
1.カメラとモデルが動いている状況で奥行情報を予測(2/2)まとめ
・深度予測ネットワークへの入力は元映像、人をマスクした情報、視差から得られた深度マップ
・人間は物理的に一貫した形状と寸法を持つため内部的に事前学習させる事ができる
・これにより隠れたり欠けている領域を他のフレームの映像を使って補完する機能や動画のボケを実現
2.動いている人間は角測量が使えない状況で奥行を予測する方法
以下、ai.googleblog.comより「Moving Camera, Moving People: A Deep Learning Approach to Depth Prediction」の意訳です。元記事は2019年5月23日、Tali DekelさんとForrester Coleさんによる投稿です。
動画データを合成する代わりに、既存の映像データを教師として使用する事にしました。YouTubeビデオには、マネキンのように動かず様々な自然なポーズをしているモデルを、スマートフォンのカメラを動かして撮影しているマネキンチャレンジと言われるタイプの動画が存在します。
撮影風景内の物体は全て静止(カメラのみが動いています)しているため、マルチビューステレオ(MVS)のような三角測量ベースの手法を適用する事が可能でなり、風景内の人物を含む全体の正確な奥行、つまり深度情報を取得できます。
私達は、そのようなビデオを約2000動画集めました。それらの動画は、人々が様々な異なるグループ構成で自然なポーズをとっており、撮影風景も広範囲で現実世界の様々な場面にわたっていました。

カメラが風景を撮影している間、マネキンのように動かない人々。従来のMVSアルゴリズムを使用して奥行情報を推定可能です。この情報は、深度予測モデルのトレーニング中に教師として使用します。
動いている人の奥行情報を推測する
マネキンチャレンジをしている人々の動画は、動いているカメラと「凍り付いた」人々の奥行情報を教師データとして提供してくれましたが、私達の最終目標は動くカメラで動く人々を撮影している動画を扱う事です。そのギャップを埋めるためには、ネットワークに与える入力情報を複数組み合わせて構造化する必要があります。
考えられるアプローチは、ビデオの各フレームについて別々に深度を推測する事です。(すなわち、モデルへの入力は単一フレームとなります)。
ここまでに説明した取り組みで既に、従来の最先端の単一画像深度予測アプローチより改良が見込めますが、私達は複数のフレームからの情報を統合して考慮することによって結果をさらに改善する事に挑戦しました。
例えば、運動視差(motion parallax)、動かない物体を2つの異なる視点から見る事による相対的な動きは、奥行きを測定する強力なきっかけになります。
この情報を活用するために、私達は、入力フレームとビデオ内の別のフレームとの間の物体の動きの見え方を計算しました。これは2つのフレーム間の画素の変化で表現されます。
動画内の物体の動きは、物体の奥行きとカメラの相対位置の両方に依存します。しかしながら、カメラ位置は把握できているため、動きからカメラの依存関係を削除することができます。その結果、奥行情報を表現する初期の深度マップが作成できます。
この初期の深度マップは静的な状況に対してのみ有効です。初期の深度マップに人の形状を認識できるセグメンテーションネットワークを適用し、動いている人が写っている領域をマスクします。私達のニューラルネットワークへ入力は、RGB画像、動いている人をマスクした情報、視差から得られたマスク済み深度マップ、となります。
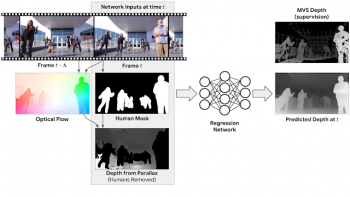
深度予測ネットワーク:モデルへの入力は、「RGB画像(フレーム t)」、「動いている人間をマスクした領域」、「人間が写っていない領域の初期深度」が含まれます。これらの情報は入力フレームと他のフレームとの間の運動視差(オプティカルフロー)から計算され、モデルはフレームtの完全深度マップを出力します。学習時の教師データは、MVSによって計算された深度マップによって提供されます。
深度予測ニューラルネットワークの役割は、動いている人間が写っている領域の深度情報を補完し、それ以外の領域の深度情報を洗練させる事です。
人間は物理的に一貫した形状と寸法であるため、ニューラルネットワークは多くの訓練事例を観察する事によって、内部的に事前学習する事ができます。一度訓練が完了すれば、私達のモデルはカメラと人間が自由に動き回る自然なビデオを扱うことができます。
以下は、私達のビデオに基づく深度予測モデルと従来の学習ベース手法とを比較した結果です。

カメラと人が同時に動いている動画と他の深度予測モデルの出力の比較。上段:学習ベースの単眼カメラを用いた奥行き予測(左:DORN、右:Chen et al)下段:学習ベースのステレオカメラを用いた予測(左:DeMoN、右:私達の結果)
深度マップを利用した3Dビデオ効果
作成した深度マップを使用して、さまざまな3D対応ビデオエフェクトを作成できます。そのような効果の一つは合成を使った焦点ボケ(訳注:synthetic defocus、Pixel2のポートレートモードなどでも使われている、被写体の周辺をボヤけさせる事によって被写体を目立たせる手法)です。以下は、私たちの深度マップを使って、普通に撮影されたビデオにボケを適用した例です。

私達の深度マップを使って生成されたビデオの焦点ボケ効果。ビデオはWind Walk Travel Videosの提供です。
私達の深度マップの他の考えられる用途は、単眼カメラで撮影されたビデオからステレオカメラで撮影されたビデオを生成する事、およびCGで作成した物体を動画内に挿入する事などが考えられます。
深度マップは、隠れたり欠けている領域を、他のフレームの映像を使って補完する機能も提供します。以下の例では、カメラを数秒毎に小刻みに揺れ動かす効果を合成しています。俳優の後ろの領域はビデオの他のフレームから取得した画素情報で補完しています。

謝辞
この記事で解説された研究は、Zhengqi Li、Tali Dekel、Forrester Cole、Richard Tucker、Noah Snavely、Ce Liu、Bill Freemanによって行われました。私達は貴重なフィードバックをくれたMiki Rubinsteinに感謝します。
3.カメラとモデルが動いている状況で奥行情報を予測(2/2)関連リンク
1)ai.googleblog.com
Moving Camera, Moving People: A Deep Learning Approach to Depth Prediction
2)arxiv.org
Learning the Depths of Moving People by Watching Frozen People


コメント