
1.AlphaStar:StarCraftIIでプロプレーヤーに勝った人工知能(2/3)まとめ
・AlphaStarは単一の人工知能ではなく人工知能同士のリーグ戦を勝ちぬいた5選手から構成されていた
・当初は人間のリプレイから学習し次段階では人工知能同士でリーグ戦を最長で200年相当の期間行った
・AlphaStarリーグの進化の過程は人間が行っているオンライン対戦が洗練されていく過程に似ていた
2.AlphaStarリーグとは?
以下、deepmind.comより「AlphaStar: Mastering the Real-Time Strategy Game StarCraft II」の意訳です。元記事の投稿は2019年1月24日、The AlphaStar teamの皆さんによる執筆です。前記事はこちらです。続編記事はこちら。
どのようにしてAlphaStarを学習させたのか?
AlphaStarの振る舞いはディープニューラルネットワークによって生成されました。これは、生のゲームインターフェースから入力データ(ユニットとその状態のリスト)を受け取り、ゲーム内のアクションに繋がる一連の命令を出力します。
より具体的には、今回のニューラルネットワークアーキテクチャは、Transformerを主として(関係深層強化学習と似ています)、ディープLSTMコア、ポインターネットワークを備えた自己回帰ポリシーヘッド(auto-regressive policy head with a pointer network)、および集中ベースライン(centralised value baseline)を組み合わせたものです。
この高度なモデルは、長期シーケンスモデリングや、翻訳、言語モデリング、視覚的表現などの大きな出力スペースを含む、機械学習研究における他の多くの課題に役立つと考えています。
AlphaStarはまた、新しいマルチエージェント型学習アルゴリズムを使用しています。ニューラルネットワークは当初、強化学習によって訓練されました。Blizzard社によって発表されたツールであるs2client-protoにより匿名化された人間のゲームリプレイをダウンロードしてデータとして使いました。
これによりAlphaStarは、StarCraftラダートーナメントで人間のプレイヤーが使用していた基本的なミクロ戦略とマクロ戦略を模倣して学ぶことができました。この初期エージェントは、95%の確率で、StarCraftIIに最初から組み込まれている「Elite」レベルのAI(人間のプレーヤーで言えばほぼゴールドランク相当)を破りました。
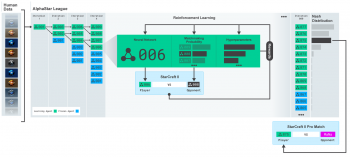
AlphaStarリーグの図。人工知能(エージェント)は、最初は人間のゲームのリプレイを使って訓練され、次にAlphaStarリーグ内の他のエージェント達と対戦をして訓練していきました。
繰り返し対戦を行う中で、元のエージェントから新しいエージェントが分岐され、元のエージェントは保持されます。そしてエージェントの強さに基づいて対戦相手を決定するシステム(MMR)とハイパーパラメータが、各エージェントの対戦における学習目標を定め、多様性を維持しながら難度を上げていきます。エージェントのパラメータは、対戦結果を元に強化学習によって更新されます。最終的に人間と対戦した5つのエージェントは、リーグ全体がナッシュ均衡(これ以上戦略を変更すると自分の総合勝率が落ちる状況に全員がなっている均衡状態)になった時に選ばれました。
これらはまた、マルチエージェント強化学習プロセスを生み出すために使用されました。人間がStarCraftのラダー対戦(人間がオンラインで行っている順位決定戦)で遊ぶ事によってStarCraftを上手になるように、人工知能のエージェント達 – 競争相手達 – はお互いに対戦しました。これがAlphaStarリーグです。
AlphaStarリーグでは既存の対戦エージェントから分岐させた、新しいエージェントが動的にリーグに追加され、元のエージェントはそのまま凍結されて保持されます。各エージェントは他のエージェントと対戦する事で互いにゲームから学びます。
この新しい形式のトレーニングは、人口ベースのマルチエージェント強化学習のアイデアをさらに取り入れ、膨大な戦略が取れるStarCraftで新たな戦略を常に模索しながら、各エージェントが最強の戦略に対してうまく機能し、且つ以前のエージェントとも戦い過去の戦略を忘れないようにします。
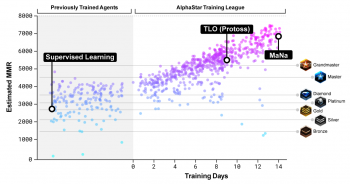
AlphaStarリーグの各エージェント達の強さの分布
横軸がトレーニング期間。左縦軸はMatching Rating Rating(MMR)、簡単に言えばエージェントのおおよその強さ。右軸はBlizzard社が開催している人間のオンラインリーグの各ランク。(訳注:つまり、10日以上訓練されたエージェントが集うAlphaStarリーグに放り込まれたらグランドマスターランクの人間でもほぼ勝てないようです)
AlphaStarリーグで対戦が繰り返され、新しいエージェントが生み出されると、以前の戦略を打ち負かすことができる新しい対抗戦略が出現します。いくつかの新しいエージェントは前の戦略を改良した戦略を実行する一方で、他のエージェントは全く新しいビルドオーダー(ユニットや建物を作る定石的な順番)、ユニット構成、およびマイクロ操作からなる劇的に新しい戦略を発見しました。
例えば、AlphaStarリーグの早い段階では、Photon Cannon(自動で敵を攻撃する砲台。本来は防御用施設だがこれを使って早期ラッシュする戦法がある)やDark Templar(見えないユニット。対抗できる施設やユニットが相手側にいなければ一方的に攻撃できる)による速攻のようなチーズな戦略(王道でない、安っぽい戦略の意味。対抗手段を知らない相手 or 奇襲でしか通用せず、失敗するとほぼ敗北が決定してしまうくらいリスキーであるため)が好まれました。
しかし、学習が進むにつれてこれらのリスキーな戦略は次第に捨てられ、他の戦略に繋がりました。例えば、より多くの作業用ユニットを作って基地を拡張し経済力を背景に強力な軍隊を作りあげたり、対戦相手の作業用ユニットを倒して相手の経済を混乱させるために2つのOracle(比較的早めに作れる対地攻撃可能な飛行機)で早期攻撃したりです。この進化のプロセスは、StarCraftがリリースされてから何年にもわたり、人間のプレイヤーが新しい戦略を発見し、以前に好まれていた戦略を打ち負かしてきた歴史と似ています。
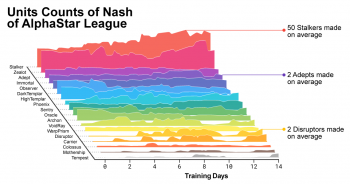
学習が進むにつれて、AlphaStarを作成しているエージェント達は、作成するユニットの数と編成を変えました。
AlphaStarリーグの多様性を促進するために、各エージェントは独自の学習目標を持っています。例えば、エージェントAがどのエージェントに勝つ事を目指すべきか、そしてエージェントのプレイスタイルを偏らせるために追加される内的なモチベーションです。
あるエージェントは、ある特定のエージェントを倒すという目的を持っているかもしれません。更に別のエージェントは特定のエージェントの派生型を全て倒す事を目標としているかもしれませんが、特定のゲームユニットをより多く作成する事でその目標を達成しようとします。これらの学習目標はトレーニング中に追加されます。
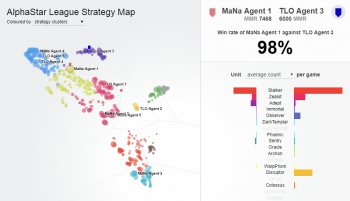
AlphaStarリーグのエージェント同士の勝率を示すインタラクティブな図。
TLO選手とMaNa選手と戦ったエージェントは、特にラベルが付けられています。(訳注:元記事は画像内をクリックするとそのエージェントのユニット構成等がわかるインタラクティブなグラフになっています。色は戦略によるクラスタリングで、MaNa選手が1戦目で人工知能の大体の戦略を把握したと思ったら5戦それぞれまるで違う戦略を使ってきた、とインタビューで答えてましたが、エージェント3とエージェント5は(ユニット構成はだいぶ違うけれども)同じ戦略だったのですね)
各エージェントのニューラルネットワークの重みは、競合する他のエージェントに対するゲーム結果を元に強化学習によって更新され、その個人的な学習目的を最適化します。重み更新ルールは、新しい効率的なポリシー外学習であるactor-critic強化学習と「experience replay」、「self-imitation learning」、「policy distillation」により行われました。
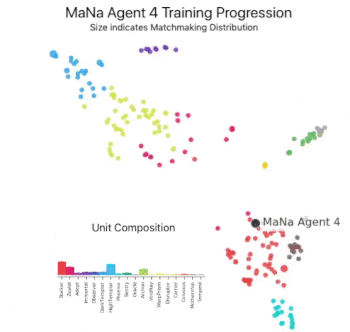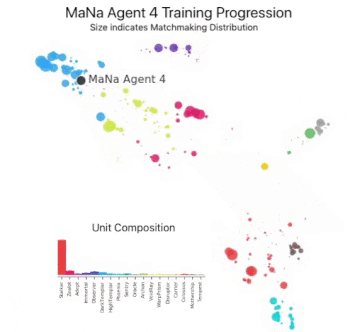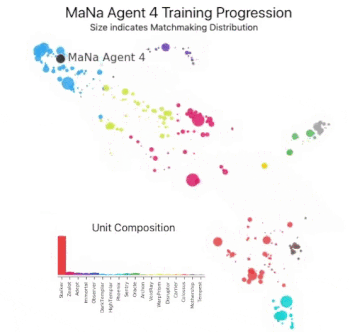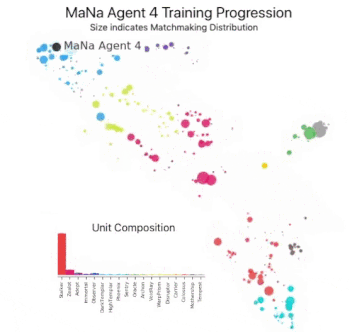
この図は、最終的にMaNa選手と対戦する事になった1人のエージェント(黒丸:Manaエージェント4)が、トレーニング中に自身の戦略と競合相手(色付きの丸)を進化させた過程を示しています。各点はAlphaStarリーグの選手を表します。点の位置はその戦略を表し、点のサイズはトレーニング中にMaNaエージェントの対戦相手として選択される頻度を表します。
AlphaStarをトレーニングするために、StarCraftIIを何千試合も同時並列に動かしてエージェントの集団が同時に対戦から学習可能な非常に大規模な分散型トレーニングシステムをGoogleのv3 TPUを使用して構築しました。AlphaStarリーグは、各エージェントに16 TPUを使用して14日間実行されました。トレーニング中、各エージェントは現実時間で最大200年間相当に換算されるStarCraftIIをプレイを経験しました。最終的に選ばれたAlphaStarエージェントは、AlphaStarリーグがNash均衡になった際の構成要素、つまり、発見された戦略の最も効果的な組み合わせで構成され、単一のデスクトップGPU上で実行されました。この研究の完全な技術的解説は、査読付きジャーナルへの掲載用に論文を準備中です。
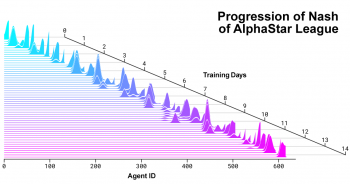
AlphaStarリーグが進展し、新しいエージェントが生み出され続ける中でのNash分布の推移
最新のエージェントが最も高く評価されており、過去の全てのエージェントと比較して継続的に進化してきた事を示しています。
(AlphaStar:StarCraftIIでプロプレーヤーに勝った人工知能(1/3)からの続きです。)
(AlphaStar:StarCraftIIでプロプレーヤーに勝った人工知能(3/3)に続きます)
3.AlphaStar:StarCraftIIでプロプレーヤーに勝った人工知能(2/3)関連リンク
1)deepmind.com
AlphaStar: Mastering the Real-Time Strategy Game StarCraft II

コメント