
1.音響的な手がかりと言語的な手がかりを使って発言者を特定する(2/3)まとめ
・従来のアプローチには、進歩を妨げるいくつかの制限があり改良版も全ての制限を回避はできていない
・今回新しく提案された手法は音響的な手がかりと言語的な手がかりをシームレスに結合
・更に発言者特定システムと音声認識を1つのシステムに結合し斬新でシンプルなモデルを開発
2.統合音声認識及び発言者特定システム
以下、ai.googleblog.comより「Joint Speech Recognition and Speaker Diarization via Sequence Transduction」の意訳です。元記事は2019年8月16日、Laurent El ShafeyさんとIzhak Shafranさんによる投稿です。
従来のアプローチには、進歩を妨げるいくつかの制限があります。 最初に、会話を1人の発言者の音声のみを含むデータに分割する必要があります。それができないと、embeddingsは発言者の特徴を正確に表現する事ができません。ただし、実際には、発言者変化検出アルゴリズムは不完全であり、分割されたデータは複数の発言者を含む可能性があります。
第二に、クラスタリング段階ではアルゴリズムの特性上、会話に参加している発言者の総数があらかじめ判明している必要があり、更に入力データの精度が悪いと非常に敏感に反応してしまいます。
第三に、システムは、「音声データの分割サイズ」と「発言者特定モデルの正確性」の間で非常に難しいトレードオフを行う必要があります。分割データのサイズが長ければ、それだけ発言者に関する情報が多くなるため、発言者特定モデルの正確性が向上します。
しかし、これは例えば、肯定なのか否定なのかを正確に追跡する必要がある医療診断の会話または経済的な取引の際の会話を処理する状況において、間投詞(AhやHmmなどの意志を表現する発声)の発言者を間違えてしまって、非常に高くつく結果をもたらす可能性があります。
最後に、従来の発言者特定システムには、多くの自然な会話で特に顕著な言語的な手がかりを活用するための簡単なメカニズムがありません。例えば、臨床会話で「どのくらいの頻度で薬を服用していますか」などの発話は、患者ではなく医療行為提供者によって発せられる可能性が高いです。同様に、「いつ宿題を提出すべきですか?」という発言は、教師ではなく学生によって発せられる可能性が最も高いです。言語的手がかりはまた、例えば質問文の後に発言者が交代する確率が高い事を示しています。
従来の発言者特定システムにはいくつかの例外があり、そのような例外の1つが最近のGoogle AIブログの投稿で紹介されました。その研究では、リカレントニューラルネットワーク(RNN)の隠れ層が発言者を追跡する事で、クラスタリング段階の弱点を回避しました。今回の投稿で紹介している研究は、異なるアプローチを採用しており、言語的な手がかりも取り入れています。
統合音声認識と発言者特定システム
音響的な手がかりと言語的な手がかりをシームレスに結合するだけでなく、発言者特定システムと音声認識を1つのシステムに結合する、斬新でシンプルなモデルを開発しました。 統合モデルは、同等の音声認識のみのシステムと比較して、応答パフォーマンスを大幅に低下させる事はありません。
私達の研究の重要な洞察は、RNN-Tアーキテクチャが音響による手がかりと言語による手がかりを統合するのに適している事を認識することでした。
RNN-Tモデルは、3つの異なるネットワークから構成されています。
(1)音響フレームを潜在表現にマッピングする転写ネットワーク(Transcription Networkまたはエンコーダー)
(2)先行するターゲットラベルを元に次のターゲットラベルを予測する予測ネットワーク(Prediction Network)
(3)(1)と(2)のネットワークの出力を結合し、そのタイムステップで、出力ラベルセットの確率分布を生成する結合ネットワーク(Joint Network)
アーキテクチャ(下図)にはフィードバックループがあり、以前に認識された単語を入力としてフィードバックする事が可能な事に注目してください。これによりRNN-Tモデルが質問の終わりなどの言語的手がかりを組み込むことができます。
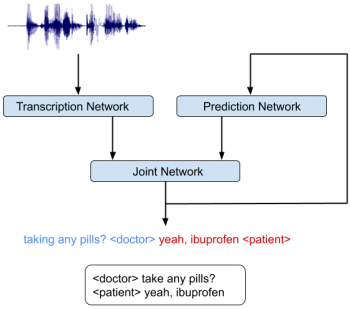
統合音声認識および発言者特定システム。システムは、誰がいつ何を話したかを共同で推測します。
3.音響的な手がかりと言語的な手がかりを使って発言者を特定する(2/3)関連リンク
1)ai.googleblog.com
Joint Speech Recognition and Speaker Diarization via Sequence Transduction
2)arxiv.org
Joint Speech Recognition and Speaker Diarization via Sequence Transduction

コメント