
1.予測に機械学習を使用する際の落とし穴(3/3)まとめ
・誤った精度測定基準を選択すると実際には予測できないデータも高い精度で予測できているように見える
・時系列データは時間的に相関する傾向があり、直前の値を予測値とする事で見かけ上は高い精度で予測可能
・不正確に使用された場合、精度測定基準は大きな誤解を招く可能性があるので注意が必要
2.自己相関の罠を避ける
以下、www.kdnuggets.comより「How (not) to use Machine Learning for time series forecasting: Avoiding the pitfalls」の意訳です。元記事は2019年5月、Vegard Flovikさんによる投稿です。
定常性と差分時系列データ
定常性時系列(stationary time series)とは、平均、分散、自己相関などの統計的性質が時間の経過に関わらず一定になるように変換した時系列データの事です。
ほとんどの統計的予測方法は、時系列を定常性に変換する(すなわち「定常化(stationarized)」)事ができるという仮定に基づいています。そのような基本的な数学的変換の1つは、次の図に示すようにデータの時間差を取る事です。
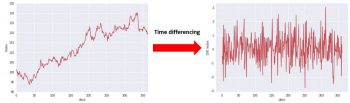
値を直接扱うのではなく、連続する各時系列データ値間の差を計算し、それを予測対象データとするのです。値自体ではなく、時系列データ間の差を予測するようにモデルを定義する事は、モデルの予測力を検証するはるかに強い検定方法です。
このようにすると、モデルは時系列データ持つ強い自己相関を単純に利用する事ができなくなります。時間「t」の値を「t + 1」の予測として使用することはできません。
このため、モデルのより良い検証が可能になり、トレーニングフェーズから何か有用なことを学習したかどうか、および履歴データを分析することで実際にモデルが将来の変化を予測できるかどうかがわかります。
時差データの予測モデル
直接データではなく時差データを予測できることは、モデルの予測力をより強く検証しているため、これを私たちのモデルで試してみましょう。
このテストの結果は下の図に示されており、実際の値(横軸)と予測した値(縦軸)の散布図が示されています。予測が完璧なら、対角線上に点が並ぶはずです。
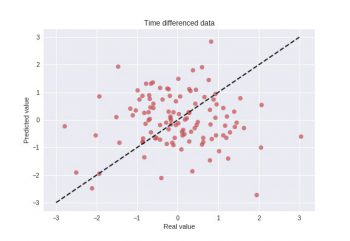
この図は、データが完全に確率的なランダムウォークプロセスを使用して生成されるため、モデルが過去のイベントに基づいて将来の変化を予測できないことを示しています。
確率論的プロセスの将来の結果を予測することは定義上不可能であり、誰かがこれが出来ると主張するならば、少し懐疑的に見るべきです…
あなたの時系列はランダムウォークですか?
あなたの時系列は実際には今回の例のようにランダムウォークであるかもしれません、そしてこれをチェックするいくつかの方法は以下の通りです:
(1)時系列が線形または同様のパターンで減衰する強い時間依存性(自己相関)を示している
(2)時系列が非定常形であり、定常形に変換しても、データ内に明確な学習可能な構造が示されない
(3)永続モデル(前のタイムステップでの観測を次のタイムステップで起こるものとして使用するモデル)が、最良の予測結果を提供する
この最後の点は、時系列予測にとって重要です。
永続モデルを使用した予測を基準とした時、その予測が大幅に改善できるかどうかはすぐにわかります。 それができないのなら、あなたはたぶんランダムウォークをしている(あるいはそれに近いランダムなデータを)予測しようとしている)のでしょう。
人間の心は様々な局面でパターンを探しだそうとします。私達は、ランダムウォークプロセスを予測するために精巧なモデルを開発することによって、自分自身をだまして時間を無駄にしないように用心しなければなりません。
まとめ
この記事を通して強調したい点は、正確性の観点からモデルの予測パフォーマンスを評価するときには非常に注意が必要だと言う事です。上記の例で示したように、将来の結果を予測することが定義上不可能である完全にランダムなプロセスであっても、正確な予測が出来ているかのように勘違いしてしまう可能性があります。
単純にモデルを定義し、いくつかの予測を行い、一般的な精度測定基準で精度を測定する事によって、優れたモデルを得て、それを本番業務に使いたくなるかもしれません。その一方で実際には、モデルには予測力がまったくないかもしれません。
時系列予測を使用していて、おそらく自分をデータサイエンティストと見なしている場合は、サイエンティストの側面にも重点を置くようにお願いします。
データが何を指し示しているのかに常に懐疑的になり、批判的な質問をするようにして、そして何らかの結論に素早く飛びつかないでください。 科学的方法は、他の種類の科学と同様にデータ科学にも適用されるべきです。
Vegard Flovikはリードデータサイエンストです。Axbit ASで機械学習と高度な分析を行っています。
3.時系列予測に機械学習を使用する際の落とし穴(3/3)関連リンク
1)www.kdnuggets.com
How (not) to use Machine Learning for time series forecasting: Avoiding the pitfalls

コメント