的に良くあるアプローチは、予測の精度を高めるために、実世界のデータを合成データで補完してテストデータを増やす事です。ただしこれを実現しようとすると、貧弱で非現実的なデータが生成されることが多く、写真のようなリアルなレンダリングに挑戦する場合は、多大な労力と計算が必要になります。
AR Synthetic Data Generationと呼ばれる私達の新しいアプローチは、仮想オブジェクトをARセッションデータの風景内に配置します。これにより、カメラポーズ、平面、照明を推定して活用する事が出来、物理的にもっともらしく、風景に一致するように仮想オブジェクトを配置できます。
このアプローチにより、位置関係を尊重し、実際の背景違和感なく適合するようにレンダリングされた物体を配置した高品質な合成データが得られます。 実世界のデータとARによる合成データを組み合わせることで、精度を約10%向上させることができました。

AR合成データ生成の例
机の上の白い箱は仮想物体で、実際に存在する青い本の横に違和感なくレンダリングされます。
3D物体検出用のMLパイプライン
単一のRGB画像から物体のポーズと物理的なサイズを予測するシングルステージモデルを構築しました。
モデルのバックボーンとなっている技術は、MobileNetv2上に構築されたエンコーダーデコーダーアーキテクチャーです。マルチタスク学習アプローチを採用しており、物体の形状タスクと検出タスク、回帰タスクにより予測を行います。
形状タスクはオプションです。利用可能な検証済みラベルに基いて、物体の形状信号(例:セグメンテーション)を予測します。トレーニングデータに形状を指定するラベルがない場合、形状タスクは実行できません。
検出タスクでは、ラベル付きの境界ボックスを使用し、ボックスの重心を中心にして、ボックスサイズに比例する標準偏差で、ボックスにガウス分布を当てはめます。検出タスクの目標は、この分布を予測し、そのピークが物体の中心位置を表すようにする事です。
回帰タスクは、境界ボックスの頂点8つの2D投影を推定します。境界ボックスの最終的な3D座標の取得は、確立しているポーズ推定アルゴリズム(EPnP)を活用します。
このアルゴリズムは物体の大きさを事前に知らなくても、物体の3D境界ボックスを復元できます。そして、3D境界ボックスがあれば、物体のポーズとサイズを簡単に計算できます。
下の図は、ネットワークアーキテクチャと3D物体検出の後処理を示しています。このモデルは、モバイルデバイスでリアルタイム(Adreno 650モバイルGPUで26 FPS)に実行できるほど軽量です。
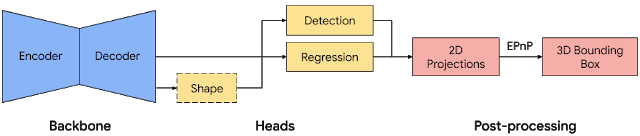
ネットワークアーキテクチャと3D物体検出の後処理

ネットワークの出力例
左図:推定境界ボックス付きの元の2D画像
中央図:ガウス分布によるオブジェクト検出
右図:予測セグメンテーションマスク
MediaPipeでの検出と追跡
モデルがモバイルデバイスによって撮影された全てのフレームに適用されると、各フレーム内で推定した3D境界ボックスが微妙に異なると言うあいまいさが原因で、映像が乱れる(jitter)可能性があります。
これを軽減するために、2Dオブジェクト検出および追跡ソリューションとして最近リリースされた検出+追跡フレームワーク(Box Tracking in MediaPipe)を採用しています。このフレームワークは、全てのフレームでモデルを動かす必要性を軽減し、モバイルデバイスでパイプラインをリアルタイムに保ちながら、より重い、したがってより正確なモデルを使用できるようにします。また、フレーム全体でオブジェクトの同一性を保持し、予測が時間的に一貫していることを保証し、画像の乱れを削減します。
モバイルパイプラインの効率をさらに高めるために、数フレームごとに1回だけモデルの推論を実行します。次に、以前のブログで説明したインスタントモーショントラッキングとMotion Stillsを使用して、予測を取得し、時間をかけて追跡します。新しい予測が行われると、重複している領域を考慮して検出結果と追跡結果を統合します。
研究者と開発者が私達のパイプラインに基づいて実験し、プロトタイプを作成することを奨励するために、エンドツーエンドのデモ用モバイルアプリケーションと2つのカテゴリ(靴と椅子)のトレーニング済みモデルを含むオンデバイスのMLパイプラインをMediaPipeでリリースしています。
幅広い研究開発コミュニティとソリューションを共有することで、新しいユースケース、新しいアプリケーション、新しい研究努力が促進されることを願っています。将来的には、モデルを更に多くのカテゴリに拡大し、オンデバイスでのパフォーマンスをさらに向上させる予定です。



実世界での3Dオブジェクト検出の例
謝辞
本投稿で説明した研究は、Adel Ahmadyan, Tingbo Hou, Jianing Wei, Matthias Grundmann, Liangkai Zhang, Jiuqiang Tang, Chris McClanahan, Tyler Mullen, Buck Bourdon, Esha Uboweja, Mogan Shieh, Siarhei Kazakou, Ming Guang Yong, Chuo-Ling Chang、そしてJames Bruceによって行われました。Aliaksandr Shyrokauと注釈付与チームの高品質な注釈への努力に感謝します。
3.MediaPipe Objectron:モバイル上でリアルタイムに物体の三次元形状を認識(2/2)関連リンク
1)ai.googleblog.com
Real-Time 3D Object Detection on Mobile Devices with MediaPipe
2)github.com
google/mediapipe
MediaPipe Objectron (GPU)
3)developers.googleblog.com
Box Tracking in MediaPipe


コメント