
1.Bi-Tempered Logistic Loss:ノイズの多いデータでニューラルネットをトレーニングするための損失関数(3/3)まとめ
・バイ テンパーは大きな外れ値にも小さな外れ値にもロジスティック損失より良く対応が出来ている
・今回の2つのパラメーター以外にも様々なパラメータがニューラルネットワークの最適化に使われている
・様々な最適化パラメータを全体で最適化できるようにする事が長期的な研究として計画されている
2.バイテンパーロジスティック損失の性能
以下、ai.googleblog.comより「Bi-Tempered Logistic Loss for Training Neural Nets with Noisy Data」の意訳です。元記事の投稿は2019年8月26日、Ehsan AmidさんとRohan Anilさんによる投稿です。
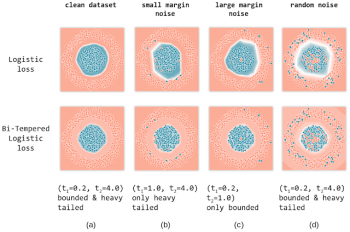
ノイズが無いケース
列aに、ロジスティック損失(上)とバイテンパーロジスティック損失(下)を使用して、ノイズのないデータセットでモデルをトレーニングした結果を示します。
白い線は、各モデルの決定境界を示しています。バイ テンパー損失関数の温度である(t1, t2)の値は、図の各列の下に示されています。
この例で選択した温度では、損失が制限され、伝達関数がテールヘビーになっている事に注意してください。ご覧のように、ロジスティック損失でもバイ テンパーロジスティック損失でも、2つのクラスを正常に分離する適切な決定境界を生成しています。
小さいマージンのノイズ
テールヘビーの効果を説明するために、決定境界の近くにあるサンプルの一部をランダムに選んで人為的に破壊します。つまり、これらのポイントのラベルを反対のクラスに反転します。ロジスティック損失とバイテンパー損失を使用して、マージンの小さいノイズを含むデータでネットワークをトレーニングした結果を列(b)に示します。
見てのとおり、ロジスティック損失はノイズが多いポイントに近い方向に決定境界を引き伸ばしてしまいます。これは、softmax関数のテール部が軽いため、活性化ベクトルにより低確率と見なされた分類を補償しようとしてしまうためです。
一方、t2を調整することによりテールが重い確率伝達関数を使用する事が出来るバイテンパー損失は、ノイズの多い例をうまく回避できます。
これは、ヘビーテールによって指数関数的な減衰が和らげられた事により説明できます。ノイズの多いポイントから決定境界を遠ざけながら(そして、損失値を小さく保ち)、高い確率値を割り当てています。
大きなマージンのノイズ
次に、大きなマージンを持つノイズが多い例を処理する2つの損失関数のパフォーマンスを比較評価します。(c)では、決定境界から遠く離れた場所、つまり円周の外側や円の中心部近くに存在するサンプルの一部をランダムに破損します
このケースでは、softmaxの確率をロジスティック損失と同じに保ち、バイテンパー損失の有界性のみを使用します。ロジスティック損失では制限がないため、ノイズのあるポイントに向かって決定境界を拡大する事で損失値を減少させようとします。
一方、t1の調整によって有界性が制限されたバイテンパー損失は、ノイズの多いサンプル毎に有限の損失を発生させます。その結果、バイテンパー損失はこれらのノイズの多いサンプルに寄ってしまう事を回避し、適切な決定境界を維持できます。
ランダムノイズ
最後に、2つの損失関数がトレーニングデータにランダムにノイズが混在する状況でどのように動作するか影響を調査します。このランダムなノイズは、小マージンと大マージンの両方のノイズが混在した事例で構成されていることに注意してください。
従って、温度を(t1、t2) = (0.2、4.0)に設定することにより、バイテンパー損失関数の有界性と尾部重さ特性の両方を使用しています。
最後の列(d)の結果からわかるように、ロジスティック損失はノイズの多いサンプルの影響を大きく受けており、明らかに適切な決定境界に収束できません。一方、バイ テンパーは、ノイズのない場合とほぼ同じ決定境界を回復できています。
まとめ
この研究では、大きなマージンの外れ値に対応可能な「焼戻し損失関数(tempered loss function)」を構築し、新しい「焼戻しsoftmax関数(new tempered softmax function)」にヘビーテールの概念を導入しました。
私達はバイ テンパーロジスティック損失関数を使用すると、多数の大規模な標準データセットでニューラルネットワークをトレーニングする際に、優れた経験的パフォーマンスを達成しました。(詳細については論文を参照してください)。
ただし、最先端のニューラルネットワークは、さまざまな変数に最適化されていることに注意してください。ほんの一例をあげても、アーキテクチャ、伝達関数、オプティマイザーの選択、ラベルのスムージングなど様々な変数があります。
今回の手法では、2つの追加の調整可能な変数、つまり(t1、t2)を導入しています。この結果を一般的に試されている様々な変数と体系的に「共同で最適化」する事により、大幅な更なる改善を達成できるのではないかと考えています。これはもちろん、より長期的な目標です。
また、トレーニングプロセスで温度パラメータを「焼きなまし(Annealing)」するアイデアを検討する予定です。
訳注:
熱処理をイメージした単語が多く登場していますが、プロセスをわかってないと逆にわかりにくくなるので以下に解説です。
金属を鍛える時には、高温に加熱した後に急速に冷却、つまり「焼き入れ」する事で鋼材を硬くし、粘りを出すために「焼戻し」をし、硬化を緩和するために「焼なまし」をし、歪みを均一化するために「焼ならし」を行います。
焼入れ(Quench Hardening)
焼戻し(Tempering)◎
焼なまし(Annealing)○
焼きならし(Normalizing)
Bi-Temperedは、「Bi」がバイナリ―のBi。2つの温度パラメータを使っているので「2つ」を意味するBiで、Temperedは「焼戻し」、なので、敢えて日本語に訳せば「2値焼きもどし法」かなと思います。対比される「ロジスティック」がカタカナで既に市民権を得ているように感じたので「バイ テンパー」とカタカナで倣いました。
将来的には、トリ テンパーやマルチ テンパー等の手法が登場し、アニーリング(Annealing)な手法、おそらくテンパーを自動的に最適化する手法なども研究されつつ、熱処理関連の単語は今後も追加使用されていくのだろうなと思います。
謝辞
このブログ投稿は、共著者である客員研究員のManfred Warmuth、およびGoogle ResearchのシニアリサーチサイエンティストTomer Koren、との共同研究結果を反映したものです。損失関数の理論的分析と大規模な標準データセットの実証結果を含む論文のプレプリントはarxiv.orgから入手できます。
3.Bi-Tempered Logistic Loss:ノイズの多いデータでニューラルネットをトレーニングするための損失関数(3/3)関連リンク
1)ai.googleblog.com
Bi-Tempered Logistic Loss for Training Neural Nets with Noisy Data
2)arxiv.org
Robust Bi-Tempered Logistic Loss Based on Bregman Divergences
3)google.github.io
Demo for Bi-Tempered Logistic Loss for Training Neural Nets with Noisy Data.

コメント