
1.予測に機械学習を使用する際の落とし穴(2/3)まとめ
・誤った精度測定基準を選択すると実際には予測できないデータも高い精度で予測できているように見える
・時系列データは時間的に相関する傾向があり、直前の値を予測値とする事で見かけ上は高い精度で予測可能
・不正確に使用された場合、精度測定基準は大きな誤解を招く可能性があるので注意が必要
2.自己相関の落とし穴
以下、www.kdnuggets.comより「How (not) to use Machine Learning for time series forecasting: Avoiding the pitfalls」の意訳です。元記事は2019年5月、Vegard Flovikさんによる投稿です。
これは単に間違っています…。
モデルが予測した値から計算した誤差測定基準R2によれば、モデルは明らかに正確な予測をしています。しかし、これはまったく当てはまりません。モデルのパフォーマンスを評価するときに、誤った精度測定基準を選択すると誤解を招く可能性があることの単なる一例です。
今回の例は、説明のために、実際には予測できないデータを明示的に選択しました。
具体的には、私が「株価指数」と呼んだデータは、実際にはランダムウォークプロセスを使用して作られたグラフです。名前が示すように、ランダムウォークプロセスは完全にランダムな確率で動く動作です。
このため、行動を学習し、将来の結果を予測するために履歴データをトレーニングセットとして使用するという考えで予測する事は、単純に不可能なのです。
これを考えると、モデルが私達にそのような正確な予測を与えているように見えるのはどうしてでしょうか。 もう少し詳しく説明すると、それはすべて(誤った)精度測定基準の選択によるものです。
時間遅延予測と自己相関
時系列データは、その名前が示すように、時間的側面が重要であるという意味で他のタイプのデータとは異なります。好ましい側面としては、時系列データは私達が機械学習モデルを構築するときに使う事ができる追加の情報を与えてくれます。入力される特徴に有用な情報が含まれているだけでなく、入出力の時間経過による変化なども含まれています。
ただし、時間成分によって追加の情報が追加される一方で、他の多くの予測タスクと比較して時系列の問題を処理するのは困難です。
この具体例では、前回のデータに従って予測を行うLSTMネットワークを使用しました。ただし、下の図に示すように、モデルが出力した予測を少し拡大すると、モデルが実際に行っていることがわかってきます。
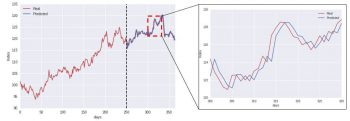
時系列データは時間的に相関する傾向があり、有意な自己相関を示します。今回のケースでは、時間「t + 1」における値が時間「t」における値に近い可能性が高いことを意味しています。
上の図に示すように、モデルが実際に行っているのは、時刻 “t + 1″の値を予測するときに、時刻 “t”の値を単にそのまま予測として使用することです。(しばしば永続モデル(persistence model)と呼ばれます)。
予測値と実際の値の相互相関をグラフにしてみましょう(下図)。横軸のタイムラグが-1dの箇所、つまり1日分だけずらした場所に明確な相関のピークが見られます。これは、モデルが単に過去の値を将来の予測として使用している事を示しています。
![]()
不正確に使用された場合、精度測定基準は大きな誤解を招く可能性があります
これは、値を直接予測する能力に関してモデルを評価する場合、平均エラー率やR2スコアなどの一般的な誤差測定基準が、どちらも高い予測精度を示すことを意味しています。ただし、前述のデータはランダムウォークプロセスで生成されているため、モデルは将来の結果を実際に予測することはできません。
これは、一般的な誤差測定基準を直接計算してモデルの予測力を単純に評価する事は非常な誤解を招く可能性があり、モデルの精度に過度に自信を持っていると騙されやすいという重要な事実を強調しています。
3.時系列予測に機械学習を使用する際の落とし穴(2/3)関連リンク
1)www.kdnuggets.com
How (not) to use Machine Learning for time series forecasting: Avoiding the pitfalls

コメント