
1.EfficientNet-EdgeTPU:アクセラレータでの実行に最適化したニューラルネット(2/2)まとめ
・EfficientNetsが主に使用する「深さ方向に分離可能な構造」はアクセラレータ上では必ずしも有効ではない
・通常のCNNの方がアクセラレータを有効活用できるため高速になるケースも存在した
・上記特性も考慮してAutoMLでアーキテクチャー探索を実行し速度と精度にすぐれたモデルを構築できた
2.EfficientNet-EdgeTPUの性能
以下、ai.googleblog.comより「EfficientNet-EdgeTPU: Creating Accelerator-Optimized Neural Networks with AutoML」の意訳です。元記事は、2019年8月6日、Suyog GuptaさんとMingxing Tanさんによる投稿です。
探索スペースのデザイン
前述のアーキテクチャ探索を実行する場合、EfficientNetsが主に「深さ方向に分離可能(depthwise-separable)な畳み込み構造」に依存していることを考慮する必要があります。これは、畳み込み構造を因数分解して、パラメータの数と計算量を減らしているニューラルネットワーク構造の一種です。(下図)
ただし、特定の構成では、通常の畳み込みネットワークの方が、Edge TPUアーキテクチャをより効率的に利用可能なケースも存在します。計算量が非常に多くても、アクセラレータを有効活用できるため、より高速に実行できるケースがあるのです。
面倒ではありますが、異なるニューラルネットワーク構造を組み合わせて最適なニューラルネットワークを手動で構成することは可能です。しかし、アクセラレータでの実行に最適化するようなニューラルネットワーク構成をAutoMLで自動で探索する事は、よりスケーラブルなアプローチです。
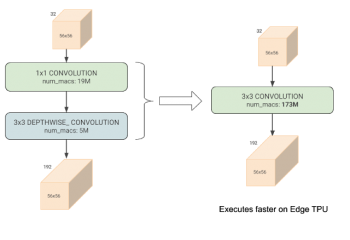
通常の3×3の畳み込みネットワーク(右図)は、深さ方向に分離可能な畳み込みネットワーク(左図)よりも多くの掛け算と足し算(mac:multiply-and-accumulate operations)を行いますが、特定の入力/出力形状では、ハードウェアを3倍有効活用できるため、Edge TPU上でより高速に実行されます。
更に、Swish Non-linearityやSqueeze-and-Excitationブロックなど、Edge TPUコンパイラーを完全にサポートするためには修正が必要になる特定の操作を検索スペースから削除すると、当然、Edge TPUハードウェアに容易に移植されるモデルになります。
しかし、これらの操作はモデルの品質をわずかに改善する傾向があるため、検索スペースからそれらを削除した後に、潜在的な品質の損失を補う可能性のある代替ネットワークアーキテクチャを発見するようにAutoMLに指示しました。
モデル性能
上記のニューラルアーキテクチャ検索(NAS:Neural Architecture Search)はベースラインモデルであるEfficientNet-EdgeTPU-Sを生成し、その後EfficientNetの複合スケーリング手法を使用してスケールアップして-Mおよび-Lモデルを生成しました。
複合スケーリングアプローチは、入力画像解像度スケーリング、ネットワーク幅スケーリング、および深度スケーリングの最適な組み合わせを選択して、より規模を拡大した、より正確なモデルを構築できます。-Mおよび-Lモデルは、下図に示すように、待ち時間が増加する代わりに、より高い精度を実現します。
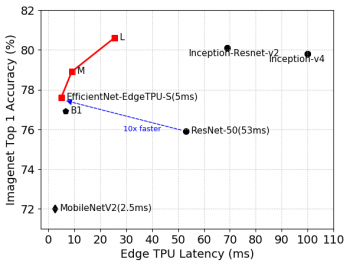
EfficientNet-EdgeTPU-S / M / Lモデルは、Edge TPUハードウェアのネットワークアーキテクチャ上の実行に最適化することにより、既存のEfficientNets(B1)、ResNet、およびInceptionよりも優れたレイテンシと精度を実現します。特に、私達のEfficientNet-EdgeTPU-Sはより高い精度を達成しながら、ResNet-50よりも10倍高速に動作します。
興味深いことに、NASで生成されたモデルは、ネットワークの初期層で非常に広範囲に通常の畳み込みを使用します。ネットワークの初期層は、アクセラレータで実行された時、深さ方向に分離可能な畳み込みの削減効果が通常の畳み込みよりも低い傾向がある部分です。
これは、汎用CPU上で実行するモデルを最適化する際に通常行われるトレードオフ(例えば、計算回数を減らす)が、ハードウェアアクセラレータにとって必ずしも最適ではないという事実を明確に強調しています。
また、これらのモデルは、難解な操作を使用しなくても高い精度を実現します。Inception-resnet-v2やResnet50などの他の画像分類モデルと比較すると、EfficientNet-EdgeTPUモデルはより正確であるだけでなく、Edge TPUでより高速に動作します。
今回の研究は、AutoMLを使用してアクセラレータ最適化モデルを構築する最初の実験です。AutoMLによるモデルのカスタマイズは、幅広いハードウェアアクセラレータに応用できるだけでなく、ニューラルネットワークに依存する様々な異なるアプリケーションにも拡張できます。
Cloud TPUでトレーニングしてEdge TPUに展開する
githubリポジトリでEfficientNet-EdgeTPUのトレーニングコードと事前トレーニング済みモデルをリリースしました。Tensorflowのトレーニング後量子化ツールを使用して、浮動小数点を使ったトレーニングモデルをEdge TPU互換の整数量子化モデルに変換しています。
これらのモデルの場合、トレーニング後の量子化は非常にうまく機能し、わずかな精度の損失しか生じません(約0.5%)。トレーニングチェックポイントから量子化モデルをエクスポートするためのスクリプトもgithubで公開しています。
Coralプラットフォームの更新については、Google Developers Blogの投稿を参照してください。完全な参考資料と詳細な手順については、CoralのWebサイトを参照してください。
謝辞
以下の皆さんに感謝します。Google BrainチームのQuoc Le, Hongkun Yu, Yunlu Li, Ruoming Pang, およびVijay Vasudevan。Google CoralチームのBo Wu、Vikram Tank、Ajay Nair。Google Edge TPUチームのHan Vanholder, Ravi Narayanaswami, John Joseph, Dong Hyuk Woo, Raksit Ashok, Jason Jong Kyu Park, Jack Liu, Mohammadali Ghodrat, Cao Gao, Berkin Akin, Liang-Yun Wang, Chirag Gandhi, そしてDongdong Li。
3.EfficientNet:AutoMLとモデルのスケーリングによりCNNの精度と効率を向上(2/2)関連リンク
1)ai.googleblog.com
EfficientNet: Improving Accuracy and Efficiency through AutoML and Model Scaling
2)github.com
EfficientNet-EdgeTPU
3)www.tensorflow.org
Post-training quantization
4)coral.withgoogle.com
Learn how to build AI products with Coral devices
5)developers.googleblog.com
Coral summer updates: Post-training quant support, TF Lite delegate, and new models!

コメント