
1.GANにおけるラベル付きデータの必要性の低減(1/2)まとめ
・Conditional GANはトレーニングにラべル付きデータを必要とする
・本論文ではGANをトレーニングする際に必要なラベル付きデータ量を減らす
・未ラベル付け画像を回転させCNNで回転角度を予測させる事から開始
2.ラベルを必要とする条件付きGANとは?
以下、ai.googleblog.comより「Reducing the Need for Labeled Data in Generative Adversarial Networks」の意訳です。元記事の投稿は2019年3月20日、Mario LučićさんとMarvin Ritterさんによる投稿です。
GANの背後にある主なアイデアは、2つのニューラルネットワークをトレーニングすることです。ジェネレータ(Generator:生成器)はデータ(画像など)を合成する方法を学習します。ディスクリミネータ(discriminator:識別器)はジェネレータによって合成されたデータと本当のデータを区別する方法を学習します。
このアプローチは、本物そっくりな自然画像の合成、画像圧縮の改善、データの拡張などに使用されています。

ImageNetを使ったトレーニングが進むにつれてジェネレータが生成するサンプルが変遷する様子。ジェネレータネットワークは、分類に基づいて調整されます(例えば、「ホオジロフクロウ」または「ゴールデンレトリーバー」)。
自然な画像合成を実現するために、Unconditional GAN(無条件GAN)とは異なり、Conditional GAN(条件付きGAN)はトレーニング中にラベル(例えば、車、犬など)を使用して、最も真に迫った画像を作成します。
ラベルにより作業が容易になり、大幅な改善につながりますが、このアプローチでは、現実には滅多に用意できないくらいの大量のラベル付きデータが必要になります。
論文、「High-Fidelity Image Generation With Fewer Labels」では、最先端の条件付きGANをトレーニングするために必要なラベル付きデータの量を減らすための新しいアプローチを提案します。
大規模GANの最近の進歩と組み合わせると、10倍少ないラベル量で最先端技術に匹敵する忠実度の高い自然画像の合成が可能になります。この研究に基づいて、現代のGANのトレーニングと評価に必要なすべてのコンポーネントを含むCompare GANライブラリーのメジャーアップデートもリリースしています。
半教師と自己教師による改善
条件付きGANでは、ジェネレータとディスクリミネータの両方が通常、クラスラベルに基づいて調整されます。この研究では、人間が作成した真のラベル(ground truth labels)を推論されたラベルに置き換えることを提案します。
ほとんどのデータにラベルがついていない大規模データセットに対して高品質のラベルを推論するために、2段階のアプローチを取ります。まず、データセットのラベルのない部分のみを使用して特徴表現を学びます。
特徴表現を学ぶために、我々は最近発表されたアプローチの形式で自己教師を利用します。ラベル付けされていない画像はランダムに回転され、畳み込みニューラルネットワークに回転角度を予測することを課します。
このアイディアは、モデルがこのタスクを成功させるためには主要なオブジェクトとその形状を認識できている必要があるという考えです。
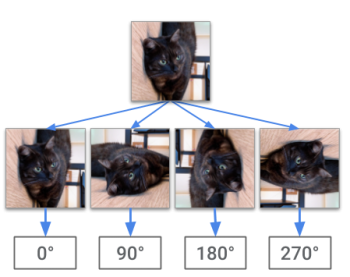
ラベル付けされていない画像はランダムに回転され、ネットワークは回転角度を予測することを課されます。この作業に成功するモデルは意味論的に意味のある画像特徴を捉えている必要があり、これはその後、他の画像タスクに使用することができます。
次に、訓練されたネットワークの中間層の1つの活性化パターンを入力された新しい特徴表現と見なし、元のデータセットのラベル付き部分を使用して、その入力のラベルを認識するように分類器を訓練します。
3.GANにおけるラベル付きデータの必要性の低減(1/2)関連リンク
1)ai.googleblog.com
Reducing the Need for Labeled Data in Generative Adversarial Networks
2)arxiv.org
High-Fidelity Image Generation With Fewer Labels
3)github.com
google/compare_gan
