
1.GPipe:大規模ニューラルネットワークを効率的に訓練するオープンソースライブラリ(2/3)まとめ
・GPipeを使うとCloud TPUv2で利用可能なパラメータを8200万から3億1800万に増やす事ができる
・TPUv3ではアクセラレータのメモリが16 GBに倍増しており更に多いパラメータが利用可能になる
・また、モデルを分割してアクセラレータに分散させる事により3.5倍の速度アップも見込める
2.GPipeにより可能になるパラメータの数
以下、ai.googleblog.comより「Introducing GPipe, an Open Source Library for Efficiently Training Large-scale Neural Network Models」のまとめです。元記事は2019年3月4日、Yanping Huangさんによる投稿です。
メモリと効率の最大化
GPipeはモデルパラメータのメモリ割り当てを最大化します。クラウドTPUv2で以下の実験を行いました。
それぞれのCloud TPUv2には8つのアクセラレータコアと64GBのメモリ(アクセラレータあたり8GB)があります。GPipeを使わない場合、1つのアクセラレータでトレーニングできる最大のモデルパラメータ数は、メモリ制限により最大8200万となります。
バックプロパゲーションの再計算とバッチ分割のおかげで、GPipeは中間アクティベーションメモリを6.26GBから3.46GBに減らし、1つのアクセラレータで3億1800万パラメータを扱う事を可能にしました。
また、予想通り、パイプライン並列処理では、最大モデルサイズは分割数に比例することもわかりました。GPipeを使用することで、AmoebaNetは、Cloud TPUv2の8つのアクセラレータに18億のパラメータを組み込むことができました。これは、GPipeを使用しない場合の25倍です。
効率性をテストするために、AmoebaNet-Dのモデルスループットに対するGPipeの効果を測定しました。トレーニングではモデルサイズに合わせるために少なくとも2つのアクセラレータが必要であるため、GPipeでパイプラインの並列化を行わず単純に2分割してスピードを測定しました。その結果、トレーニングではほぼ直線的にスピードアップする事がわかりました。
GPipeを使用してモデル2分割し、アクセラレータに4回分散させると、3.5倍のスピードアップが達成されました。このホワイトペーパーではすべての実験でCloud TPUv2を使用しましたが、現在利用可能なCloud TPUv3では、16個のアクセラレータコアと256 GB(アクセラレータあたり16 GB)が利用可能になるため更にパフォーマンスが向上します。
GPipeで、16個のアクセラレータ全てにモデルを分散させた場合、80億のパラメータを持つTransformer言語モデル(1024トークンセンテンス)で11倍のスピードアップを達成しました。
訳注:今まで私が把握してる限りで最もパラメータ数が多かったのはGPT-2の15億パラメータなのですが、GPT-2のパラメータ数はCloud TPUv2を最大限活用した範疇であり、TPUv3、もしくはTPUv2より高い能力を持つ可能性があるAmazonの機械学習演算用ハードウェアInferentiaがより広く利用可能になると、何もしなくても現在より優れたパフォーマンスを出せるようになる可能性が高いと言う事ですね。
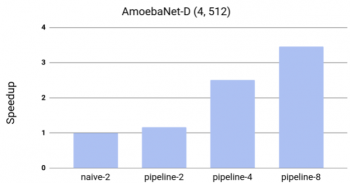
GPipeを使ったAmoebaNet-Dのスピードアップ。 このモデルは1つのアクセラレータには収まりませんでした。ベースラインnaive-2は、モデルが2つのパーティションに分割されている場合のネイティブパーティションアプローチのパフォーマンスです。 Pipeline-kは、モデルをk個のアクセラレータを使ってk個のパーティションに分割して実行したGPipeのパフォーマンスを表します。
GPipeは、ハイパーパラメータを変更することなく、さらに多くのアクセラレータを使用してトレーニングを拡張することもできます。 したがって、それをデータの並列処理と組み合わせて、さらに多くのアクセラレータを使用してニューラルネットワークのトレーニングを補完的に拡張することができます。
(GPipe:大規模ニューラルネットワークを効率的に訓練するオープンソースライブラリ(1/3)に続きます)
(GPipe:大規模ニューラルネットワークを効率的に訓練するオープンソースライブラリ(3/3)に続きます)
3.GPipe:大規模ニューラルネットワークを効率的に訓練するオープンソースライブラリ(2/3)関連リンク
1)ai.googleblog.com
Introducing GPipe, an Open Source Library for Efficiently Training Large-scale Neural Network Models
2)arxiv.org
GPipe: Efficient Training of Giant Neural Networks using Pipeline Parallelism
3)github.com
lingvo/lingvo/core/gpipe.py
