
1.Weak Supervision:機械学習のための新しいプログラミングパラダイム(2/4)まとめ
・古典的なAIであるエキスパートシステムは性能は高くなく脆弱ではあるが簡単に制御できる
・対照的に現在のディープラーニングは高い性能と柔軟性を持つが制御するのが難しい
・両者の性質を組み合わせたいとの発想からデータプログラミングアプローチのSnorkelが生まれた
2.Weak Supervisionのラベル付け関数とは?
以下、ai.stanford.eduより「Weak Supervision: A New Programming Paradigm for Machine Learning」の意訳です。元記事は2019年3月10日、Alex Ratnerさん, Paroma Varmaさん, Braden Hancockさん, Chris RéさんとHazy Labの皆さんによる投稿です。記事内に出てくるSnorkelは以前、紹介しました際に、ポテンシャルは感じていたのですが、それが持つ真の意味に気付いてませんでした。本記事を読んでいて思わずアッタマイー!と呟いてしまいました。ディープラーニングをコントロールする意図があったんですね。
AIに特定の領域の知識(ドメイン知識)を習得させる
歴史的な観点からは、AIを「プログラム」する(すなわち、人間が既に知っているドメイン知識を学ばせる)ことは新しいことではありません。今、この質問をする際の主な目新しさは、AIはかつてないほど強力になっており、解釈可能性と制御性の観点で「ブラックボックス」である事です。
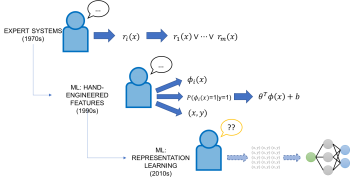
1970年代と1980年代には、AIはエキスパートシステムが中心でした。エキスパートシステムとは、ドメイン知識を持つエキスパートが手作業で作成した事実と規則に関するナレッジベースを推論エンジンと組み合わせて活用するシステムです。
1990年代に入って、MLは知識をAIシステムに統合するための手段として再出発しました。AIはラベル付きのトレーニングデータから強力で柔軟な方法で自動的に学習するようになりました。
古典的(非特徴表現学習)なMLアプローチは、一般的に、ドメイン知識を取り込む2つの方法を持っていました。
まず、これらのモデルは一般的に現代のモデルよりもはるかにシンプルな作りであったため、より少量の手書きデータでも十分であったということです。
次に、これらのモデルは手作業で設計した特徴表現に依存していました。これは、モデルが認識しているデータの基本的な特徴表現を、人間が直接エンコード、変更、および相互作用させる事が可能である事を意味します。しかしながら、特徴表現エンジニアリングはMLの専門家にとっては今でも、長い時間と職人芸が必用なタスクと一般的には考えられています。
ディープラーニングの時代になると、多くの領域や作業に渡って自動的に特徴表現を学習するというその優れた性質のおかげで、ディープニューラルネットワークは特徴表現エンジニアリングの必要性を大幅に低減しました。
ただし、大部分が完全なブラックボックスで動作原理がわかっていないため、平均的な開発者はほとんどディープラーニングをコントロールできません。精々、大規模なトレーニングセットにラベルを付けたり、ネットワークアーキテクチャを調整する程度です。
多くの意味で、ディープラーニングは昔のエキスパートシステムの脆弱ではあるが簡単に制御できる性質と極端に反対の性質を示してます。ディープラーニングは柔軟ですが制御するのが難しいのです。
これは私達をわずかに異なる角度から元の質問に導きます。
現代のディープラーニングモデルをプログラムするために、私たちはどのようにして私たちのドメイン知識またはタスクの専門知識を活用できますか? 古いルールベースのエキスパートシステムの直接制御可能な性質と最新のディープラーニングの柔軟性と能力を組み合わせる方法はありますか?
教師としてのプログラム:プログラミングによるMLの訓練
Snorkelは、MLと新しいタイプの相互作用を行う事をサポートし、その可能性を探るために私達が構築したシステムです。
Snorkelでは、手書きのトレーニングデータを使用しませんが、代わりにラベル付け関数(LFs:Labeling Functions)の作成、つまり、「ラベルなしデータの一部にラベルを付けるための簡単なプログラムの断片」を作成する事をユーザーに依頼します。
こうして作成された複数のラベル付け関数を使用して、MLモデルのトレーニングデータにラベルを付けることができるようになります。ラベル付け関数は単なるシンプルなプログラムの断片なので、様々なパターン、ヒューリスティックなデータ、外部データリソース、クラウドワーカーからのノイズの多いラベル、弱い分類器など、任意の信号を取り扱う事ができます。
そして、プログラムであるために、モジュール性、再利用性、デバッグ性のような良くできたプログラムが持つ全ての利点を享受する事が出来るのです。例えば、モデルの目標が変わった場合、ラベル付け関数を調整して素早く新しくラベル付けデータを作り直し、モデルを素早く適応させることができるのです!
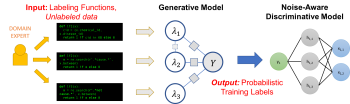
1つの問題は、もちろん、ラベル付け関数が重複したり矛盾する可能性があるノイズの多いラベルを生成し、理想的とは言えないトレーニングデータを出力してしまう事です。Snorkelでは、以下の3つのステップでデータプログラミングアプローチを適用し、これらのラベルのノイズを除去します。
(1)ラベル付け関数群をラベルなしデータに適用します。
(2)生成モデルを使用し、ラベル付きデータなしでラベル付け関数群の精度を学習させ、精度に応じて各ラベル付け関数の出力を重み付けします。(訳注:信頼度が高いラベル付け関数の出力が信頼度が低いラベル付け関数の出力より重視されるように重みを調整すると言う事)ラベル付け関数群の相関関係構造を自動的に学ぶことさえできます。
(3)生成モデルは一組の確率的訓練ラベルを出力します。これにより、強力で柔軟な識別モデル(ディープニューラルネットワークなど)を訓練する事が可能になり、且つ、これは、ラベリング関数が出力する単なるラベルを超えて一般化された訓練データです。
このラベル付け関数を用いてディープニューラルネットワークを訓練するパイプラインは、MLモデルを「プログラミング」するための単純で堅牢な、モデルにとらわれない柔軟なアプローチを提供していると見なすことができます!
ラベル付け関数
生体医学の文献から構造化データを抽出することは、私達の一番の動機となるアプリケーションの1つです。大量の有用な情報は、何百万という科学論文、密集した非構造化テキストに効率的に閉じ込められています。
私達の医療分野における共同研究者達(バイオコラボレーター)がそれらの資料を使って遺伝病の診断などを行うことができるように、機械学習を使用して全てを抽出したいと考えています。
科学文献から特定の化学物質と疾病の関係についての言及を抽出するというタスクを考えてください。このタスクのための十分に大きな(または任意の)ラベル付きトレーニングデータセットは存在しないかもしれません。
しかしながら、生体医学の分野には、収集された大量のオントロジー(概念同士の関係を図示したもの)や語彙目録、その他のリソースがあります。化学薬品のオントロジー、病名のオントロジー、様々なタイプの既知の化学的疾患関係のデータベースなどです。
私達はこれらを弱い教師として使うことができます。更に、私たちはバイオコラボレーターと共に、タスク特有の大まかに正しい範囲、正規表現パターン、経験則、そしてネガティブラベルの生成戦略を考え出すことができます。

3.Weak Supervision:機械学習のための新しいプログラミングパラダイム(2/4)関連リンク
1)ai.stanford.edu
Weak Supervision: A New Programming Paradigm for Machine Learning

コメント