
1.Bi-Tempered Logistic Loss:ノイズの多いデータでニューラルネットをトレーニングするための損失関数(1/3)まとめ
・ノイズの多いデータにニューラルネットワークが対応する能力は損失関数に大きく依存する
・分類タスクで良く使われる標準的な損失関数はロジスティック損失だが2つの弱点を持つ
・大きなマージン問題は分類性能を劣化させ、小さなマージン問題は一般化パフォーマンスを低下させる
2.ロジスティック損失関数の弱点とは?
以下、ai.googleblog.comより「Bi-Tempered Logistic Loss for Training Neural Nets with Noisy Data」の意訳です。元記事の投稿は2019年8月26日、Ehsan AmidさんとRohan Anilさんによる投稿です。
機械学習(ML)アルゴリズムによって生成されるニューラルネットワークモデルの品質は、トレーニングデータの品質に直接依存します。しかし、現実世界のデータセットには通常、ある程度のノイズが含まれ、これはMLモデルの学習を難しくします。データセット内のノイズは、破損した例(猫の画像にレンズフレアが写り込むなど)から、データが収集されたときのラベルの誤った例(スパイダーマンの画像に「蜘蛛」と誤ったラベル付けがされるなど)まで、いくつかの形をとることがあります。
ノイズの多いトレーニングデータに対応できる処理能力は、トレーニングプロセスで使用される損失関数に大きく依存します。分類タスクの場合、トレーニング時に使用される標準的な損失関数はロジスティック損失です。ただし、この損失関数は、2つの不幸な特性のためにノイズの多いトレーニングサンプルを処理する能力が不十分です。
1.大きな外れ値が全体的な損失を支配する可能性があります
ロジスティック損失関数は外れ値に敏感です。これは、外れ値、例えば誤ってラベル付けされた例や特殊な事例などが決定境界から遠く離れていると、損失関数の値が制限なく増加するためです。
それゆえ、決定境界から遠く離れた場所にある1つの特殊事例が、最終的なモデルの決定境界に影響を与えてしまいます。
モデルは決定境界を補正する事で特殊事例を取り込む事を学習しようとし、これは、残りの一般的な事例に犠牲を強いたり、トレーニングプロセスにペナルティを科す可能性があります。
この「大きなマージン」ノイズの問題は、下図の大きなマージンノイズの例に示されています。
2.誤ったラベルが、決定境界を広げてしまう可能性があります
ニューラルネットワークが出力する値は、活性化値のベクトルです。これは、事例と決定境界の間のマージンが反映された値です。softmax伝達関数は、この活性化値を「サンプルがどのクラスに属するか?」の確率に変換します。ロジスティック損失が用いるこの伝達関数のテール部分(最大値もしくは最小値に近い「尾」の部分)は、指数関数的に急速に減衰するため、トレーニングプロセスは決定境界を誤ったラベルの付いた事例に近づけて、その小さなマージンを補正してしまう傾向があります。 その結果、ラベルのノイズ率が低い場合でも、ネットワークの一般化パフォーマンスは急速に低下します。(下図の小さなマージンノイズの例)
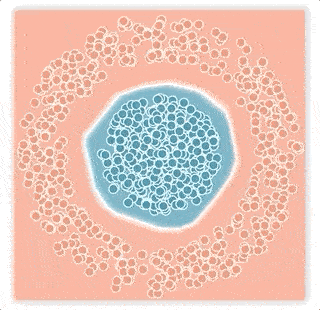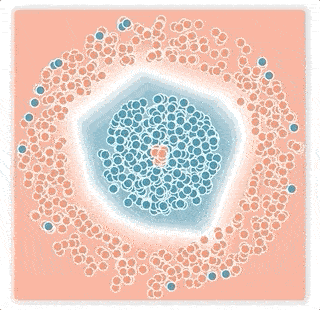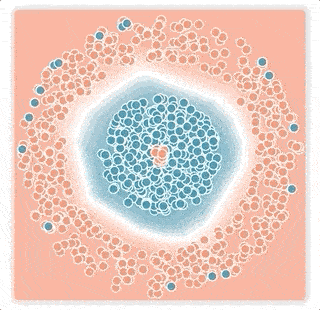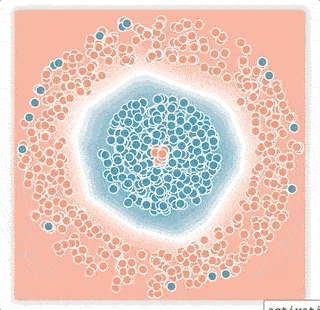
大きなマージンノイズの例
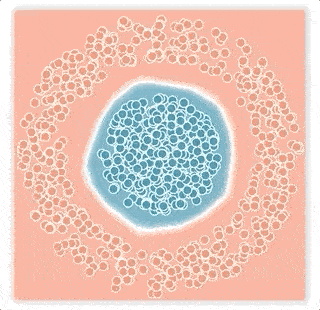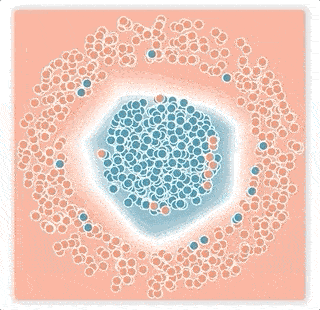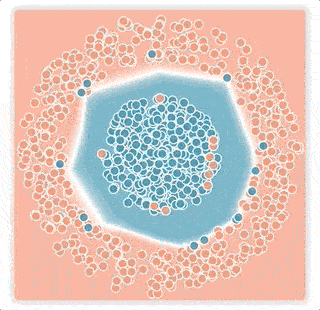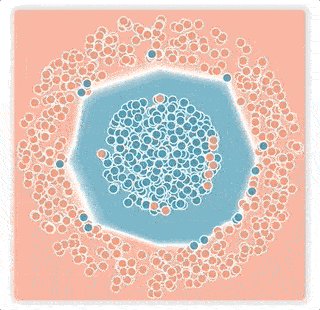
小さなマージンノイズの例
上の2層ニューラルネットワークは青とピンクの点を分類するように訓練されておりの分類境界を白線で視覚化しています。ニューラルネットワークはロジスティック損失を使い、ノイズの多い条件下でトレーニングしました。
上図:大きなマージンノイズの例
下図:小さなマージンノイズの例
3.Bi-Tempered Logistic Loss:ノイズの多いデータでニューラルネットをトレーニングするための損失関数(1/3)関連リンク
1)ai.googleblog.com
Bi-Tempered Logistic Loss for Training Neural Nets with Noisy Data
2)arxiv.org
Robust Bi-Tempered Logistic Loss Based on Bregman Divergences
3)google.github.io
Demo for Bi-Tempered Logistic Loss for Training Neural Nets with Noisy Data.


コメント