
1.MT-DNN:BERTを凌駕するMicrosoftの新しいNLPモデルまとめ
・MT-DNNはマイクロソフトが発表した新しい自然言語処理モデルでBERTを上回るスコアを出した
・2015年に提案したモデルに基づいて構築されマルチタスク学習と事前トレーニングを取り込んでいる
・MT-DNNによる特徴表現はBERTによる特徴表現よりも効率的に他の分野の作業に適応できる
2.MT-DNNとは?
以下、medium.comより「Microsoft’s New MT-DNN Outperforms Google BERT」の意訳です。元記事は2019年2月16日、Jessie Gengさんによる投稿です。BERTのarxiv.orgの投稿が2018年10月11日、本記事で紹介しているMT-DNNは2019年1月31日、BERTの衝撃が冷めやらぬ三カ月ちょっとでBERTを凌駕してしまったわけですが、GPT-2に話題をさらわれてしまった感もあります。
マルチタスク学習(MTL:Multi-Task Learning)と言語モデルの事前トレーニングは、最近の多くのNLU(自然言語理解)タスクに使用されているアプローチです。本日、マイクロソフトの研究者たちは、両方のアプローチを組み合わせたAIシステムの技術的詳細を発表しました。新しいマルチタスクディープニューラルネットワーク(MT-DNN)は、11のベンチマークNLPタスクのうち9つでGoogle BERTを上回った自然言語処理(NLP)モデルです。
マイクロソフトリサーチおよびマイクロソフトダイナミクス365の著者らは、彼らの論文「Multi Task Deep Neural Networks for Natural Language Understanding」において、複数のNLUタスクにわたるMT-DNN学習表現を示しています。著者らはこのモデルは、「大量のクロスタスクデータを活用するだけでなく、新しいタスクやドメインへの適応を支援するためのより一般的な表現につながる正則化効果の恩恵も受けます」と述べています。
MT-DNNは、Microsoftが2015年に提案したモデルに基づいて構築され、昨年Googleが提案した事前トレーニングされた双方向トランスフォーマ言語モデルであるBERTのネットワークアーキテクチャを統合しています。
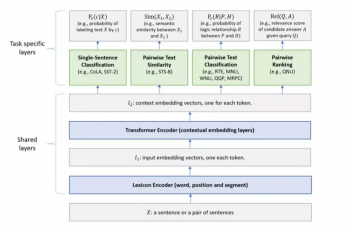
上の図に示されているように、ネットワークの低レベルレイヤ(つまりテキストエンコーディングレイヤ)はすべてのタスクで共有されていますが、最上位レイヤはタスク固有で、さまざまな種類のNLUタスクを組み合わせています。
BERTモデルと同様に、MT-DNNは2段階でトレーニングされます。事前トレーニングと微調整です。しかし、BERTとは異なり、MT-DNNは微調整フェーズに、複数のタスク固有のレイヤーと、マルチタスク学習を追加します。
MT-DNNはSNLI、SciTailを含む10のNLUタスクで新たに最高スコアを達成しました。9つのGLUEタスクのうち8つで、GLUEベンチマークを82.2%(絶対値で1.8%の改善)に引き上げました。
研究者はまた、SNLIとSciTailのデータセットを使用して、MT-DNNによって学習された特徴表現を使うと、事前訓練されたBERTによる特徴表現よりもかなり少ないドメイン内ラベルでドメイン適応が可能になることも実証しています。
詳細については、arXivの論文をご覧ください。 マイクロソフトはコードと事前訓練されたモデルをリリースする予定です。GLUEベンチマークリーダーボードはこちらです。
3.MT-DNN:BERTを凌駕するMicrosoftの新しいNLPモデルまとめ
1)medium.com
Microsoft’s New MT-DNN Outperforms Google BERT
2)arxiv.org
Multi-Task Deep Neural Networks for Natural Language Understanding
3)gluebenchmark.com
GLUE Benchmark leaderboard

コメント